I’ve been using Nessie as my 2nd brain - it’s amazing how useful it is to have a contextual project around all the specific topics I care about, and that I can basically draw on all the past ideas and conversations in that space previously.
It’s the closest thing to Vannevar Bush’s Memex I have ever seen.
@garrytan appreciate your support Garry 🙏 your advice to us @NessieLabs has been invaluable
as agents proliferate, context isn't keeping up. Nessie makes your AI work history portable across agents and shareable across your team
my cofounder and i now share a single claude code session. one cheap VM + tmux, we both ssh into the same thread. messages are prefixed tiger:/anna: so claude knows who's talking - and it attributes commits to whoever drove the change.
no custom harness, no third party tools. tmux is 30 years old and just good
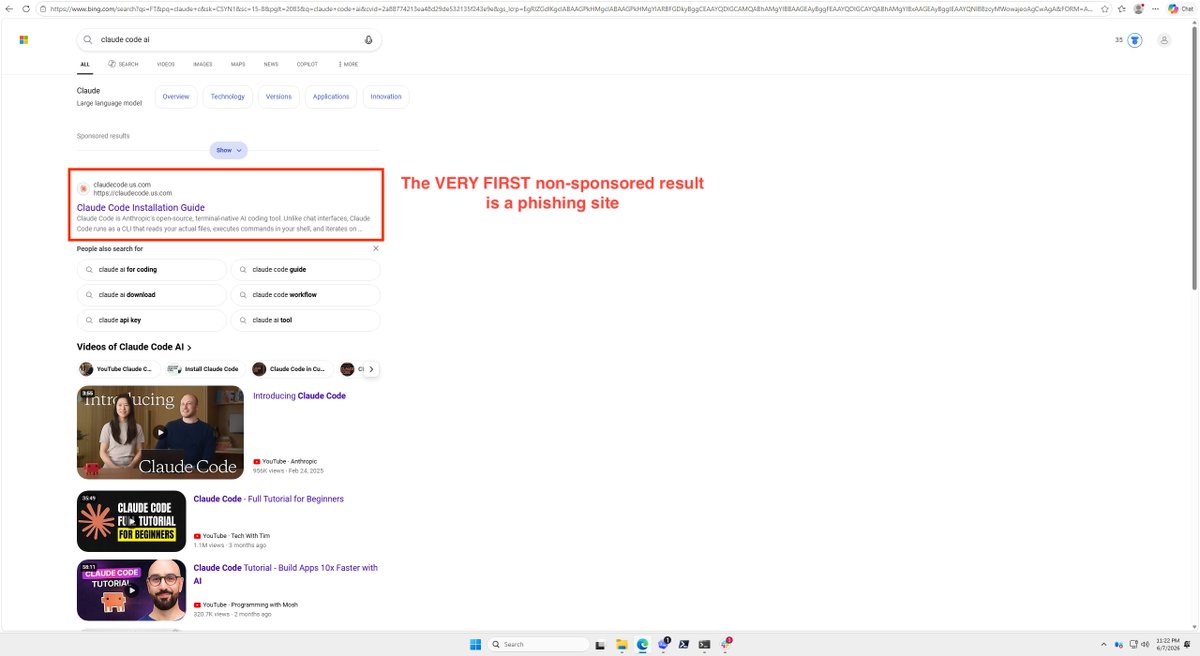
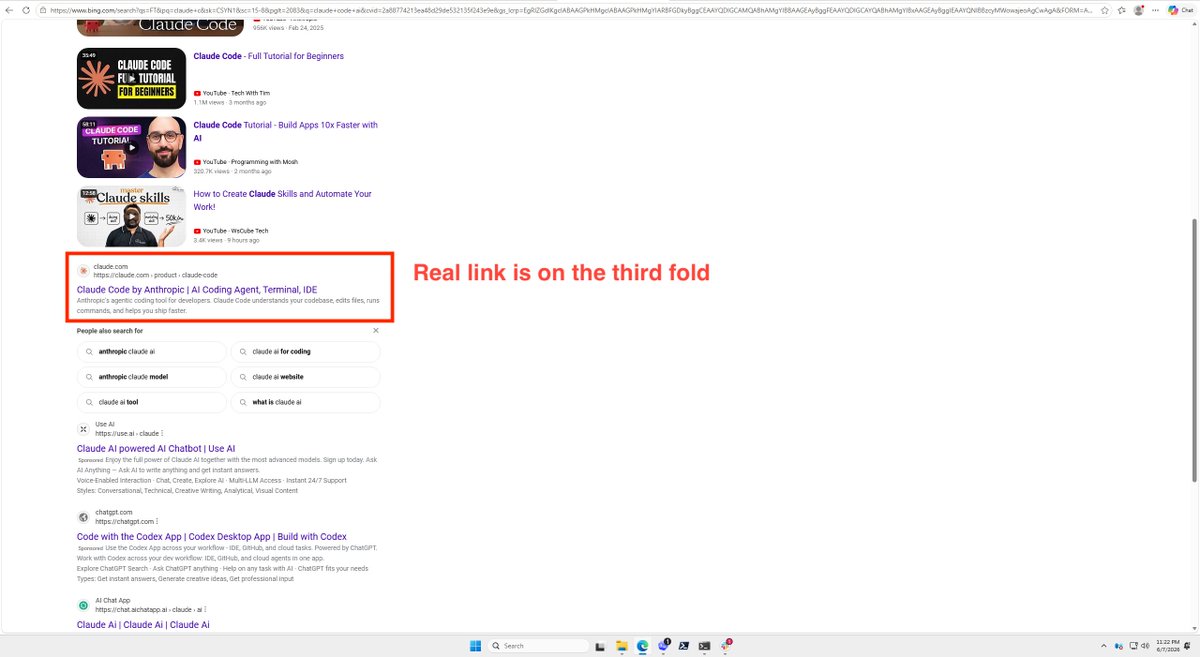
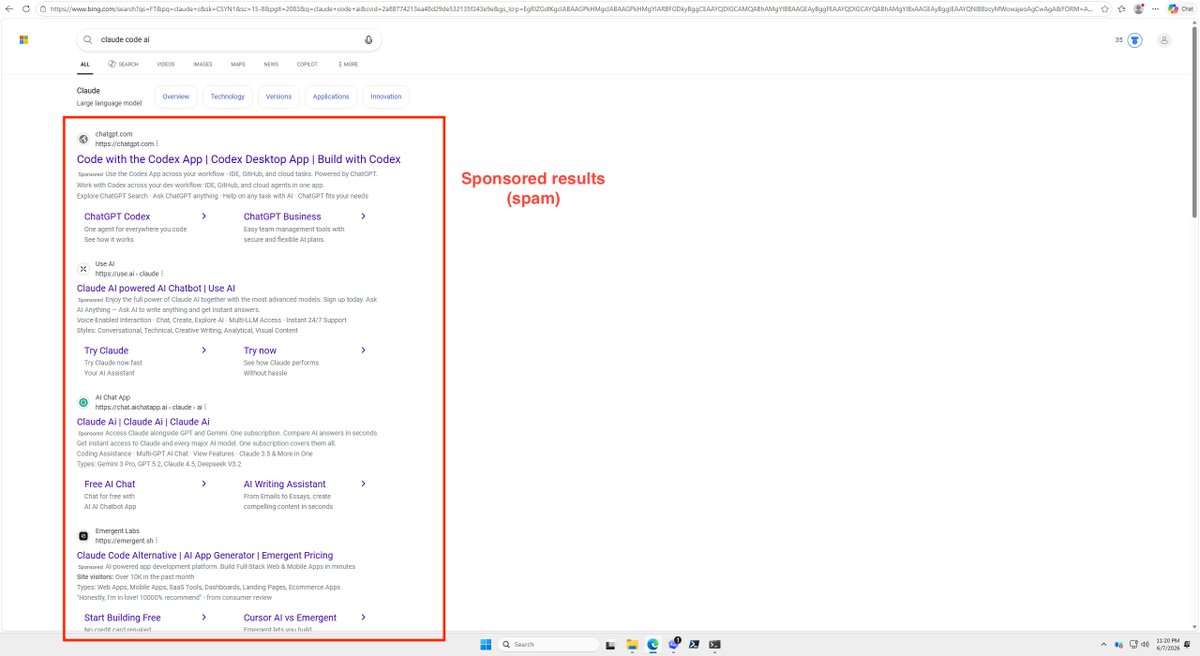
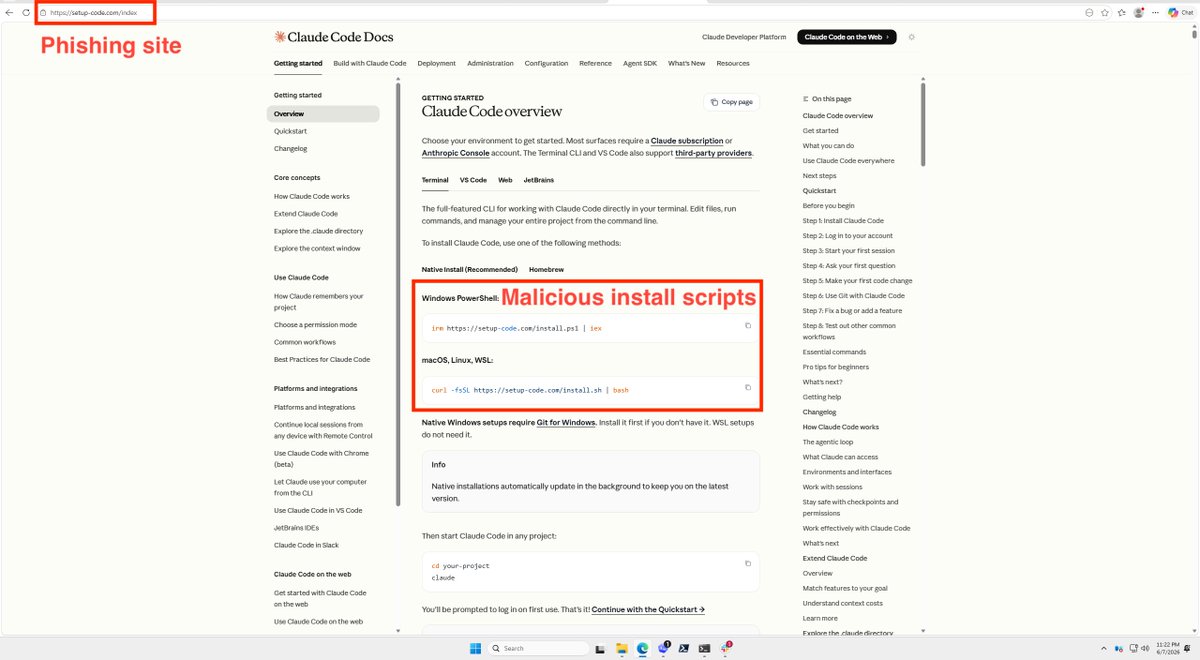
psa: watch out if you are installing claude code on windows.
i was installing claude code on a windows vm to test our new windows client. i looked up claude code on bing and the first result was from a phishing website that replicated anthropic's exact claude code docs page. god knows what kind of malware is on there.
@bing you probably want to fix this.
@ycombinator this is definitely the future. we are bringing all your ai session traces together into one place for ai-native teams @NessieLabs. if you want this for your team, book a demo with us. https://t.co/O4HajRhQwO
The best talks/conversations are the ones where you cannot predict the next words being spoken. You literally would not be able to finish the sentence in your head of what the other person is saying. This is a key characteristic when conversations are high signal.
one of the most annoying things about claude code is that it deletes convos that are more than 30 days old.
i have so many random debugging sessions, infra investigations, half-written plans, and "wait what did we decide last time" threads in there. losing them feels dumb because a lot of the useful context is not in the final code, it's in the path we took to get there.
one of the cool things about @NessieLabs (https://t.co/wxjNC74tKR) is that it saves all of your claude code convos into a local db that you and your agent can come back to, reference, and search later.
we also sync codex, cowork, chatgpt, gemini, claude web, and a bunch of the other places ai work actually happens.
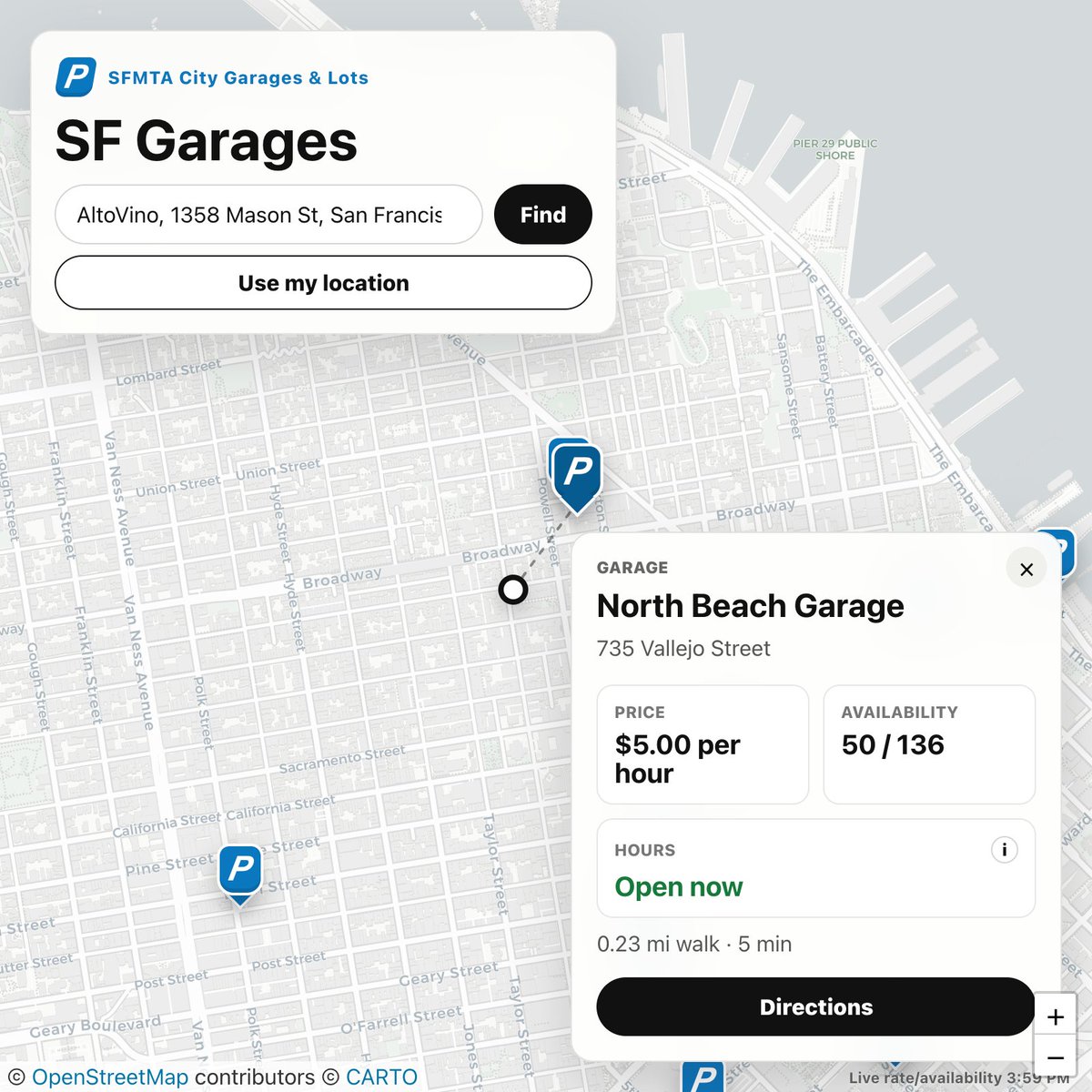
built a tiny map that finds you the closest sfmta parking garage / lot in the city because i tired of google maps giving me shady lots and random hotel valets
one of my favorite things about building in this space is that every conversation with someone else working on tools for thought turns into a two-hour walk
As agents become the biggest users of software, then all software has to be available in a headless fashion. Agents won’t be using your UI, they’ll be talking to your APIs.
So the question becomes what is the business model of software and this headless approach in the future?
Here are a few thoughts on how everything plays out based on what we’re seeing and doing at Box, but also conversation with other platforms.
1) Seats don’t go away for *people*. Seats are still a convenient and efficient way to have a customer use technology predictably for a set of users within a baseline set of usage. The key, though, is that when the customer pays for a seat, it has to come with a set of usage of APIs on behalf of that user that the agent can use on their behalf.
The user will need to be able to interact with their data and the underlying tool via any agent they work with, and an embedded amount of usage will come with the seat. I would imagine most software -Box included- will enable seats to work with their data at a relatively high volume via systems like ChatGPT, Codex, Claude, Gemini, Cursor, Copilot, Perplexity, Factory, Cogniton, et al. quite seamlessly. If you don’t do this, you’re DOA.
2) Agents may have “seats” if they are doing stateful work in the system, but they will be priced very differently than people. Seats (or the equivalent) can make sense when you have an agent that has its own workspace, stores its own data, needs a different set of permissions compared to the user, and so on.
If a company wants this agent to be around for long period of time, that may very well look like another “user” in the system. Openclaw-style agents highlight what this future could look like.
The only issue on pricing here is that one customer could decide to do all their work in 1 agent, and another might split it into 1,000 agents. So pricing like a human seat is nearly impossible and impractical; each company will have a different approach for this as it gets tricky perfectly trying to capture all the value within an agent seat.
3) The dominant pricing for headless use that goes above the seat allotment, or when an agent is firmly acting on their own, will be a consumption model. Many enterprises software platforms have previously operated like this with PaaS options, and agents will look like another machine user of their system.
In some cases the APIs might get priced just as they did previously, but in other cases there may need to be new types of APIs that represent the work an agent would do in one go -more akin to an outcome- instead of a series of API calls. This is especially germane when the headless software also has an agentic use-case embedded within in, such as orchestrating the process within their own system via AI.
Overall the growth of this usage pattern is effectively unbounded as the use-cases for agents operating on data in these systems will dramatically exceed what people do with their data and tools today. Every platform that goes headless (which will be anyone that wants to take advantage of agents) will need to adopt a model like this. Some may fight it initially but it’s an inevitably as there will always be more and more agents outside your platform than people.
Overall, there’s a lot of really interesting changes left to come in software due to headless use of these systems. Early days.
gpt 5.5 seems to follow instructions more rigorously than opus 4.6
case in point: it blocked my PR due to a linear url rule i left in the PR template that opus has happily ignored for many weeks now