Partner @FactionVC. Advisor @LightspeedVP. Previously @DCGco. Fascinated by all things Crypto ∪ AI. Views are my own and posts never investment advice.
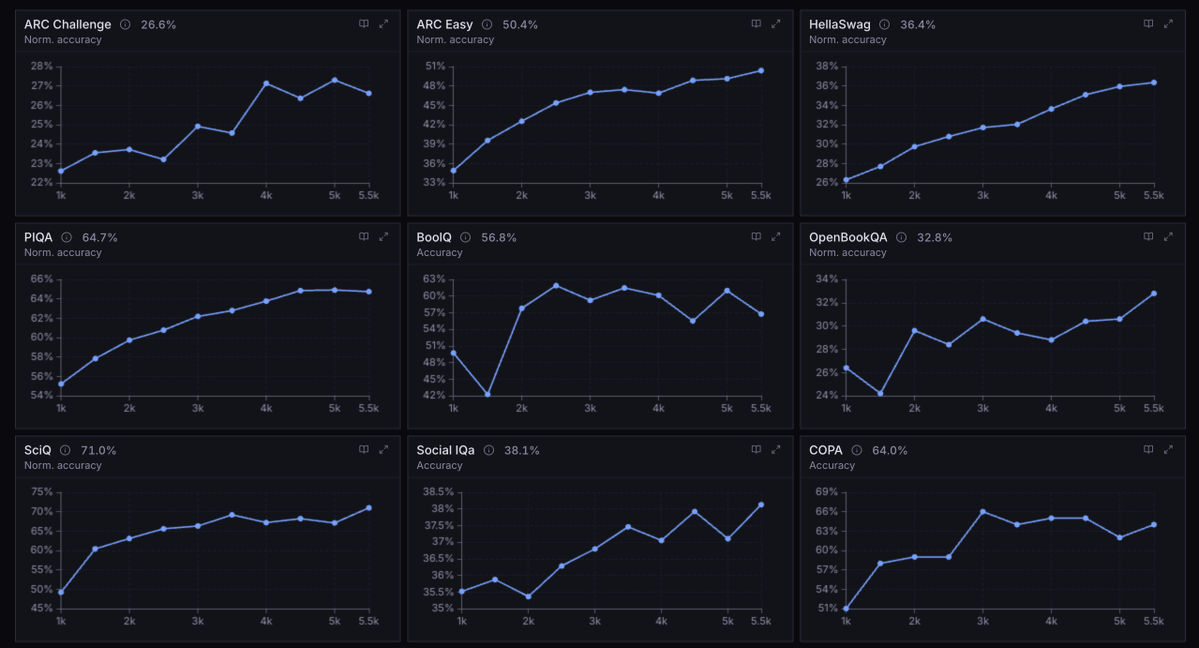
Each time we release a model, we run the same test: give it code that trains a small AI model, ask the new model to speed it up. It takes a skilled human 4-8 hours to reach 4x faster.
In May 2024, Claude Opus 4 averaged a ~3x speedup. This April, Mythos Preview achieved ~52x.
The next evolution of Hermes Agent is here!
Introducing Hermes Desktop: everything you love about Hermes, now native on your machine.
First demoed in Jensen's GTC keynote, it's now in public preview.
We have been working closely with @nvidia to ensure Hermes Agent works smoothly on their new @NVIDIARTXSpark superchip and integrates with the new OpenShell runtime, which connects Hermes to @Microsoft's security primitives.
Watch our feature in the big announcement at Computex:
DTCC and the Stellar Development Foundation announced today plans to enable the tokenization of DTC‑custodied assets on the @StellarOrg network. This collaboration advances DTCC’s multi chain strategy and expands how traditional assets move across digital ecosystems.
DTC‑tokenized assets are expected to be made available on the Stellar network in the first half of 2027, supporting the evolution of a more open, interoperable, and efficient financial ecosystem.
Get the full story: https://t.co/YCWHZDiLl5
AI has now solved a major open problem -- one of the best known Erdos problems called the unit distance problem, one of Erdos's favourite questions and one that many mathematicians had tried.
https://t.co/SD1vVPkrHR
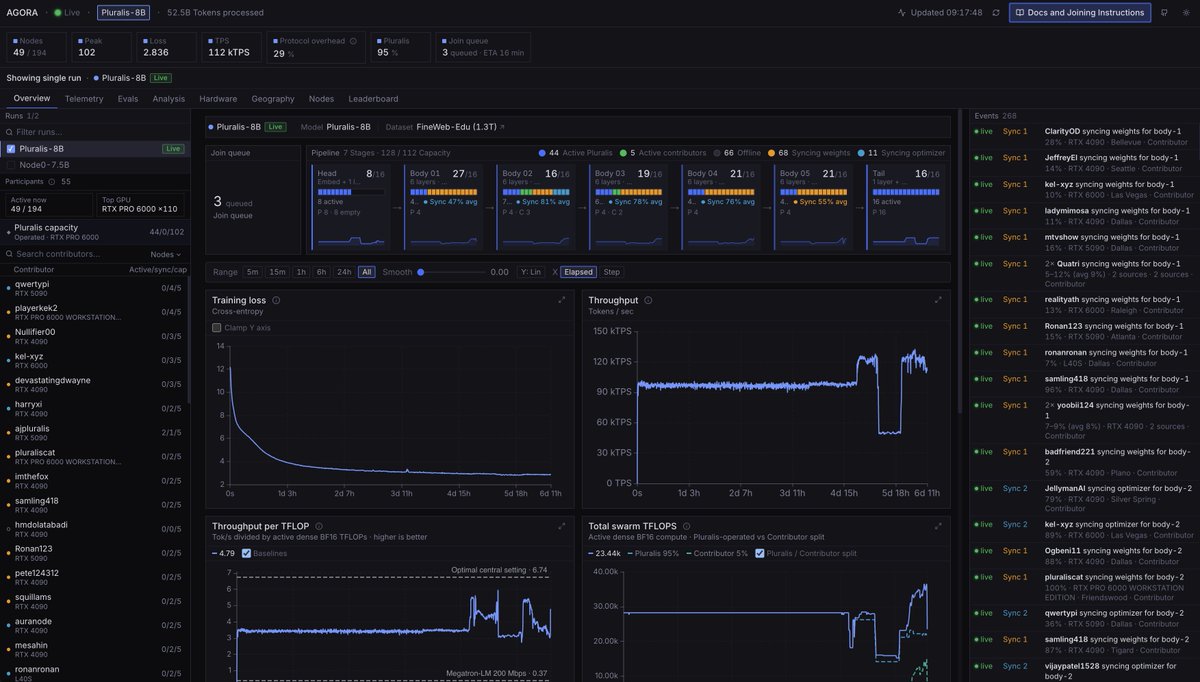
Today we're releasing Agora: the first ever pretraining stack that allows non-collocated consumer GPUs to be competitive with centralized clusters
Agora is 15x faster than Megatron-LM in this setting and is only 1.5x less efficient in terms of tokens per unit compute than TorchTitan on H100s, despite running on devices that have no NVLink or InfiniBand support.
My estimates are that Pluralis or Pluralis-like protocols can bring online about 4 GW of compute that is completely unusable for ML workloads today as it is not co-located.