The 36 BIGGEST startup opportunities right now
1. biggest b2c: solving loneliness. third spaces, community apps, IRL
2. biggest b2b: managed AI employees for businesses
3. biggest overlooked: elder tech. 70 million boomers who want products that make them happier & healthier
4. biggest mobile: action apps that do things, not apps you stare at
5. biggest trades: matching platforms for electricians, plumbers, HVAC. supply shrinking
6. biggest consumer social: small social. group chats as products, no feeds, no ai slop
7. biggest ecommerce: agents that recommend products you'll like, shop, buy for you
8. biggest creator: live shows and unscripted content
9. biggest edtech: AI tutors that adapt through conversation
10. biggest SaaS: pay-per-outcome pricing
11. biggest auto: AI service advisor for dealerships. answers the same 15 questions 24/7
12. biggest talent: training non-technical people to operate agents
13. biggest boredom: curated offline experiences delivered to your door. kits, games, challenges. anti-screen products
14. biggest spiritual: the need for belonging is exploding, new formats of spiritual get togethers
15. biggest wellness: longevity biomarkers you actively manage
16. biggest mobile: action apps that do things, not apps you stare at
17. biggest one to solve ai slop: digital verification that you're a real human. every platform will need this within 2 years
18. biggest infrastructure: agent permissions, security, audit trails
19. biggest media: AI native media companies. build distribution, sell products later.
20. biggest parenting: family ops automation. forms, scheduling, logistics
21. biggest accounting: bookkeeping agents that charge per transaction
22. biggest fashion: brand-owned resale. every brand wants to control their secondary market
23.biggest hobbies: adult learning for joy. pottery, woodworking, drawing.
24. biggest skincare: at-home diagnostics. scan, get a protocol, track progress
25. biggest agriculture: precision farming tools for small farms. enterprise version exists, family farm doesn't
26. biggest pest control: subscription pest prevention instead of reactive treatment. the model flip that lawn care already made
27. biggest regulated: on-device AI. healthcare, legal, finance open up when data stays local
28. biggest gaming: AI characters with real memory and relationships
29. biggest dating: agent-mediated matchmaking
30. biggest fitness: adaptive coaching that rewrites your program daily
31. biggest travel: autonomous trip planning and rebooking
32. biggest food: personalized nutrition based on blood work and gut biome
33. biggest pet: health monitoring. $140B industry, almost no tech
34. biggest defense: AI-native security and compliance tools
35. biggest robotics: physical AI. $30 brains on existing hardware
36. biggest nostalgia: products that feel analog. vinyl, paper, handmade. counter-positioning against AI everything
BREAKING
Elon Musk endorsed my Top 26 Essential Papers for Mastering LLMs and Transformers
Implement those and you’ve captured ~90% of the alpha behind modern LLMs.
Everything else is garnish.
This list bridges the Transformer foundations
with the reasoning, MoE, and agentic shift
Recommended Reading Order
1. Attention Is All You Need (Vaswani et al., 2017)
> The original Transformer paper. Covers self-attention,
> multi-head attention, and the encoder-decoder structure
> (even though most modern LLMs are decoder-only.)
2. The Illustrated Transformer (Jay Alammar, 2018)
> Great intuition builder for understanding
> attention and tensor flow before diving into implementations
3. BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018)
> Encoder-side fundamentals, masked language modeling,
> and representation learning that still shape modern architectures
4. Language Models are Few-Shot Learners (GPT-3) (Brown et al., 2020)
> Established in-context learning as a real
> capability and shifted how prompting is understood
5. Scaling Laws for Neural Language Models (Kaplan et al., 2020)
> First clean empirical scaling framework for parameters, data, and compute
> Read alongside Chinchilla to understand why most models were undertrained
6. Training Compute-Optimal Large Language Models (Chinchilla) (Hoffmann et al., 2022)
> Demonstrated that token count matters more than
> parameter count for a fixed compute budget
7. LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023)
> The paper that triggered the open-weight era
> Introduced architectural defaults like RMSNorm, SwiGLU
> and RoPE as standard practice
8. RoFormer: Rotary Position Embedding (Su et al., 2021)
> Positional encoding that became the modern default for long-context LLMs
9. FlashAttention (Dao et al., 2022)
> Memory-efficient attention that enabled long context windows
> and high-throughput inference by optimizing GPU memory access.
10. Retrieval-Augmented Generation (RAG) (Lewis et al., 2020)
> Combines parametric models with external knowledge sources
> Foundational for grounded and enterprise systems
11. Training Language Models to Follow Instructions with Human Feedback (InstructGPT) (Ouyang et al., 2022)
> The modern post-training and alignment blueprint
> that instruction-tuned models follow
12. Direct Preference Optimization (DPO) (Rafailov et al., 2023)
> A simpler and more stable alternative to PPO-based RLHF
> Preference alignment via the loss function
13. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)
> Demonstrated that reasoning can be elicited through prompting
> alone and laid the groundwork for later reasoning-focused training
14. ReAct: Reasoning and Acting (Yao et al., 2022 / ICLR 2023)
> The foundation of agentic systems
> Combines reasoning traces with tool use and environment interaction
15. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Guo et al., 2025)
> The R1 paper. Proved that large-scale reinforcement learning without
> supervised data can induce self-verification and structured reasoning behavior
16. Qwen3 Technical Report (Yang et al., 2025)
> A modern architecture lightweight overview
> Introduced unified MoE with Thinking Mode and Non-Thinking
> Mode to dynamically trade off cost and reasoning depth
17. Outrageously Large Neural Networks: Sparsely-Gated Mixture of Experts (Shazeer et al., 2017)
> The modern MoE ignition point
> Conditional computation at scale
18. Switch Transformers (Fedus et al., 2021)
> Simplified MoE routing using single-expert activation
> Key to stabilizing trillion-parameter training
19. Mixtral of Experts (Mistral AI, 2024)
> Open-weight MoE that proved sparse models can match dense quality
> while running at small-model inference cost
20. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints (Komatsuzaki et al., 2022 / ICLR 2023)
> Practical technique for converting dense checkpoints into MoE models
> Critical for compute reuse and iterative scaling
21. The Platonic Representation Hypothesis (Huh et al., 2024)
> Evidence that scaled models converge toward shared
> internal representations across modalities
22. Textbooks Are All You Need (Gunasekar et al., 2023)
> Demonstrated that high-quality synthetic data allows
> small models to outperform much larger ones
23. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton et al., 2024)
> The biggest leap in mechanistic interpretability
> Decomposes neural networks into millions of interpretable features
24. PaLM: Scaling Language Modeling with Pathways (Chowdhery et al., 2022)
> A masterclass in large-scale training
> orchestration across thousands of accelerators
25. GLaM: Generalist Language Model (Du et al., 2022)
> Validated MoE scaling economics with massive
> total parameters but small active parameter counts
26. The Smol Training Playbook (Hugging Face, 2025)
> Practical end-to-end handbook for efficiently training language models
Bonus Material
> T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019)
> Toolformer (Schick et al., 2023)
> GShard (Lepikhin et al., 2020)
> Adaptive Mixtures of Local Experts (Jacobs et al., 1991)
> Hierarchical Mixtures of Experts (Jordan and Jacobs, 1994)
If you deeply understand these fundamentals; Transformer core, scaling laws, FlashAttention, instruction tuning, R1-style reasoning, and MoE upcycling, you already understand LLMs better than most
Time to lock-in, good luck!
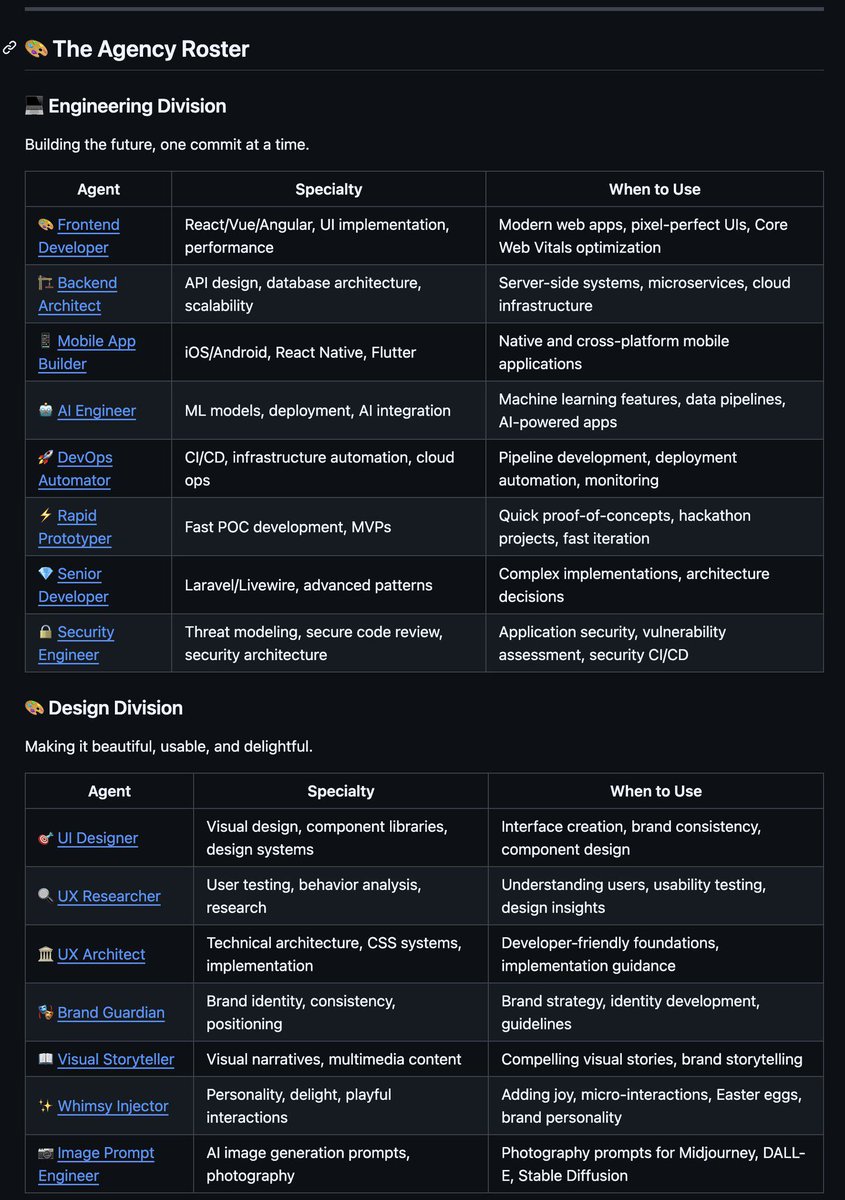
SOMEONE CREATED A GITHUB REPO WITH AN ENTIRE SETUP FOR AN AI AGENCY
Engineers, designers, growth marketers, product managers.
Broken down how even a rookie could understand.
It has over 10K stars in 7 days
GitHub: https://t.co/VYdwzJuCtB
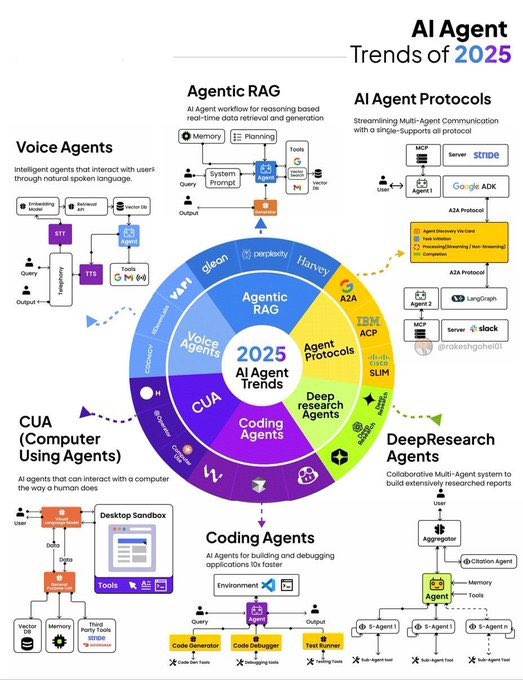
🤖 AI Agents Are Exploding in 2026 — This is YOUR moment!
I’m giving a FREE AI Agent Starter Pack
To get it 👇
👍 Like & 🔁 Repost
💬 Comment “WANT”
👤 Follow me
🔖 Bookmark
⏳ Only 48 hrs • First 300 people
2026 is the GREATEST time to build a startup in 30 years
I’m 36. I’ve sold 3 startups, helped build companies that raised billions, and backed teams from seed to unicorn.
20 MEGA shifts that make this the BEST time to build in a GENERATION:
1. Hardware got smart. Download open-source AI models from HuggingFace to cheap robots and they're suddenly smart. Opens up tons of use-cases.
2. SaaS is imploding. AI can replicate $500K software for pennies. Enterprise software that took 30 engineers now requires 1 and a Claude Code subscription. Founders will go more niche and more custom and outprice incumbents.
3. Outcome-based pricing is eating subscriptions. With AI agents handling work automatically, founders can guarantee results instead of selling features. This creates a massive arbitrage opportunity to steal market share from rigid subscription models.
4. Vibe marketing is the new marketing. AI agents/tools like Lindy, Gemini and Claude Code Using agents to do personalized outreach, ads and content creation it’s getting good. This is like getting on social in 2005.
5. Social is FYP-ified. Distribution no longer requires massive followings, just content that hits. Founders can build audience from zero without ads and then convert them to owned media channels (text/email).
6. Interfaces are vanishing. Conversations are replacing dashboards across industries. This removes training barriers and means customers can use sophisticated products immediately.
7. Companies are obsessed with efficiency and cutting costs right now. Corporate budgets are getting reallocated to AI. Companies are cutting traditional software spend to make room for AI-powered alternatives. This creates fast-tracked approvals for startups delivering 10x efficiency.
8. 99% of MVPs won't need VC. Low-cost MVPs combined with creator partnerships and AI automation allow bootstrapped scaling. For most software businesses, outside funding is now unnecessary.
9. Global teams. You don’t need to hire in your own city anymore. Opens up tons of arbitrage opportunities and ways to create products unlike before.
10. Millions of creators want to get paid. If you have the right product, the right network of creators, you can hit scale insanely efficiently. Never before did this exist. Next gen founders are building startups community first, software second.
11. Prototyping is nearly instant. With Lovable, Rork etc, you can test ideas in days, not months. MVP speed is basically 1x/week. This creates room for multiple products from small companies (multipreneurship), helps get to PMF faster,
12. LLM APIs create building blocks weekly. I can’t even keep up with how many new APIs/tools coming out from LLMs weekly. Example: Nano Banana pro comes out, probably 1000 ideas built on top of that can be $5M/year businesses.
13. $1m+ revenue per employee. With the leverage of LLMs, community and agents, employees are way more efficient. It won’t be uncommon to generate $1m per employee. This will lead to a rise of "multipreneurship", small teams owning multiple products /businesses. Holding companies will be as common as startups.
14. Superniche is the new niche. Because costs to create software startups is 1/100th, you can service little niches (i call them superniches) and still have a life-changing business.
15. Mobile app ecosystem about to 10X. 2 reasons. First is, adding AI to apps make apps more useful. More useful apps, make more money. Second,
16. Compliance and boring workflows are suddenly buildable. Permits, audits, insurance, payroll edge cases, filings, RFPs. These were “too annoying” for startups before. Agents thrive on rules, checklists, and repetition. The least sexy problems now have the best unit economics.
17. Claude Code killed the “engineering bottleneck.” The constraint is no longer “can we build it,” it’s “do we understand the workflow deeply enough.” The winning founders are ex-operators who encode tribal knowledge into agents. Code is cheap. Taste + domain insight is scarce.
18. The long tail of software is now profitable. Niches that capped at $200k ARR can clear $5M with near-zero marginal cost.
19. Services are quietly becoming software. Manual agencies are one agent away from product margins.
20. if AI can replicate $500K software for $20/month, what’s your moat? distribution, customer service, brand, data etc. REALLY good time to be a world class designer/marketer.
(and even more.... but this is getting long already!)
We've entered the rarest of windows...
when multiple technological shifts collide at once, creating a brief period where small teams can build things that were previously impossible.
THE FUTURE OF BUILDING STARTUPS IS DIFFERENT.
I know this...
This unique moment won't last forever. Markets will adapt. Giants will respond. The window will close.
But right now, a founder with clear vision and bias for action can build more in six months than was previously possible in years.
(note: if you need an idea to get creative juices flowing, grab one at @ideabrowser)
The next generation of great companies is being created right now, many by founders you've never heard of.
Some by people who would never have had a shot in previous cycles.
That's the beauty of these rare windows. The playing field briefly levels, and the future belongs to those who see it clearly and move first.
It's a sacred time, don't bookmark/share this, build something in 2026, will ya?
Happy building, my friends. 2026 is yours.
Am I wrong?
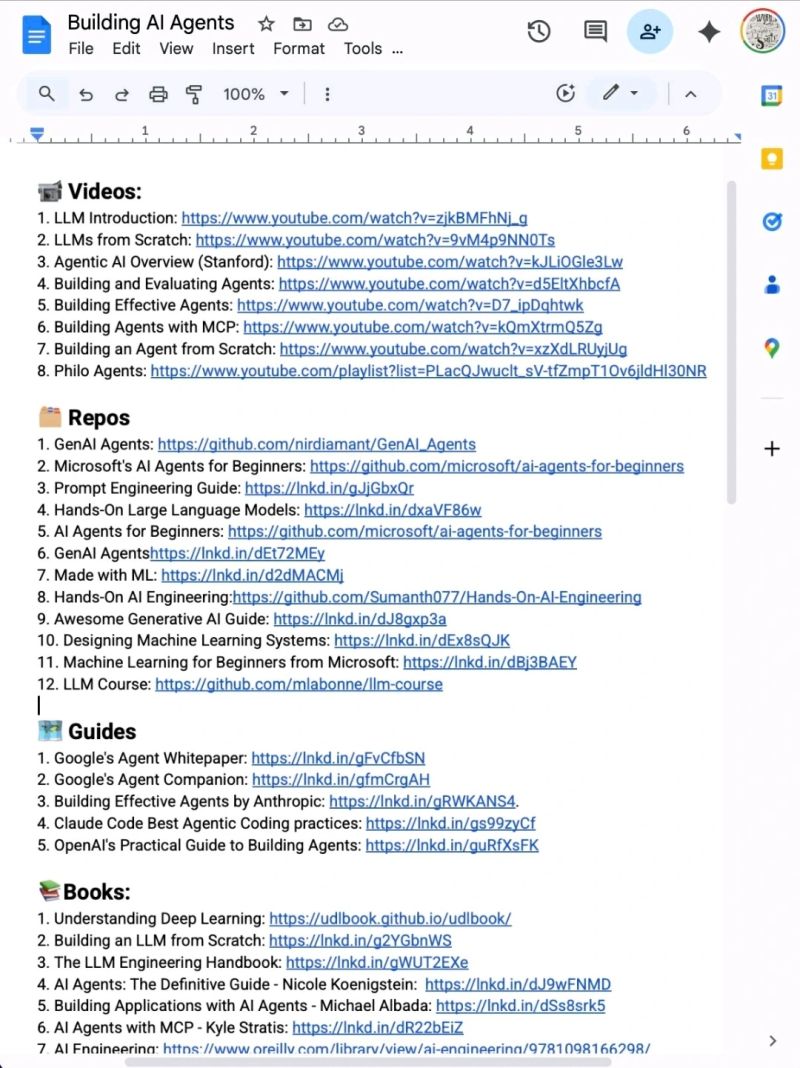
Stop wasting hours trying to learn AI. 📘📚
I have already done it for you.
With one list. Zero confusion. And no fluff
📹 Videos:
1. LLM Introduction: https://t.co/kyDon6qLrb
2. LLMs from Scratch: https://t.co/2hyMhuKoiI
3. Agentic AI Overview (Stanford): https://t.co/FXu6cAqITC
4. Building and Evaluating Agents: https://t.co/ZigR1tdOFL
5. Building Effective Agents: https://t.co/uYwfwO55mO
6. Building Agents with MCP: https://t.co/4arFTW1b3i
7. Building an Agent from Scratch: https://t.co/eOmveyM9Hz
8. Philo Agents: https://t.co/zLu7x1tx9m
🗂️ Repos
1. GenAI Agents: https://t.co/eXCl2YaRPv
2. Microsoft's AI Agents for Beginners: https://t.co/3CSW4zPAwf
3. Prompt Engineering Guide: https://t.co/GVzvxPYDVO
4. Hands-On Large Language Models: https://t.co/0rgDvhx3pI
5. AI Agents for Beginners: https://t.co/3CSW4zPAwf
6. GenAI Agentshttps://lnkd.in/dEt72MEy
7. Made with ML: https://t.co/9z5KHF9DMe
8. Hands-On AI Engineering:https://t.co/dldAj5Xkr6
9. Awesome Generative AI Guide: https://t.co/U2WZhT4ERV
10. Designing Machine Learning Systems: https://t.co/sYAZX34YdQ
11. Machine Learning for Beginners from Microsoft: https://t.co/NjFxHbC9jZ
12. LLM Course: https://t.co/N34YTPu1OK
🗺️ Guides
1. Google's Agent Whitepaper: https://t.co/bW3Ov3vMW0
2. Google's Agent Companion: https://t.co/wredwWAbBA
3. Building Effective Agents by Anthropic: https://t.co/fxtE4alVrJ.
4. Claude Code Best Agentic Coding practices: https://t.co/lLSwJ9pG7C
5. OpenAI's Practical Guide to Building Agents: https://t.co/xgkEIogGfh
📚Books:
1. Understanding Deep Learning: https://t.co/CjcKpTemmV
2. Building an LLM from Scratch: https://t.co/DaWBxOx8o3
3. The LLM Engineering Handbook: https://t.co/ZA1n0N41Mf
4. AI Agents: The Definitive Guide - Nicole Koenigstein: https://t.co/boLkl1VlKb
5. Building Applications with AI Agents - Michael Albada: https://t.co/H1Xf5EkJLL
6. AI Agents with MCP - Kyle Stratis: https://t.co/JI3ELQZE6a
7. AI Engineering: https://t.co/Xk0JzMIf7o
📜 Papers
1. ReAct: https://t.co/QNqE4UU55w
2. Generative Agents: https://t.co/CwEpoJgY1U.
3. Toolformer: https://t.co/5m9xZd5teZ
4. Chain-of-Thought Prompting: https://t.co/KjVlgdWi77.
🧑🏫 Courses:
1. HuggingFace's Agent Course: https://t.co/7FSUYKxIdG
2. MCP with Anthropic: https://t.co/IkZGiWm2yS
3. Building Vector Databases with Pinecone: https://t.co/2YRoMfLdXd
4. Vector Databases from Embeddings to Apps: https://t.co/23A50ixbHJ
5. Agent Memory: https://t.co/uc3L9BrNF7
Repost for your network ♻️
Here are 5 niche businesses in different industries that could fit this acquisition framework:
1. **Local Gym (Fitness)**: Buy cheaply, add online memberships/app for scaling, AI workout personalization to boost retention/margins.
2. **Small Accounting Firm (Professional Services)**: Acquire affordably, build digital client portal, AI tax automation for efficiency.
3. **Boutique Coffee Roaster (Food & Beverage)**: Low-cost purchase, e-commerce site for wider reach, AI supply chain optimization.
4. **Landscaping Service (Home Services)**: Inexpensive buy, online booking platform, AI route planning to cut costs.
5. **Independent Bookstore (Retail)**: Bargain acquisition, website with global shipping, AI book recommendations for upsells.
Built in n8n — it:
🔁 Clones viral TikToks
✍️ Rewrites w/ GPT-4o
🎥 Auto-generates avatar videos
🎬 Adds captions + edits them
📤 Posts to 9 platforms (TikTok, IG,YT,X, etc.)
To Get It..
🔁 Like + RT🫂
💬 Reply “Steal”
📩 Must Be Follow me & I’ll DM you.
Absolutely classic @GoogleResearch paper on In-Context-Learning by LLMs.
Shows the mechanisms of how LLMs learn in context from examples in the prompt, can pick up new patterns while answering, yet their stored weights never change.
💡The mechanism they reveal for in-context-learning.
When the model reads a few examples in your prompt, it figures out a pattern (like a small rule or function). Instead of permanently changing its stored weights, it forms a temporary adjustment that captures this pattern. That adjustment can be written mathematically as a rank-1 matrix, meaning it only adds one simple direction of change to the existing weights.
This rank-1 update is “low-rank”, so it is very cheap and compact. But it still lets the model shift its behavior to fit the examples in the prompt. Once the prompt is gone, that temporary rank-1 tweak also disappears.
So, in simple terms:
The paper shows that in-context learning happens because the model internally applies a temporary rank-1 (very simple) weight update based on your examples, instead of permanently retraining itself.
---
That behavior looks impossible if learning always means gradient descent.
The authors ask whether the transformer’s own math hides an update inside the forward pass.
They show, each prompt token writes a rank 1 tweak onto the first weight matrix during the forward pass, turning the context into a temporary patch that steers the model like a 1‑step finetune.
Because that patch vanishes after the pass, the stored weights stay frozen, yet the model still adapts to the new pattern carried by the prompt.
---
Shows that the attention part can take what it found in your prompt and package it into a tiny “instruction” that, for this 1 forward pass, acts exactly like a small temporary change to the MLP’s weights.
Nothing is saved to disk, yet the block behaves as if the MLP just got a low-rank tweak computed from your examples. Remove the prompt, the tweak disappears, the saved weights stay the same.
As the model reads your examples token by token, it keeps refining that temporary tweak. Each new token nudges the MLP a bit more toward the rule implied by your examples, similar to taking small gradient steps, again only for this pass.
When the examples have done their job, those nudges shrink toward 0, which is what you want when the pattern has been “locked in” for the current answer.
🧵 Read on 👇
I've created a step-by-step guide to help you self-host n8n
This is the exact setup we use to build unlimited AI agents without paying $20K/year on tools like Zapier
Want this premium guide for FREE?
👉 RT + Like & Comment “free” and I’ll DM it to you
No sign-in, no BS
(Must be following)
Elon Musk just stole 18 of Mark Zuckerberg's best AI engineers.
Zuckerberg offered his engineers $250 million each to stay at Meta.
But Elon gave them something money couldn't buy, and they abandoned Meta immediately.
Here's the offer that Zuck's own team couldn't resist:
I've just finished building the ultimate n8n automation library, and it’s a game-changer.
My team sifted through thousands of scattered workflows, cleaned the junk, and handpicked the best.
Now it's a fully organized vault of 1,500+ plug-and-play automations.
You’ll find:
- my most popular n8n builds (WhatsApp agent, scraper agent, TikTok VEO 3 automation, n8n assistant, and more)
- 1,500‑flow n8n template index (tagged by growth, ops, creative) so you never start from scratch
- full vibe‑coding tutorial where I go from basic n8n backend to Bolt front‑end UI in 23 min
Everything’s pre-tested and production-ready.
Want the link to the vault?
LIKE + RETWEET + COMMENT “YES” & I’ll send you the FULL workflow + setup FREE!