🚨EXCELLENT PRIVACY & AI PAPER ALERT: Prof.
@DanielSolove has recently published "Artificial Intelligence and Privacy," and you can't miss it. Interesting quotes below:
"Privacy laws generally do not mandate that a site protect against scraping. It is up to organizations to protect user data in their terms of service and then to enforce their terms of service. But privacy laws should mandate protection against scraping. If an organization attempted to transfer massive amounts of personal data to third parties without consent, this practice would violate many privacy laws. Failing to prevent third parties from just taking the data is the functional equivalent of selling or sharing it." (page 27)
-
"Decisions derived from predictive models challenge the principles of due process. Justice traditionally dictates that individuals should not face penalties for actions they have not committed. However, predictive models enable judgments and potential repercussions based on actions that individuals have not undertaken and may never undertake. As Professor Carissa Véliz contends, “by making forecasts about human behavior just like we make forecasts about the weather, we are treating people like things. Part of what it means to treat a person with respect is to acknowledge their agency and ability to change themselves and their circumstances.” (page 39)
-
"One remedy that is increasingly being used is algorithmic destruction. For example, in In re Everalbum, Inc., the FTC ordered a company to delete “any models or algorithms” developed with data it had improperly collected. However, Li argues that the remedy of algorithmic destruction can be too severe and might “harm small startups and discourage new market entrants in technology industries.” Additionally, it is one thing for the FTC to order a small company to delete an algorithm, but what about a gigantic company such as Open AI? It is hard to imagine the FTC or any regulator ordering the deletion of a hugely popular algorithm with a multi-billion dollar value." (page 59)
Link to the full paper below.
Is Generative AI a Bubble?
Let me make the contrarian case that we are living in the middle of a generative AI bubble.
First, I want to clarify that I am not an AI skeptic or fatalist. I don’t believe AI will take over the world and must be stopped. On the contrary, I am a long time user and fan of artificial intelligence. At the same time, I’ve also been around long enough to know that unbridled enthusiasm and too many Super Bowl ads spell bubble. So let me make the contrarian case that we are living through a generative AI bubble; even though I strongly believe AI is here to stay.
My case rehashes ideas introduced by Herbert Simon more than 50 years ago. Basically, the notion that since generative AI supplies content what it demands is attention. And attention, not content, is what’s scarce in our world.
So let’s get started. In the last couple of years everybody and their mother has experienced the jaw dropping power of AI generated images, text, and video. And we can all agree that their quality has improved enormously. No doubt, we are moving towards a world that will be inundated by AI generated content. But here is the twist. We can also all agree that six years ago, when these technologies were nowhere near as good as they are today, the world was not suffering from a lack of images, text, or video. Generative AI is cool, but it is not satisfying a need involving a real supply constraint.
I love generative AI. It is beautiful and poetic. It is certainly helping online attention junkies & marketing folks generate fleeting waves of engagement. But those generated ads and memes are chasing the same eyeballs and dollars. AI generated video can create beautiful shots and will surely be used in film. But what supply constraint is that truly releasing? Will we watch more films as a result of that? Will we pay more for them? Much of the world is already glued to a screen for 5 to 8 hours a day.
By all means we must celebrate advances in AI. Whether in film, the arts, or in other fields. They represent a great triumph of human ingenuity and creativity. But we also need to acknowledge that these triumphs impact specific parts of systems that involve multiple constraints. Our modern knowledge economy has some legit supply constraints that are out of reach from AI technology, because AI does not do what we need. It simply does what it does. Our economy remains largely physical. Despite the growing importance of digital technology, I bet you that housing, taxes, travel, and food still explain most of your credit card bill. To put this in simple terms, consider our knowledge economy’s voracious need for housing. If young professionals want a battle cry for their generation that could well be: we wanted homes, but all we got were more memes. AI is a technology driven by supply side interests, but it is still, a bit like the proverbial hammer looking for a nail.
Today, gen AI is a technology that lives primarily on the web, where it is used primarily to generate content. But we need to remember that in the web, content is not always king. One way to conceptualize the modern web, and its economy, is as a symbiotic battle between content engines and attention engines. Attention engines have the traffic. They are mainly search and social media. These are the platforms that have the eyeballs that everyone is competing to attract. If you are not a platform, you are either an eyeball, a content producer, or both. Also, if you are not a platform, you are at a clear disadvantage, as you are one more content producer competing for a tiny share of the attention that platforms have. Generative AI is not a platform. It is a powerful tool to accelerate the production of content. A tool that will increase the competition among content producers. But if the platform/content balance remains, it will be the platforms that will reap the benefit of the added content.
So why does all this spell bubble? While I agree that the technology has true potential, I am not sure we need 1,000 companies doing generative images, video, or text. The substitutability among many of them is rather large. Like in the dot com bubble of the early 2000s, we are amidst a Cambrian explosion of firms that will most likely be followed by a mass extinction event. Generative AI may have many potential users, but may not need as many providers. Like it once happened to search, the AI industry will sooner or later start to consolidate. And when it does, it may not be pretty, as the valuations of those being acquired in dire straits may not be the ones that their investors hoped.
I know this is a contrarian take. But I feel the tide is starting to turn. On the mean time, sit back, relax, and enjoy the memes.
⚖️ Generative AI vs. Copyright Law - a timeline. If you are a privacy professional, you can't ignore AI-related copyright lawsuits anymore. Read this:
In order to develop and train large language models (LLMs), AI companies rely on web scraping, a practice that will "digest" all internet data. In the context of generative AI, this practice has various legal implications, and some of the most relevant are privacy and copyright-related.
I've been discussing the privacy issues behind scraping extensively in my newsletter and in recent social posts; you can check them out. They involve lawfulness of processing, data subject rights, data protection principles, and more.
What may be unexpected is that copyright issues are ALSO relevant from a privacy perspective. Why? If scraping is banned or restricted due to copyright issues, there will also be privacy implications, as AI companies will have to find other sources of data to train their models, there will potentially be personal data involved, and possibly new data protection implications.
In the infographic below, you can see a brief timeline of recent AI-related copyright cases. This list will probably grow in 2024.
So privacy professional: the next time you see discussions on whether generative AI serves a new transformative purpose and whether this is "fair use," stay tuned - as there might also be indirect consequences for privacy, data protection, and data practices behind AI.
I will write more about the topic in next week's edition of the newsletter. To receive it in your email, subscribe
What's better than one episode on #AI with @pa_balland? Two episodes, obviously! The AI space seems to have exploded in the last year, so we invited PA back on the show to catch us up on the new breakthrough and look ahead to their possible implications
https://t.co/o2LPFPuJco
The Digital Services Act is a transparency machine. Platforms have to submit every 6 months a report describing their content moderation activities in the EU. The first reports are in and there’s a wealth of information in there. Thread
Think you can detect AI writing? Experts can't.
This paper had editors from top linguistics journals try to do just that and "reviewers were largely unsuccessful in identifying AI versus human writing, with an overall positive identification rate of only 38.9%." HT @EnglishOER
We have concluded a long and fruitful trilogue on the #AIAct where we found agreement on large and important chunks of the text, among which requirements for high-risk AI systems, sandboxes, market surveillance and enforcement, penalties and fines.
1/ Qualitative interviews offer unparalleled richness but are rarely used in economics. Let's change that! New WP with @Ingar30 uses an AI-driven approach to conducting q qualitative interviews, making them scalable, cheap, and ripe for both qualitative and quantitative analysis!
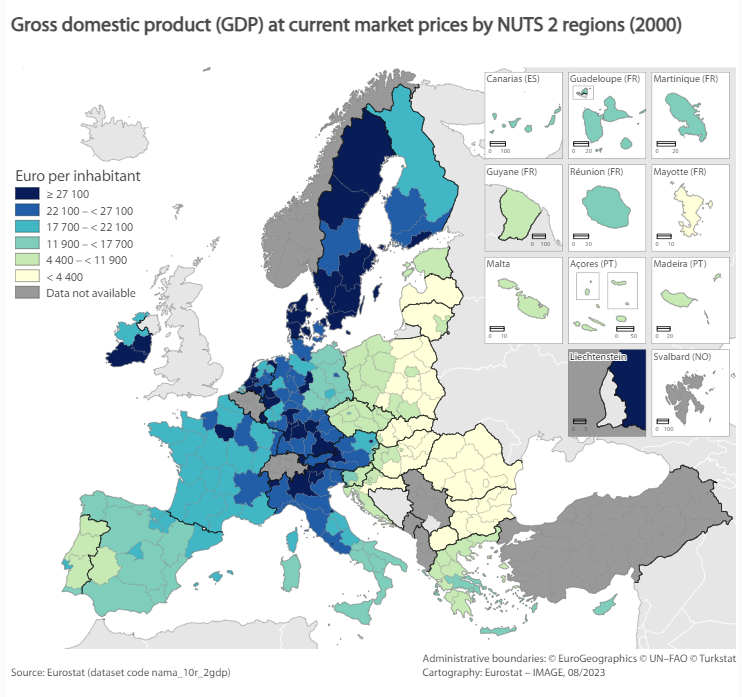
🌍 📊 Create your maps with IMAGE, the EUROSTAT's map generator tool
🔸Make professional statistical maps in several predefined layouts by adding your data, or loading them directly from @EU_Eurostat's database!
➡️ https://t.co/Wo0otKgZs7
@DijkstraLewis
Too often, I find AI Ethics research to be:
1) technosolutionistic & unsituated
2) excellent, but hard to place in dialogue with other work.
In this 🆕📝🚨: Blair Attard-Frost and I suggest that Value Chains can help: https://t.co/Rs4IeDPBW9
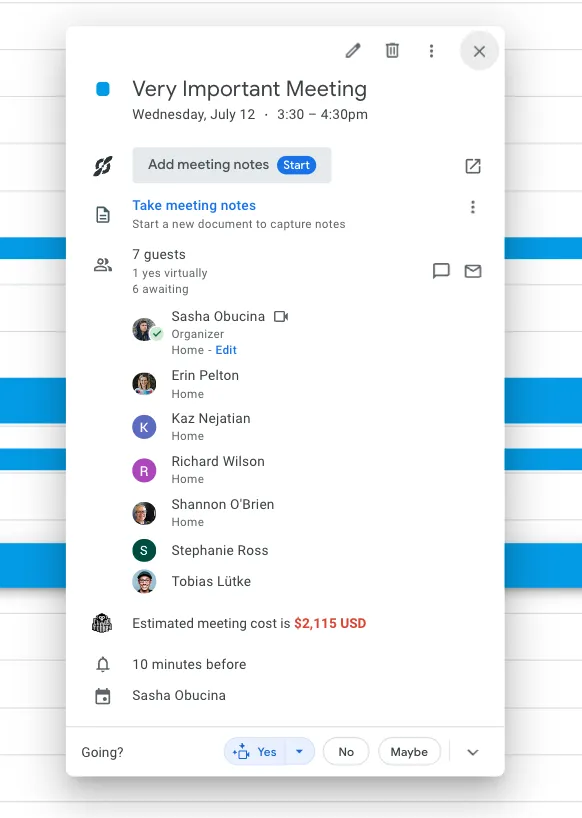
Shopify deleted 12,000 meetings this year.
Today, they went a step further with a tool that shows the $$$ cost of holding meetings.
I spoke to @nejatian (Shopify's COO) about meeting bloat and protecting craft time.
Here are 6 spicy takes from our interview 👇
What is intelligence?
And how is it different from problem solving?
These questions are central in our current discussion on AI & were debated passionately this week at the Santa Fe Institute’s conference on collective intelligence.
But what did we learn?
🧵 .. 1/N
🚨NEW: full #AIAct report, adopted on 11 May in joint IMCO-LIBE Committee, is finally there! Document is tabled for #JUNE plenary session. Discussion on 13 June. Vote on 14 June. Afterwards, #trilogue can start. #transparency#EU
D/L directly via https://t.co/ulE6mNm456