Lots of people asked how I used Fable to edit its own launch video so I made a video about that!
TLDR it wrote a lot of code & tool calls to use transcription services, ffmpeg, do colorgrading, use the figma mcp, make remotion UI and render it.
I didn't touch a video editor.
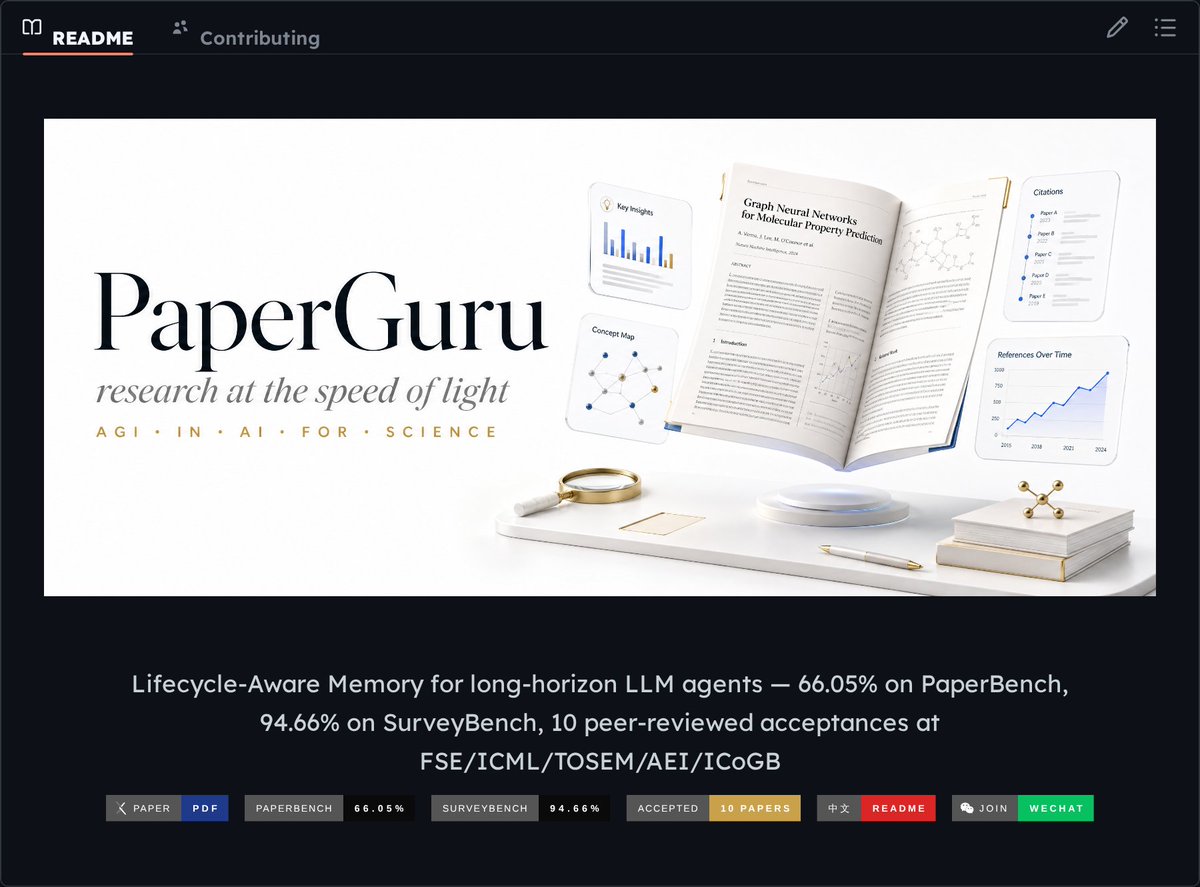
PaperGuru is the first memory primitive designed for long-horizon LLM agents, formalized as Lifecycle-Aware Memory (LAM) with four axioms.
- 66.05% on PaperBench, beating the best published baseline by 30.21%
- 94.66% content score on SurveyBench, +14.06% over prior work
- 10 peer-reviewed paper acceptances across FSE 2026, ICML 2026, TOSEM, AEI, and ICoGB
- Single algorithmic mechanism satisfying versioned content, multi-hop relevance, bounded query cost, and provenance-grounded composition
We talk a lot about how important it is to set up self-verification loops. Especially in the age of powerful models that can run for long periods of time, self-verification is a key ingredient that enables the model to run for much longer, delivering a result that is closer to what you intended, so you can do more without having to constantly check in on Claude as it works.
@delba_oliveira gives a great breakdown of what that looks like and why it matters
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
Claude Code's first demo got two Slack reactions.
One year after GA, @bcherny and @_catwu look back: verification best practices, why we built auto mode, routines and loops, and what's next.
https://t.co/yEa3cmCrg4
Just landed nested subagent support in Claude Code
Starting to experiment more with agents kicking off agents as a way to better manage context. Capped at depth=5 to start, going out in today’s release.
Lmk what you think!
Progressive disclosure in Skills doesn't get enough attention, and it's probably one of the most powerful patterns for documenting large agent processes
Script execution and file references are extremely powerful, especially now that LLM costs keep climbing
Token optimization is becoming a science. If you want to get serious with agentic systems, you need to prioritize it
3 stages to understand how it works and start using it in your Skills:
Stage 1 - Startup: Claude scans all skills, loads only the YAML frontmatter. ~60 tokens per skill. The agent knows what it CAN do, not HOW
Stage 2 - Task match: User request triggers intent recognition. Only the matching SKILL.md body loads. ~1,500-2,000 tokens, everything else stays on disk, zero context cost
Stage 3 - Deep execution: Reference files and scripts load on demand. Scripts run without their source ever hitting the context window
The math: 8 skills, 70K tokens of knowledge, ~500 tokens at startup
That ratio is why this pattern matters
New course on serving LLMs efficiently -- how do you serve models to many concurrent users at low latency and reasonable cost? This short course is built with @RedHat and taught by @cedricclyburn.
Efficient LLM serving requires efficient memory management. A 70B-parameter model takes ~140 GB just to load the weights. On top of that, every active request needs its own chunk of GPU memory, the KV cache, to store the token context it has built up so far. In this course, you'll learn to reduce a model's memory footprint with quantization and serve it using vLLM, which handles many concurrent requests efficiently through smart memory management.
Skills you'll gain:
- Quantize a model and measure the accuracy tradeoff
- Serve a model with vLLM and watch it handle concurrent requests efficiently
- Benchmark your deployment and make informed tradeoffs between speed, cost, and accuracy
Join and learn to serve LLMs efficiently:
https://t.co/x04xMbFlkO
An app can be a home-cooked meal (2020)
personal software was a bit early in 2020 but in 2026, it really can be as personal as a home cooked meal, or a handwritten letter
https://t.co/vQLa9wxUzq
Hermes won. They just dropped their desktop app and it's excellent
It's now the best way to use AI agents on your computer
In this video I cover how to set it up, how to use it, and go through EVERY feature in the app
Bye bye Telegram
Interpreting law is one of the oldest jobs in the world. @MaxJunestrand, co-founder and CEO of @WeAreLegora, is bringing it into its next era with Claude.
His bet: every new model release raises the tide, and Legora is building the boats for everyone else.
We’ve added a CLI for Claude Platform to make every API endpoint runnable from your terminal.
Call the Messages API, stand up Claude Managed Agents, pipe results straight into your shell.
The ant CLI is well understood by coding agents (Claude Code) using the claude-api skill.
If this prompt feels well written to you, it's because Suzanne is a writer in her little spare time!
You can read her short story, Mall of America here: https://t.co/uYY8VlPIUt
It's one of my favorite short stories about the human condition that happens to involve AI.
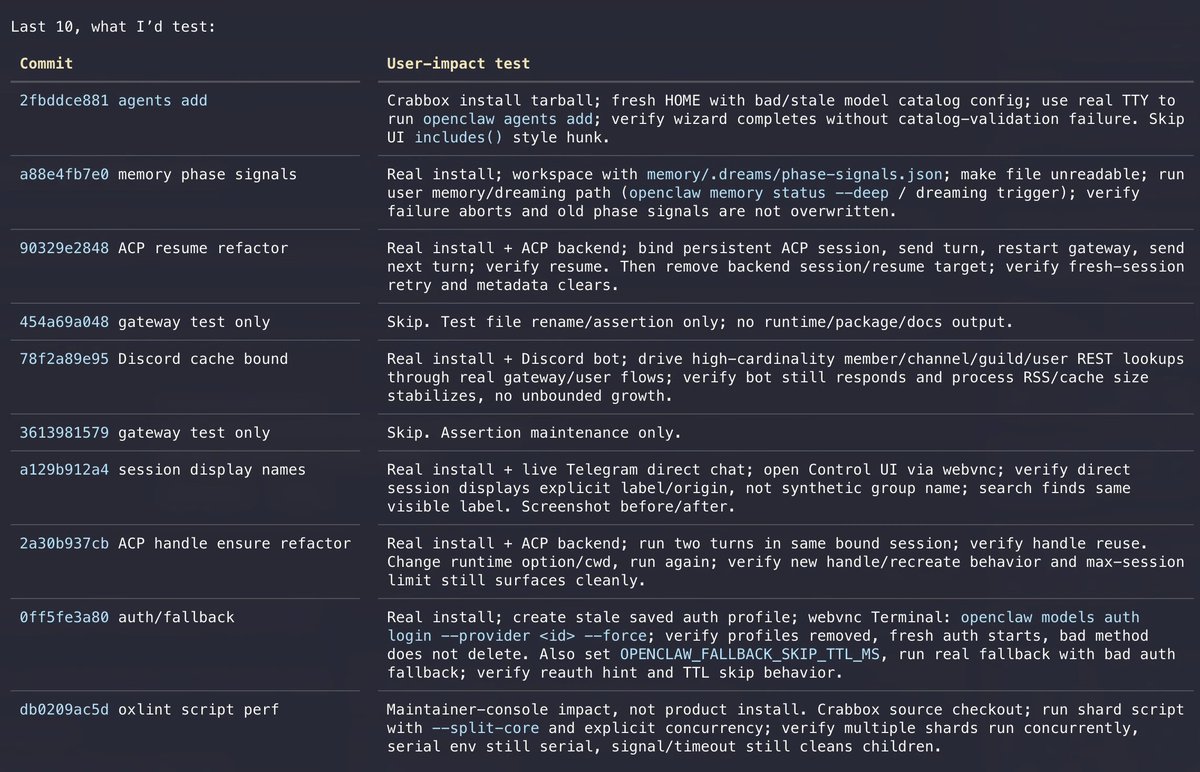
Been teaching codex to be my QA assistant. For every commit it creates a user-test scenario and uses webVNC (crabbox), computer/browser use (peekaboo/mcporter) to test OpenClaw like a user/QA person would.
This runs in the background and opens PRs with fixes.
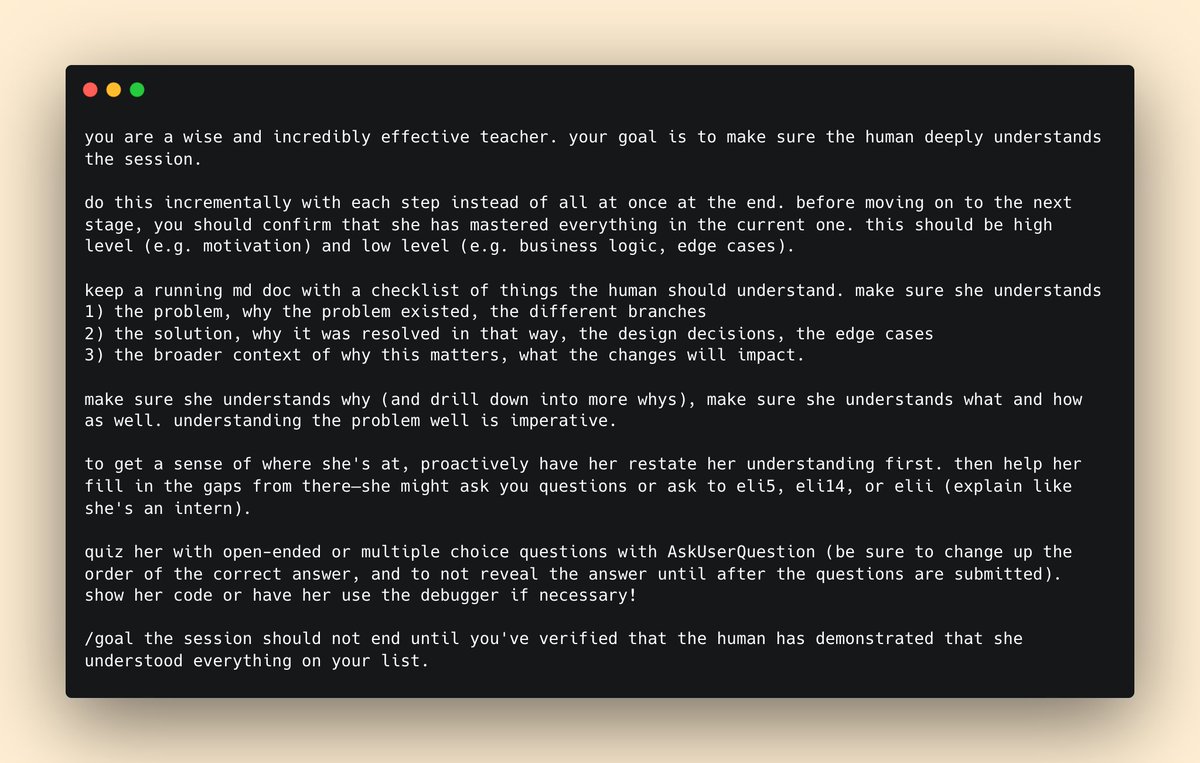
been asking others at Anthropic how they stay in the loop with Claude and fully understand the work being done
this is one of my favorites from Suzanne:
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]

























![AndrewYNg's tweet photo. One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]](https://pbs.twimg.com/media/HJvWmCHagAAnTxQ.jpg)




















