Deployed LLMs and users generate millions of conversations every day.
These are full of useful learning signals, yet we don't use them for training.
We introduce self-distillation for learning directly from user conversations – no rewards, no labels, no extra models.
5 Days of Trajectory
🏹Day 5: Scaling SDPO to Agentic Tasks
Continual learning means you must train on data from production. But production gives you one example per task. A user makes a request once. You get one trajectory, not a batch.
However, current RL algorithms don't work that way, They need groups of tasks. By definition, that means you need some artificial environment to perform those rollouts in. But what if you don't?
SDPO is a promising route. It learns from a single trajectory, with no group required and failures still producing signal. The shape of the method matches the shape of production data.
But one fundamental problem remained. Every published SDPO work assumed fresh, on-policy rollouts. Agentic work cannot give you that. Trajectories run for an hour or more and arrive stale. On true agentic tasks, naive SDPO collapses.
We fixed it. We're the first to make SDPO work on agentic tasks.
On Mercor's APEX-Agents, with hour-long trajectories and near-zero base pass rates: 25% average reward, 5x over zero-shot. More importantly, it trains stably and the curve is still climbing.
Read more below.
Proud to announce the launch of @inherent_labs. We’re reinventing the scientific research factory for the age of AI agents.
I’m joined by co-founders @kallyaleksiev, @LouisKirschAI and @TantumSCollins; all are deeply technical operators.
Time to live within the experiment.
We have been exploring new algorithmic frontiers and are excited to share our contributions to Self Distillation Policy Optimization (SDPO) for agentic continual learning, check out our blog post here:
https://t.co/5xjL02jtUz
Self-distillation can reduce hallucinations when teaching LLMs new knowledge.
I think the first time I heard about how RL enable learning without increased hallucination was in @johnschulman2 talk in 2023.
Turns out, like many of RL’s benefits, this one also comes from learning on-policy.
Today and tomorrow we’ll be presenting self-distillation with orals at ICLR in Rio 🇧🇷
1. “Self-Distillation enables Continual Learning” at lifelong agents workshop (Sun 11:30am)
2. “Reinforcement Learning via Self-Distillation” at scaling post-training workshop (Mon 2:40pm)
3. “Test-Time Self-Distillation” at test-time updates workshop (Mon 4:15pm)
What do you do when reward models fail in RLHF?
Scalar rewards flatten messy, context dependent human preferences into a single number. The reward model learns a distortion, and the policy optimizes it faithfully. 🧵
OpenClaw-RL Technical Report! Make your🦞@openclaw stronger by just using it. We propose a method that combines the advantages of GRPO and OPD, and evalution results. The repo is already 1.7k stars now, feel free to contribute! Come in and have fun~
@MengdiWang10@LingYang_PU
@ytz2024 It seems very related to on-policy self-distillation from user interactions. The main difference I see is that you have the extra step of knowledge extraction step, whereas in SDPO we learn directly from raw interactions https://t.co/Ut4ItEh6vA
Deployed LLMs and users generate millions of conversations every day.
These are full of useful learning signals, yet we don't use them for training.
We introduce self-distillation for learning directly from user conversations – no rewards, no labels, no extra models.
We've integrated on-policy distillation RL methods (SDFT and SDPO) into OpenClaw-RL's pipeline, working directly with the original authors! @IdanShenfeld@thomasklbg
OpenClaw-OPD now supports even more effective learning paradigms for personalized AI agents trained from natural conversation feedback via @openclaw.
We welcome the integration of novel and effective methods — if you have ideas, let's build together 🤝
🔗 https://t.co/ry18qekutm
Working with the authors @IdanShenfeld@thomasklbg of this excellent series of papers, we have integrated their novel on-policy distillation methods into OpenClaw-RL. We welcome integration of new and effective methods. Make your personal @openclaw🦞agents stronger every day.
Train your 🦞@openclaw simply by talking to it. Meet OpenClaw-RL. Host your model on our RL server, and your LLM gets optimized automatically. Use it anywhere. Keep it private. Make it more personal every day. We have fully open sourced everything. Come in and have fun!
@YinjieW2024@openclaw For your Training Method 2, would be super cool to use the slightly more direct approach of self-distillation from user interactions. Then you don’t need another model to provide hints (no additional generation and cheap training):
Deployed LLMs and users generate millions of conversations every day.
These are full of useful learning signals, yet we don't use them for training.
We introduce self-distillation for learning directly from user conversations – no rewards, no labels, no extra models.
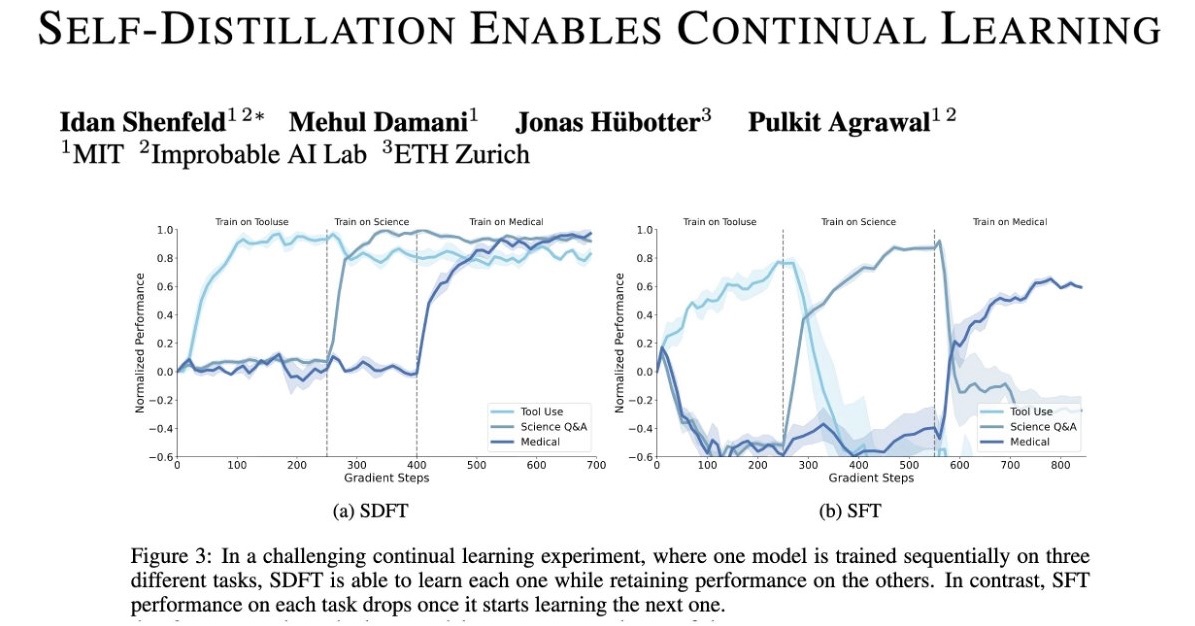
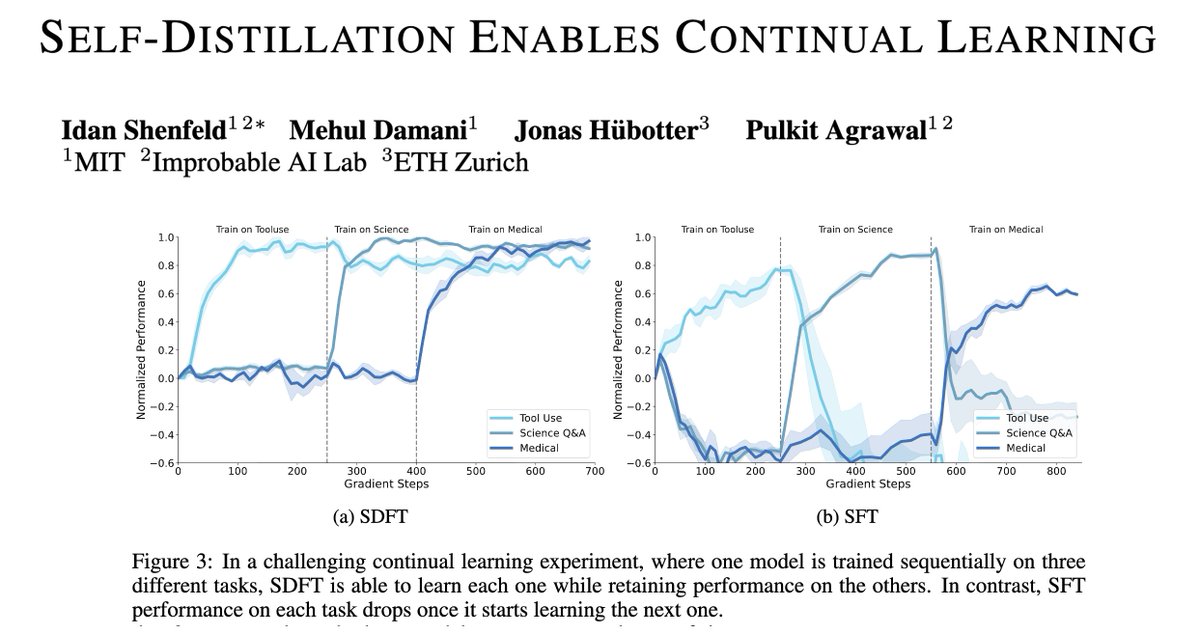
People keep saying 2026 will be the year of continual learning.
But there are still major technical challenges to making it a reality.
Today we take the next step towards that goal — a new on-policy learning algorithm, suitable for continual learning!
(1/n)
Deployed LLMs and users generate millions of conversations every day.
These are full of useful learning signals, yet we don't use them for training.
We introduce self-distillation for learning directly from user conversations – no rewards, no labels, no extra models.
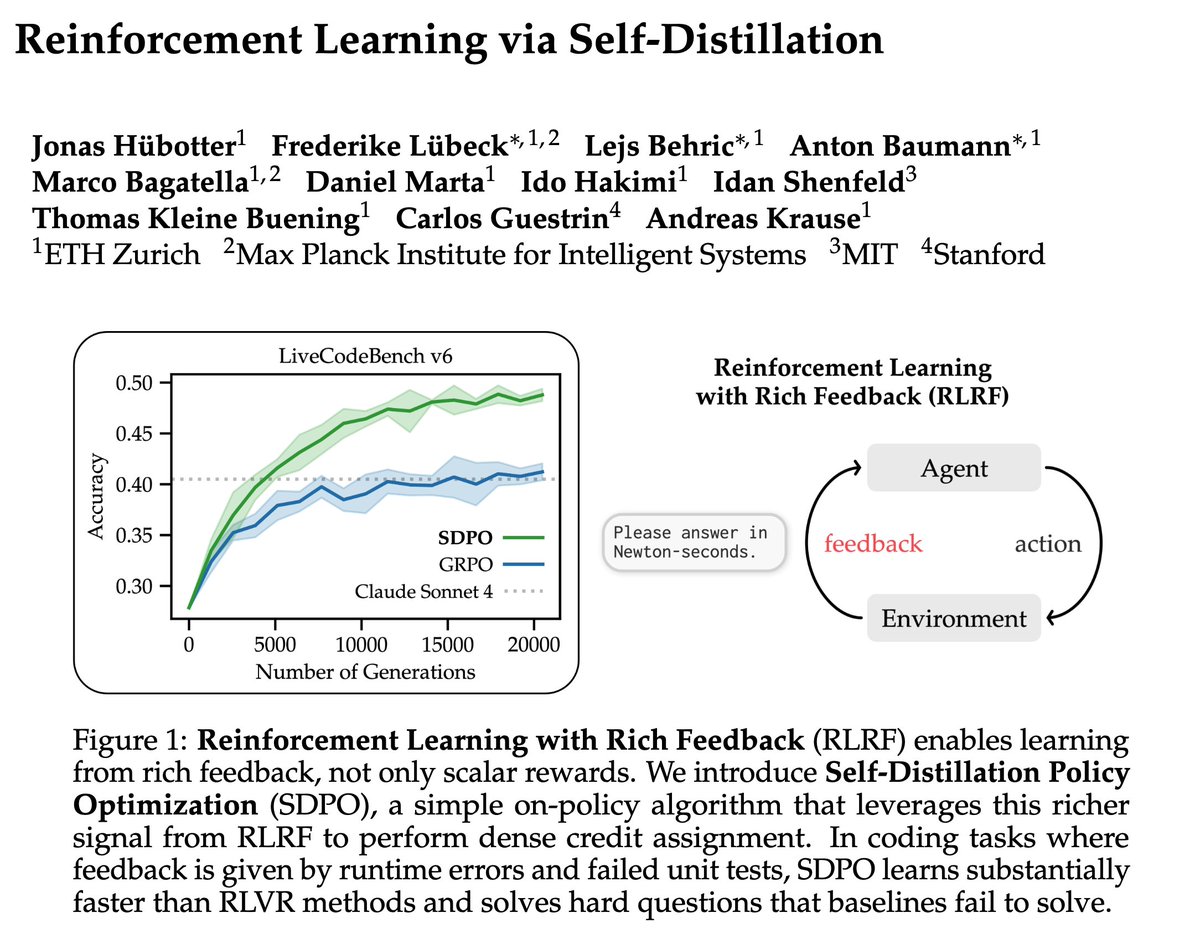
Training LLMs with verifiable rewards uses 1bit signal per generated response. This hides why the model failed.
Today, we introduce a simple algorithm that enables the model to learn from any rich feedback!
And then turns it into dense supervision.
(1/n)