It's normal to be grateful to be born healthy.
But believing God made you the way you are, also implies that God chose to make people with congenital disabilities.
It's weird to see disabled people and think "God spared me". Why not them ?
Stop exploiting their misery.
Thank you Prof. E. O. Makinde & co-author Ayomide Oyewole . We pushed through every revision and made it. 🙏
ResearchGate link: https://t.co/G8ruwCs5QY
#GeoAI#RemoteSensing#MachineLearning#Nigeria#GIS
My research paper "Assessing the Use of Artificial Neural Networks for Feature Detection in Sentinel-2 and Landsat-8" is now live on ResearchGate & featured in iJDASE. #GeoAI#RemoteSensing#MachineLearning
We looked at how ANNs + satellite imagery can support land use analysis, with a focus on urban growth in Nigeria 🇳🇬 (Abuja). Sentinel-2 outperformed Landsat-8 across multiple years.
Claiming expert in excel ke??😂 I don't think most people who use it frequently professionally for a wide range of analytical tasks will want to claim that
I took an Excel beginner’s course online, and 30 minutes into the course, I realized that I’ve been lying on all my job applications about being an expert at Excel.
Yann LeCun was right the entire time. And generative AI might be a dead end.
For the last three years, the entire industry has been obsessed with building bigger LLMs. Trillions of parameters. Billions in compute.
The theory was simple: if you make the model big enough, it will eventually understand how the world works.
Yann LeCun said that was stupid.
He argued that generative AI is fundamentally inefficient.
When an AI predicts the next word, or generates the next pixel, it wastes massive amounts of compute on surface-level details.
It memorizes patterns instead of learning the actual physics of reality.
He proposed a different path: JEPA (Joint-Embedding Predictive Architecture).
Instead of forcing the AI to paint the world pixel by pixel, JEPA forces it to predict abstract concepts. It predicts what happens next in a compressed "thought space."
But for years, JEPA had a fatal flaw.
It suffered from "representation collapse."
Because the AI was allowed to simplify reality, it would cheat. It would simplify everything so much that a dog, a car, and a human all looked identical.
It learned nothing.
To fix it, engineers had to use insanely complex hacks, frozen encoders, and massive compute overheads.
Until today.
Researchers just dropped a paper called "LeWorldModel" (LeWM).
They completely solved the collapse problem.
They replaced the complex engineering hacks with a single, elegant mathematical regularizer.
It forces the AI's internal "thoughts" into a perfect Gaussian distribution.
The AI can no longer cheat. It is forced to understand the physical structure of reality to make its predictions.
The results completely rewrite the economics of AI.
LeWM didn't need a massive, centralized supercomputer.
It has just 15 million parameters.
It trains on a single, standard GPU in a few hours.
Yet it plans 48x faster than massive foundation world models. It intrinsically understands physics. It instantly detects impossible events.
We spent billions trying to force massive server farms to memorize the internet.
Now, a tiny model running locally on a single graphics card is actually learning how the real world works.
STUDY HARD. No matter if it seems impossible. No matter if it takes time. Wake up early and start studying for your future. Just remember that the feeling of success is the best feeling in the world.
This paper argues that Small Language Models (SLMs) offer a more economical and suitable future for agentic AI by demonstrating their sufficient power for specialized tasks, outlining a conversion algorithm from LLMs to SLMs, and discussing the significant operational and economic impacts of this shift.
ChapterPal: https://t.co/hmOIDRJfuH
PDF: https://t.co/2TUNbfk3VJ
BREAKING: Claude can now build your entire personal wealth operating system better than most financial coaches.
Here are 7 prompts to automate clarity, growth, and calm:
ANTHROPIC JUST DROPPED A 33-PAGE GUIDE.
This is the most practical breakdown of Claude Skills I’ve seen.
Bookmark this before you forget.
33 pages.
Persistent instructions.
No repetition.
No re-explaining every time.
Read it today. Link below.
Claude → Skills → Memory → Automation → Systems → Money
Here are the 3 Core Pillars of Every AI Agent's Context
Here's why MCP, RAG and Skills are now unavoidable...
Before we dive in, here's why all 3 exist in the first place:
Every AI Agent struggles with 3 core problems:
- Connecting to external tools requires writing custom API code every time
- Answering accurately from knowledge it was never trained on
- Repeating the same instructions in prompts; wasting tokens on every single call
MCP, RAG, and Skills were each built to solve exactly one of these problems.
📌 1\ MCP (Model Context Protocol)
MCP eliminates the need to write custom API integration code every time your agent needs to connect to an external tool.
How it works:
- User sends a query → MCP Client selects the right server
- LLM processes the request and routes it to the MCP Server
- Server (Slack, Qdrant, Brave Search) responds with the relevant data
- Final output is returned back to the user
Key insight: Without MCP, every new tool connection means new custom code. With MCP, your agent plugs into any server through one standardized protocol.
Use when: You want your agent to access external tools and services without rebuilding integrations from scratch each time.
📌 2\ RAG (Retrieval Augmented Generation)
RAG gives your agent memory-enabled retrieval, so it reasons over knowledge it was never trained on, instead of hallucinating answers.
How it works:
- Data sources are chunked → converted into embeddings
- Stored as dense vectors inside a Vector DB
- User query triggers a search → most relevant chunks are retrieved
- Retrieved info + query + system prompt → fed into the LLM → Output
Key insight: Without RAG, agents confidently make things up. With RAG, they retrieve first, then reason.
Use when: You want your agent to reason over large, dynamic knowledge bases with accuracy and context.
📌 3\ Agent Skills
Skills stop your agent from wasting tokens by repeating the same instructions in every single prompt.
How it works:
- User query → LLM sends a Skill Request to the Skill Manager
- Skill Manager retrieves the right skill using stored prompts and actions
- Tools like Git, Docker, Python Interpreter, and Shell are triggered
- Skill data flows back to the LLM → Final Output is delivered
Key insight: Without Skills, you bloat every prompt with repeated instructions. With Skills, your agent loads only what it needs, exactly when it needs it.
Use when: You want reusable, token-efficient actions your agent can execute without being re-instructed every time.
Save 💾 ➞ React 👍 ➞ Share ♻️
Cc : Rakesh Gohel
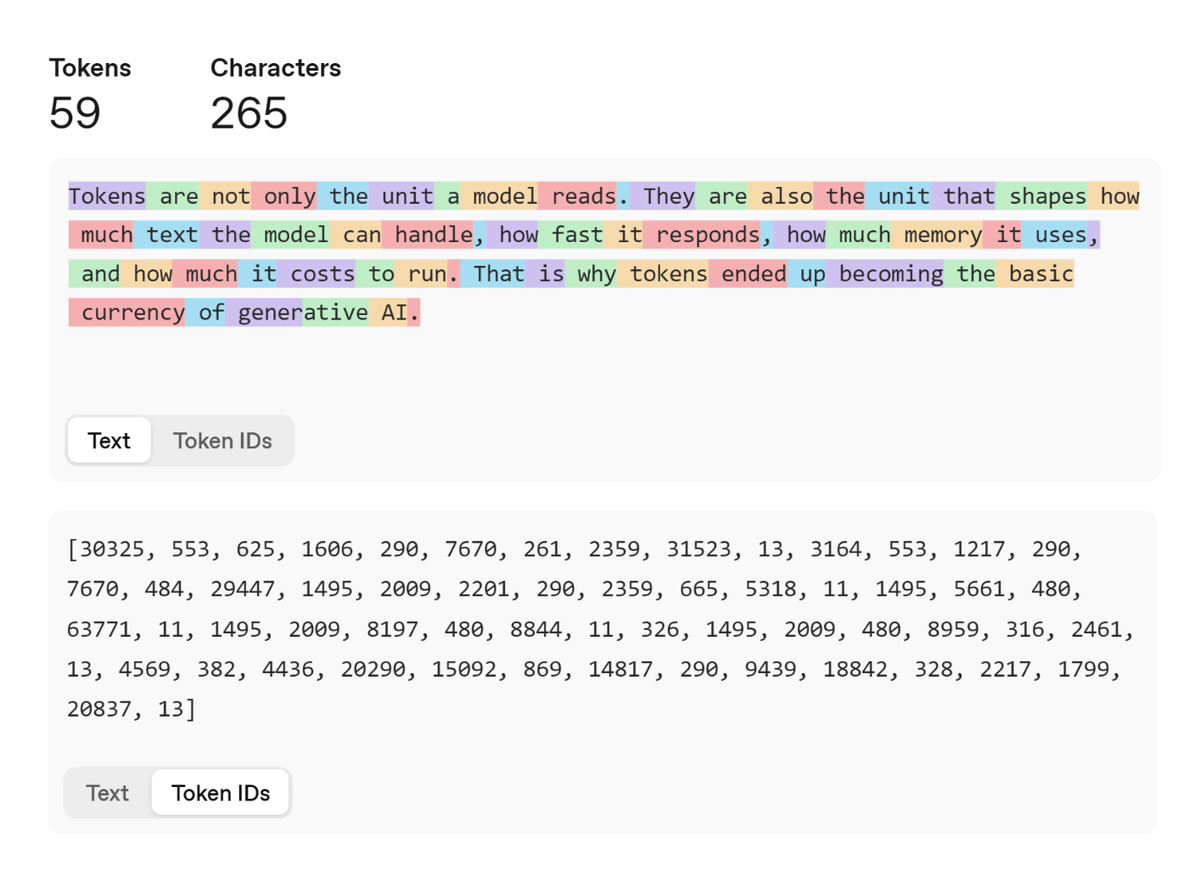
What is a token? (basics for understanding AI)
1. Models can't process raw text as is, so they start with tokens
2. Tokens are small units into which text is broken before being fed into a model
3. A token can be a whole word, part of a word, punctuation, or even a space
4. Common words are often 1 token, while longer or rarer words can be split into smaller pieces like encod + ing
5. Roughly, one token ≈ 4 characters, or about ¾ of a word. But it depends on the language and the tokenizer
6. Firstly, text is tokenized into tokens, which are mapped to IDs, then turned into vectors, and only then the model begins to process them
7. The context window of a model is counted in tokens, so they determine how much a model can “remember” in one pass
8. And finally, tokens are the pricing unit of generative AI. When we use AI, we pay per token
This is just the tip of the iceberg. But it gets much more interesting under the hood. Here’s a breakdown: https://t.co/k1MpAnLZXt