Global Bio x AI Community. A third place for scientists, product managers, computational biologists, engineers and academics working in AI & Software for Bio
A big day for multi-agent AI to accelerate biomedical discovery, hypothesis generation, designing experiments with proof points of new candidate drugs (cancer, fibrosis, macular degeneration, antimicrobial resistance, and more)
2 @Nature reports @GoogleDeepMind@FutureHouseSF
https://t.co/u1EYvJ05VJ
https://t.co/8DpAolom0F
Lots of news today. Don't have energy to write a hit tweet, so here's list
1. Our work on doing lab-in-the-loop with agents was published in Nature
2. We announced our first research partnership with a pharmaceutical company
3. We made new persistent code-writing agent
important to remember two things - 1) alphafold was built on decades of painstakingly collected xray crystallography, nmr, cryoEM data and 2) protein folding is *NOT* solved, alphafold still under-performs for non-canonical protein types that are important for therapeutic applications
I’ve wanted to do this for a decade.
But I never did - I refuse to give any company my DNA.
It is me.
So this week I sequenced my genome entirely at home. Literally on my kitchen table.
I never exposed my DNA sequence to the internet. Not at any point.
I used a MinION to do the sequencing (it’s smaller + weighs less than an iPhone).
I used open-source DNA models for the analysis (Evo2 and AlphaGenome) running locally on a DGX Spark and Mac Studio.
I traced mechanisms behind my family’s multigenerational autoimmune conditions that no clinician has been able to understand.
When I set out to do this I didn’t know if it would actually work. It does.
Your genome is the most private data you will ever have. You probably shouldn’t let it leave your house.
What happens when you put competing neural networks in a Petri Dish and start changing the rules while they adapt?
Last year we released Petri Dish NCA, where neural nets are the organisms that learn during simulation. Today we're releasing Digital Ecosystems: a browser-based platform for interactive artificial life research.
The setup: several small CNNs share a 2D grid, each seeing only a 3x3 neighborhood. No global plan. They compete for territory by attacking neighbours and defending against incoming attacks, learning via gradient descent online while the simulation runs.
What we didn't expect was the role of the learning itself. Gradient descent isn't just optimising each species' strategy. Instead, it acts to stabilize the whole system during simulation. Species that overextend get pushed back by the loss. Species that stagnate get nudged to grow. This means you can push parameters toward edge-of-chaos regimes: a zone characterised by emergent complexity. Letting the neural networks learn acts to hold the complex system together while you explore and interact.
The platform lets you steer all of this interactively. You can draw walls to create niches, erase parts of the system online, and tune 40+ system parameters to explore the most interesting configurations. We find it mesmerizing to watch species carve out territories and reorganise when you perturb them.
Everything runs client-side in your browser, no install needed.
Blog: https://t.co/qOuelxmd6l
Code: https://t.co/pz7ktDCRZS
Our 1st Assay into Protein language models at @BioMandrake is here!
PLMs have learned the grammar of evolution. They just haven't learned the physics. We go deeper into some experiments we did to shed light into nuances that Protein designers using these should care about.
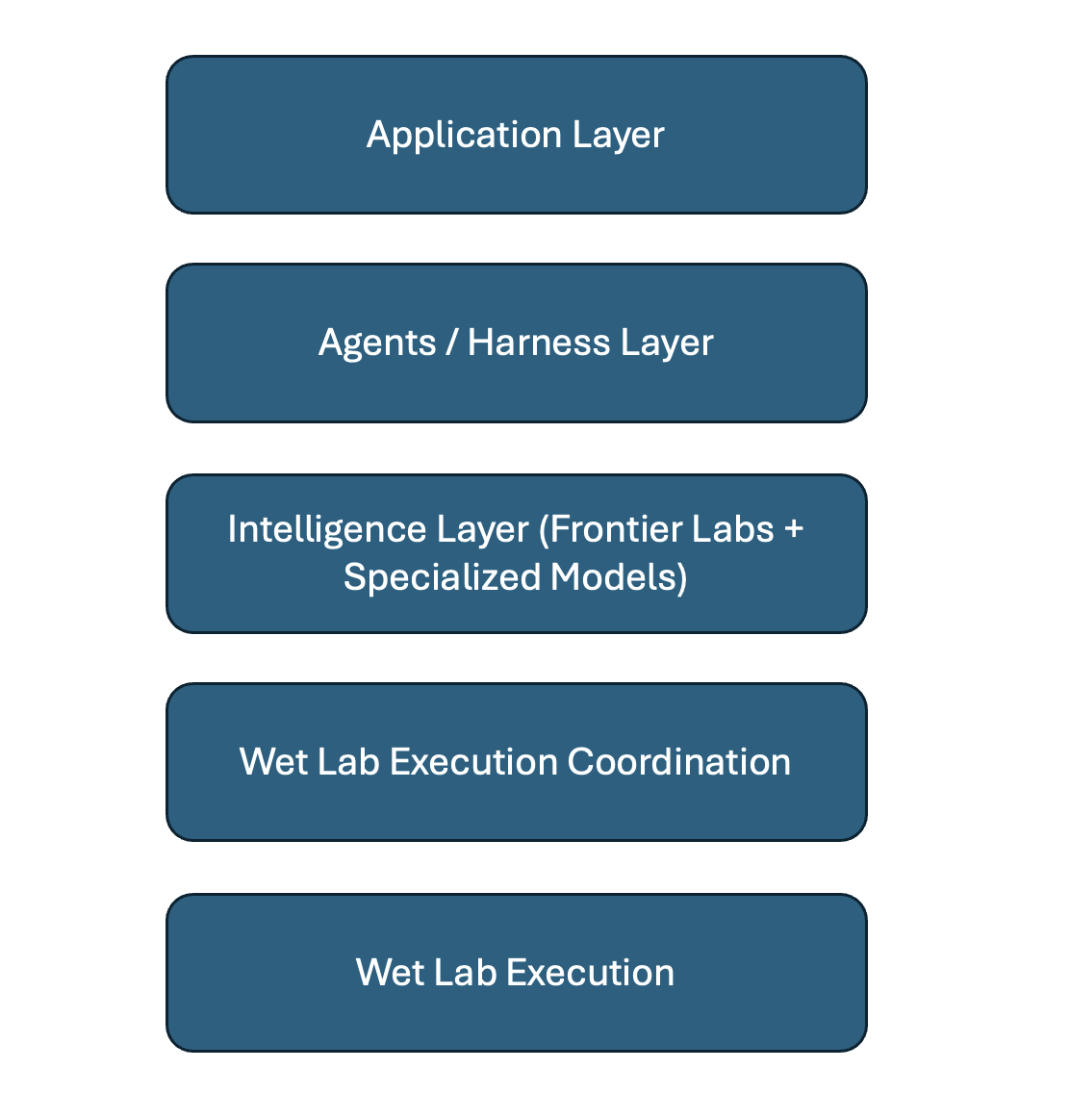
**the emerging AI native life science R&D stack**
the key question from mid 2025 til recently was whether frontier labs were actually serious about building products, capabilities, and orgs in AI x drug discovery or they were using it for marketing purposes in pursuit of ever larger rounds of funding.
fair q when in a few week stretch in 2025, sam altman, demis,and dario all said that one of the biggest benefits of AI for humanity would be huge acceleration of tx development ("dozens of drugs in a decade!") - cue exasperated groans from the trad bio section of the peanut gallery
a few cards have flipped in last few weeks:
OAI: released GPT-rosalind, a life science research model, first vertical specific GPT
Anthropic: acquired Coefficient bio to build biotech infra and a rumored bio model also dropping soon
as the frontier labs' strategy in the space has become clearer, so too has the *AI-native life science R&D stack*
a few comments on each layer of this 5 layer cake, starting with the middle:
Intelligence Layer (Frontier + Specialized Models) ~ Ant, OAI, GDP all in running; will proprietary data end up being *the* differentiator? and if so, who actually has access?
Wet Lab Coordination ~ speaking of proprietary data, can't get it at scale without some interface layer to the actual wet lab execution apparatus. in life sciences, that workflow is super outdated, phone calls, Excel, fax , PDFs, all just archaic. nearly no one has an API.
are the frontier labs interested in tackling the long tail of assays and CROs that would need to be wired into a real wet lab coordination layer? nothing to suggest they will right now — but they are hungry for capturing value up and down the chain
AWS Bio is first green shoots that another player will operate in this space but reviews on the ground have not been great - this may be the grittiest but also most unappreciated oppty in the stack
Wet Lab Execution ~ life sciences has a massive long tail of CROs, and given this is where the actual proprietary data gets generated, so this layer can be a genuinely differentiating factor
the interesting topic to watch: are any CROs going to become AI-native and start moving *up* the stack — doing wet lab coordination themselves, or perhaps even becoming preferred data providers to frontier labs?
Early movers like Gingko and Adaptyv are making some noise, but this has to be a topic that the forward-thinking folks running AI strategy at Thermo, Wuxi, and others are thinking about
Agents / Harness Layer ~ sitting on top of intelligence layer, lots of new startups have jumped into this space trying to coordinate models across life sciences specific workflows
big risk looming over all of them is whether frontier labs will simply subsume this into their own product roadmap. Anthropic x Coefficient Bio is an ominous signal (but maybe $ 400M acqui-hire in 12 mo is an outcome that everyone involved is ok with)
Application Layer ~ Benchling is the big gorilla here but if "attention is all you need" is *truly* all you need, the UX / UI with scientist layer becomes critically important, and potentially the most interesting place for a shake-up
frontier labs could still move in. and new form factors could emerge enabling new startups. physical AI could change the whole workflow
additionally is a notebook entry in a digital ELN even the right atomic unit of work in an AI-native workflow?
finally, stepping outside the stack, the looming question that no one has fully answered yet - these are all *infrastructure* plays. what will the truly AI-native therapeutics company actually look like? the actual value creation that comes out of this stack?
how will those AI-native biotechs look different in shape, value creation profile, and capital intensity compared to the biotechs we know today?
stay tuned.
📜 New paper with @mmbronstein: most data needed for AI4Science breakthroughs doesn't exist yet. And it won't - unless we fundamentally rethink data generation. Scaling up isn't enough. We need to stop generating data for humans and start generating for black-box models. We need black-box data 🤖 - 🧵https://t.co/Za0l1H14c7
🚀AI now has its own infinite self-learning lab!🔥
Science is learning from itself — overnight! ☀️🌛
❌No hand-coded protocols
✅Pure emergent intelligence exploding!
LabOS - LabWorld powers AI4Science.
Manual biology is over! 🎉
We built it to free brilliant minds — AI evolves autonomously through RL.
A true revolution! Welcome to biology’s new era! 👏
🔗 https://t.co/JXq4wOQe2C
What’s the first experiment you want it to run? Drop ideas below! 👇
FutureHouse postdoctoral fellow Chenghao Liu and team introduced the best model for de novo enzyme design this week. The fact that it can generate enzymes in a single shot that beat 14 rounds of directed evolution is insane. Congratulations all, this goes way beyond what I thought was possible…
On creating 'new knobs of control' in biology
https://t.co/JSboEI8zTb
a 5,000~ word essay on the brave new future of increasingly strange therapeutic modalities
Over the next week, I’ll be in the US presenting some of the exciting work the Boltz team has been doing, with stops in Boston, San Diego, and New York! 🧬
The bitter lesson strikes biology—again.
The current SOTA virtual cell uses a 7-term loss function and injects 6 knowledge sources into a bespoke architecture.
We trained a Transformer on free public data. With a chocolate pudding ranking method.
We beat SOTA. But what our virtual cell learned next will SHOCK you🧵
We're grateful to @FoundationOAI for their investment in us and others in the Alzheimer's community. AI will be essential for understanding complex diseases and Arc is working to map the full network of causal factors to pinpoint nodes for intervention: https://t.co/6wDjxrYcol
What if AI could invent enzymes that nature hasn’t seen? 👩🔬🧑🔬
Introducing 🪩 DISCO: Diffusion for Sequence-structure CO-design
14 rounds of directed evolution and over a year of wet lab work. That's what it took to engineer an enzyme for selective C(sp³)–H insertion, one of the most challenging transformations in organic chemistry.
DISCO surpasses this with a single plate. No pre-specified catalytic residues, no template, no theozyme, no inverse folding, just joint diffusion over protein sequence and structure.
📝 Blog: https://t.co/j9Za0JigfO
📄 Paper: https://t.co/ficrYNBBrM
💻 Code: https://t.co/p81sSwoaPH