Incredibly excited and proud for Uni-1 to be generally available to the public! Free users, paid users - everyone, Uni-1 is available right now!
This has been a monumental effort across the whole company - we've managed to research, build and ship something with a super tight team that pushes boundaries in multimodal intelligence! Try it out and share your favorite Uni-1 results!
When I struggle to structure my thoughts about what's happening I turn to writing. Today about the recent US Anthropic ban news, what it says about power and dependency, and what it should mean for Europeans and citizens of the world. It's a long one. https://t.co/6dpw0QOQeO
We are at CVPR this week. On Monday we announced the Open Physical AI (OPAL) Lab at Luma where we are working to solve one of the most consequential problems in AI - generalization in robotics. It's an Open Science effort so that all the physical ai infrastructure and intelligence of the world doesn't end up in centralized state.
If you're interested in learning more come talk to us:
- Booth #613
- Thu Happy Hour, Flight Club @ 6-9PM
- We are also around, DM us
We are launching Open Physical AI Lab at Luma to solve generalization in robotics
We believe general physical AI is the most consequential problem to solve to improve life on Earth. Allowing one or very few companies to control the entire intelligence and physical infrastructure of the world is a profound threat to the world. This is the path LLMs took, and it is the path physical AI is on today. To solve this problem of generalization in physical AI and to maximally benefit all of humanity, we are establishing the Open Science Physical AI Lab (OPAL Lab) at Luma.
Today, physical AI and robotics are in the pre-AI-scale era. Unlike LLMs and multimodal models which are capable of solving a wide range of previously seen and unseen problems, robots are trained on and can only replay specific tasks in specific environments from small scale examples, limiting their utility. Physical AI has a data gap, creating a generalization crisis. The default solution is to simply scale teleoperation to capture data across every possible task and combination of tasks – a physically and economically impossible approach.
Over the past 4 years, through fundamental research on multimodal AI, Luma has trained frontier foundation models in 3D, image, video, and unified language-visual generation. In this process, we have built vast infrastructure to make sense of raw internet-scale multimodal data and train efficient generative models with it. Building these systems has given us unique insights into how raw multimodal data can be used to learn physics, perception, reasoning and interaction with the physical world. Over the past few months, mounting empirical evidence from our work on Unified Models has turned this realization into a strong scientific conviction. Generalization is not unique to text.
The Open Physical AI Lab will research and scale methods to solve generalization and develop World Models for understanding and interaction with the physical world. This generalization will lead to robot systems proliferating everywhere - factories, research labs, hospitals, streets, and even our homes. Given the societal and economic upside, this transition will be faster than any other technology in history and these systems will be embedded into every layer of human life. Physical AI will help us solve labor shortage and stagnation plaguing world economies. Physical AI will become the means of production in every nation.
Allowing one or very few companies to control the entire intelligence and physical infrastructure of the world is a profound threat to humanity and democratic freedom. This is the path LLMs took, and it is the path physical AI is on today.
To reverse this trajectory, this lab will be an open science effort. We will use our scale and expertise to build the substrate and make it available so that any dedicated group of people can use it, modify it, and assemble it into systems of productive work. To accelerate progress, we will collaborate with our peer labs and academia on core research, build evaluations to measure progress and assess safety, and partner with industry leaders on chips, hardware, and physical agent systems.
If you share this conviction and believe that this foundation should be built in the open for the benefit of all humanity, please come work with us.
@baaadas@LumaLabsAI Thank you for everything Jiaming! It's been amazing to work with you every step of the way - very excited to see what you'll cook up next! 🫶
First try at multimodal image + text and already among the big players with our cracked team. We're ramping up extremely fast in terms of compute, modeling, performance optimization, and infra. This is just the start - if you want to join before we reach rank 1 - let's chat 😉
Exciting news: UNI-1.1-Max and UNI-1.1 debuts making @LumaLabsAI the #3 lab in the Image Arena across both Text-to-Image and Image Edit! These are versions released without agentic search.
Text-to-Image Arena
- UNI-1.1-Max #6 overall (1193), +12 points over MAI-Image-2
- UNI-1.1 #7 overall (1190), +13 points over Reve-v1.5
Multi-Image Edit Arena
- UNI-1.1-Max #7 overall (1315), +21 points over Seedream 4.5
- UNI-1.1 #8 overall, (1298)
Single-Image Edit Arena
- UNI-1.1-Max #7 overall (1337)
- UNI-1.1 #11 overall, (1310) on par with Grok-Imagine-Image (20260207)
Congratulations to @LumaLabsAI on this solid performance!
Most image models are good at one thing.
Uni-1 has been good at everything we've thrown at it.
Our team generated thousands of images leading up to Uni-1 launch. We embedded them all into a single map where visual similarity determines proximity. The result speaks for itself.
We are loving the energy around Uni-1!
Quick note since we’re seeing questions:
With Luma Agents, requests can route across models. If you want to make sure you’re using Uni-1, here’s how:
- Select Create Image → Uni-1
- Or, explicitly ask the agent to use Uni-1
- Check the model label on outputs to confirm
API access coming soon for more direct testing.
Keep the feedback coming, and keep on creating → https://t.co/zjJZMt8Dt6.
I've been playing around with Uni-1 with Luma Agents and been getting addicted to how easy it is to get really cool results!
First two images are generated by Uni-1 directly with the agent! Third and fourth are photos of myself and a photo of my actual custom guitar that was taken in the factory!
So fun to play around with. Will share more over the coming days 🙂
(Btw: we're hiring! Please reach out if you want to build the most efficient systems for large-scale distributed training and inference that powers models like Uni-1)
Uni-1 is built on Luma's Unified Intelligence architecture, it understands intention, responds to direction, and thinks with you.
Try today → https://t.co/OEmsCmO7f0
UNI-1 is intelligent, directable, cultured. Incredible range it can do.
Incredibly proud of the world-class team building a world-class model.
It’s a daunting task to go up against industry giants like Deepmind/OpenAI/Bytedance.
More to come! API, technical report, model card…
Come join us!
🙏 Grateful and Proud beyond words to be part of the incredible team that built UNI-1 @LumaLabsAI!
Intelligent, directable, cultured — and the manga generation? See these 👇 and try it FREE today here: https://t.co/UXnTp8YCYi!
Plus we are hiring!
Excited to introduce Uni-1, our new *unified* multimodal model that does both understanding and generation: https://t.co/VkgMNnYtZv
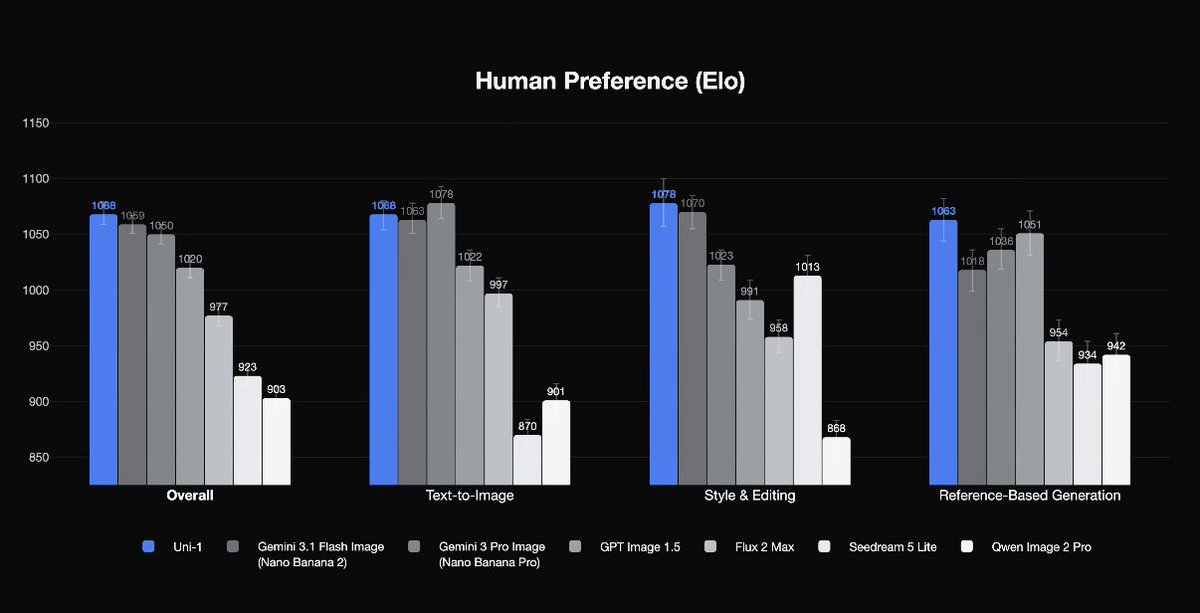
TLDR: I think Uni-1 @LumaLabsAI is > GPT Image 1.5 in many cases, and toe-to-toe with Nano Banana Pro/2. (showcase below)
Uni-1 is a decoder-only autoregressive transformer. Text and images are represented in a single interleaved sequence, acting both as input and as output. This enables Uni-1 to think and render in the same forward pass, achieving a new benchmark of intelligence and quality.