MEDS is a rapidly growing standard to allow for rapid reproducible benchmarking and testing of AI models against full-form, time-series clinical data (e.g. EHR data) @NEJM_AI https://t.co/7nDVTX3vo4
Congrats to @AIHealthMIT PI Elazer @EdelmanLab for receiving the 2026-2027 Killian Award, @MIT's highest faculty honor! "He is a clinician of the highest order...a teacher of greatest passion...and an engineer whose work has reached around the globe." https://t.co/SJXamTelD0
The Stanford/EVOX lawsuit shows that academic AI datasets may carry serious “dataset debt” when copyrighted works were scraped, hosted and redistributed without clear permission.
https://t.co/CnID8gj920
Where would the field of clinical AI be without PhysioNet? 🎂 This year marks the 25th anniversary of one of the most comprehensive clinical data repositories in existence, best known for hosting datasets like MIMIC and the MIT-BIH Arrhythmia Database. https://t.co/YKhLL7uGj6
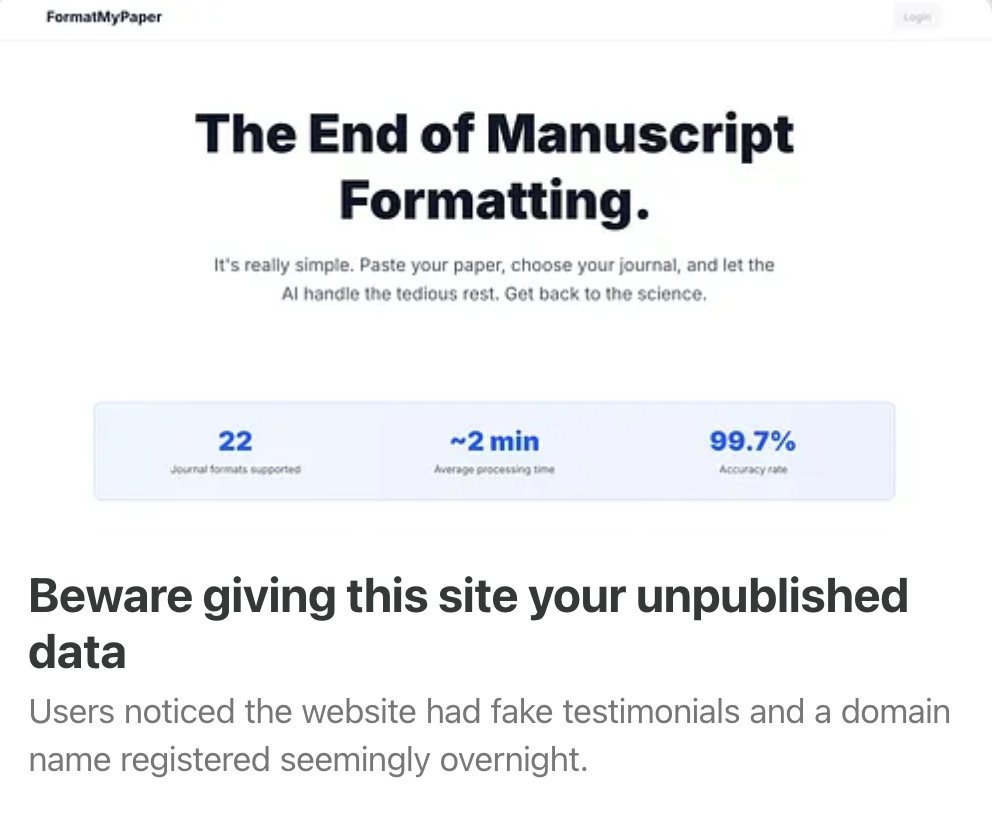
PSA: Many of you may have noticed a website floating around called formatmypaper(dot)com. People rightly noted something was fishy. I dig into what happened here: https://t.co/jGiBVlaTFe
Want to continue training an encoder on your own data, but not sure where to start?
Our step-by-step guide for reproducing the BioClinical ModernBERT training was just released!
1/5
Exciting to see BioClinical ModernBERT (base) ranked #2 among trending fill-mask models - right after BERT!
The large version is currently at #4.
Grateful for the interest, and can’t wait to see what projects people apply it to!
Very excited to share the release of BioClinical ModernBERT!
Highlights:
- biggest and most diverse biomedical and clinical dataset for an encoder
- 8192 context
- fastest throughput with a variety of inputs
- sota results across several tasks
- base and large sizes
(1/8)
We are excited to share an initial look at what we're building at Lila Sciences! At Lila, we are weaving together several exciting threads that have emerged in AI over the last several years: Highly-capable large language models, generative models of biomolecules and materials, and lab automation to create the next generation of AI models that can run the scientific method at scale.
We have assembled a world-class team of scientific and entrepreneurial leaders at this frontier including Geoffrey von Maltzahn, George Church, Rafael Gómez Bombarelli, Molly Gibson, Kenneth Stanley, John Gregoire, and Jacob Feala!
If you're excited about joining a team that is scaling reasoning models for some of the most important problems in life and physical sciences, please reach out! You're colleagues will be some of best ML scientists I have ever met at this intersection.
Come work with us and push the frontier of what is possible for science.
Link to more below!
Only 10 days left to apply to the AHLI CHIL Doctoral Symposium! Are you a PhD student looking for valuable feedback and mentorship on your work? This is the place for you. Call for papers: https://t.co/7VrDzorLY0
#CHIL2025
🎉 We're thrilled to announce the general release of three de-identified, longitudinal EHR datasets from Stanford Medicine—now freely available for non-commercial research-use worldwide! 🚀
Read our HAI blog post for more details: https://t.co/gKLmwZhvLE
𝗗𝗮𝘁𝗮𝘀𝗲𝘁 𝗦𝘂𝗺𝗺𝗮𝗿𝗶𝗲𝘀
📊 3 longitudinal EHR datasets
👥 Scale: 25,991 patients, 441,680 visits, and 295M clinical events (median: 4,882 events per patient)
⏳ Timeframe: Patient trajectories from 1997 to 2023 (median: 10 years per patient)
𝗦𝘁𝗮𝗻𝗱𝗮𝗿𝗱𝗶𝘇𝗲𝗱 𝗕𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸 𝗧𝗮𝘀𝗸𝘀
🎯 Few-shot Learning
🤖 Multimodal Learning & Time-to-Event Modeling
⌛ Long Context Instruction Following & Temporal Reasoning
Thanks to @MichaelWornow, Ethan Steinberg, @Zepeng_Huo, @HennyJieCC , @BediSuhana42170 , @AlyssaUnell, @drnigam@StanfordMed
⚠️ Only 2 weeks left to submit to CHIL! ⚠️
We're seeking cutting-edge papers on machine learning + health, covering topics from generative modeling to health policy, and more!
Check the full scope: https://t.co/t7bRi7Nhmg.
Don't miss your chance to contribute to #CHIL2025!
$1 million dollars up for grabs from @NIH for the teams that come up with the best measures of research data sharing, also known as a Data Sharing Index (S-index)! https://t.co/9i7SFPN0qb HT @NEIDirector
We’re excited to make this year’s CHIL research roundtables as engaging and valuable as possible. To do that, we’d love your input on discussion topics & your interest in leading a roundtable or volunteering as a notetaker. Help us out here:✍️https://t.co/fyqEIKuDI8
We hope STANDING Together helps everyone across the AI development lifecycle to make thoughtful choices about the way they use data, reducing the risk that biases in datasets feed through to biases in algorithms and downstream patient harm.
https://t.co/Q0RHoUqnOF
(10/
These recommendations are the culmination of nearly 3 years of work by an international group of researchers, healthcare professionals, policy experts, funders, medical device regulators, AI/ML developers, and many more besides.
(9/
STANDING Together = STANdards for data Diversity, INclusivity and Generalisability.
We have worked with >350 stakeholders from 58 countries to agree a set of recommendations to improve the documentation and use of health datasets.
(8/