🚨 @Bitwarden serait en train de subir une refonte discrète et inquiétante, sans aucune communication officielle. 🤔
👉🏼Le fondateur/ancien PDG Michael Crandell a été remplacé en février par un nouveau CEO (Michael Sullivan) dont la spécialité est les fusions-acquisitions et le private equity (il a géré des deals à 1 milliard $). Le CFO a aussi été changé.
👉🏼Le slogan « Always free » a disparu du site en avril. Le plan gratuit existe encore… pour l’instant.
👉🏼Les valeurs de l’entreprise (GRIT) ont été modifiées : Inclusion et Transparency ont été supprimées au profit de Innovation et Trust. L’annonce ? Un simple edit silencieux d’un vieux billet de blog de 2022 qui se contredit maintenant.
👉🏼Tout est fait en douce : pas de communiqué, pas de blog post, juste des changements enterrés.
L’auteur [source en commentaire], qui utilisait Bitwarden cloud, a déjà tout migré sur Vaultwarden, la version self-hosted.
Il voit un schéma classique : on gagne la confiance, on crée la dépendance, puis on change les règles petit à petit en vue d’une vente ou d’une exit (probablement à un gros acteur).
Risque pour les utilisateurs : le modèle open source et le self-hosting pourraient être fragilisés à terme (même si ce n’est pas immédiat).
Il conseille de passer à une instance personnelle tant que c’est encore facile.
En résumé : Bitwarden passe d’un projet communautaire à une boîte gérée comme une startup PE prête à être vendue.
Le gratuit et la transparence ne sont plus des priorités affichées.
Concours 🎁 27 Ans TopAchat
🔥 + 37 000 € de cadeaux à gagner !
On termine avec le Setup Final d'une valeur de 5503€ !
@AORUS_France
Pour participer :
➡ Follow @TopAchat
🔁 RT ce tweet
💬 Dis ce que tu préfères en commentaire avec #27AnsTopAchat
🔖 Save ce post pour retrouver facilement l'annonce du gagnant !
Participe aussi ici ⬇
https://t.co/ydKRD5NakB
🍀 TAS le 18/05 à 12h
Concours 🎁 27 Ans TopAchat
🔥 + 37 000 € de cadeaux à gagner !
Place au Setup 6 de 4883€ !
@SamsungFR
Pour participer :
➡ Follow @TopAchat
🔁 RT ce tweet
💬 Dis ce que tu préfères en commentaire avec #27AnsTopAchat
🔖 Save ce post pour retrouver facilement l'annonce du gagnant !
Participe aussi ici ⬇
https://t.co/ydKRD5NakB
🍀 TAS le 11/05 à 12h
Concours 🎁 27 Ans TopAchat
🔥 + 37 000 € de cadeaux à gagner !
C'est reparti avec le Setup 5 de 4073€ !
@noblechairsFR
Pour participer :
➡ Follow @TopAchat
🔁 RT ce tweet
💬 Dis ce que tu préfères en commentaire avec #27AnsTopAchat
🔖 Save ce post pour retrouver facilement l'annonce du gagnant !
Participe aussi ici ⬇
https://t.co/ydKRD5MCv3
🍀 TAS le 07/05 à 12h
Claude Code doesn't show you how many tokens you're using for subscriptions. No breakdown by model. No breakdown by project. Just a progress bar that says "63% used."
So I built a local dashboard that reads the files Claude Code already writes to your machine.
Turns out every session, every turn, every token is logged to ~/.claude/projects/ in JSONL files. Input tokens, output tokens, cache reads, cache creation, model name, timestamp.
It's all there. You just can't see it.
My numbers over the last 30 days: 440 sessions. 18,000 turns. $1,588 in API-equivalent costs. On one day, the cache spiked to 700M tokens - visible cache bug, two days in a row.
The dashboard scans those local files, builds a SQLite database, and serves charts on localhost:8080. Filter by model (Opus, Sonnet, Haiku). Filter by time range (7d, 30d, 90d, all time). Cost estimates based on current Anthropic API pricing.
Works retroactively. First run processes your entire Claude Code history.
Install:
git clone https://t.co/BKyUCxi8Cq
cd claude-usage
python3 https://t.co/O3rvjobdvx dashboard
Windows: use python instead of python3.
Zero dependencies. Python standard library only.
Open source, MIT.
Star it. Fork it. Make it your own.
Anthropic vient de fuiter accidentellement le code source entier de Claude Code.
Deuxième fuite majeure en une semaine. Et cette fois, c'est bien pire.
Ce qui s'est passé :
Mardi 31 mars à 4h du matin, une mise à jour de routine de Claude Code (version 2.1.88) a été poussée sur npm, le registre public que les développeurs utilisent pour télécharger des logiciels.
Problème : un fichier de débogage a été accidentellement inclus dans le package. Ce fichier pointait vers une archive zip hébergée sur le stockage cloud d'Anthropic contenant le code source complet.
1 900 fichiers. Plus de 512 000 lignes de code. Tout.
Un chercheur en sécurité, Chaofan Shou, l'a repéré en quelques minutes et a posté le lien de téléchargement sur X. Le temps que l'équipe d'Anthropic se réveille, le code avait déjà été copié et dupliqué partout sur GitHub. Plus de 41 500 forks.
Anthropic a envoyé des demandes DMCA pour supprimer les repos. Des développeurs ont alors réécrit le code en Python depuis zéro — une réécriture complète qui est une œuvre nouvelle, donc intouchable par le DMCA. Le repo a explosé en popularité.
Ce que la fuite révèle :
→ Une architecture mémoire à 3 couches qui explique pourquoi Claude Code est si fiable sur les longues sessions
→ Un mode "Undercover" qui efface toute trace d'IA dans les commits Git publics
→ Un mode daemon autonome nommé "KAIROS" : Claude Code travaille en arrière-plan pendant que l'utilisateur est inactif
→ Les noms de code internes des modèles : Capybara (Claude 4.6), Fennec (Opus 4.6), et un modèle non publié nommé "Numbat"
→ Des dizaines de fonctionnalités entièrement construites mais pas encore déployées
Claude Code génère à lui seul environ 2,5 milliards de dollars de revenus annuels. 80% viennent des entreprises.
Anthropic a confirmé la fuite : "Erreur humaine, pas une faille de sécurité. Aucune donnée client exposée."
L'ironie est brutale : la boîte qui se positionne comme le labo IA "safety-first" a fuité son propre code source. Une semaine après avoir fuité son propre brouillon de blog sur son modèle le plus puissant.
Le code est dans la nature. Chaque concurrent a désormais un cours gratuit sur comment construire un agent de code IA de niveau production.
La course à l'IA vient de perdre un peu de son mystère.
Coucou, j'ai mis à jour l'outil avec désormais + de 2000 prompts répartis dans 42 professions/occupations (puisque j'ai ajouté sur vos conseils "Président de La République" et "Conspirationniste"
👉https://t.co/BudkWwpPtU
Il y a désormais aussi un champ de recherche pour chercher dans toutes les professions et les prompts directement.
Et oui, c'est Claude Code qui m'a bien aidé à le faire, mais il s'est nourri de centaines de documents à moi pour construire ceci.
Google vient de publier un papier qui compresse les LLMs à 3 bits. 8x plus rapide, 6x moins de mémoire. Zéro perte de performance 🤯🤯🤯
Le truc c'est que la méthode est élégante au point d'en être presque triviale une fois qu'on la comprend.
Ça s'appelle TurboQuant. Je vous vulgarise tout le paper :
Déjà, le problème de base.
Quand un LLM génère du texte, il doit se "souvenir" de tout ce qu'il a lu et écrit avant. Ce système de mémoire s'appelle le KV cache (key-value cache).
Imaginez un étudiant qui prend des notes ultra détaillées pendant un cours. Plus le cours est long, plus ses notes prennent de place sur son bureau. À un moment il n'a plus de place pour écrire.
C'est exactement ce qui se passe avec les LLMs : plus le contexte est long, plus le KV cache explose en mémoire. C'est un des plus gros bottlenecks de l'inférence aujourd'hui.
La solution classique c'est la quantization. L'idée est simple : au lieu de stocker chaque nombre avec une précision extrême (32 bits, genre 3.14159265...), tu le stockes avec moins de précision (4 bits, genre "~3").
C'est comme passer d'une photo RAW de 50 MB à un JPEG de 2 MB. Tu perds un peu de détail mais visuellement c'est quasi pareil.
Le problème c'est que les méthodes classiques de quantization trichent un peu. Pour chaque petit bloc de données compressé, elles doivent stocker des "constantes de calibration" en pleine précision.
C'est comme si pour chaque photo JPEG vous deviez garder un petit post-it en haute résolution à côté qui dit "voilà comment décoder cette image".
Ces post-its rajoutent 1 à 2 bits par nombre. Quand tu essaies de compresser à 2 ou 3 bits, cet overhead représente une part énorme de ta mémoire totale. Ça annule une bonne partie du gain.
TurboQuant résout ça en deux étapes.
Étape 1 : PolarQuant.
Au lieu de décrire un vecteur avec des coordonnées classiques (X, Y, Z), tu le convertis en coordonnées polaires : une distance + un angle.
C'est comme remplacer "va 3 rues à l'est puis 4 rues au nord" par "va 5 rues direction 37 degrés". Même info, format plus compact.
L'astuce c'est qu'avant de faire ça, tu appliques une rotation aléatoire sur tes vecteurs. Ça rend leur distribution prévisible et uniforme. Du coup tu n'as plus besoin de stocker les fameuses constantes de calibration, la géométrie fait le travail toute seule.
Étape 2 : QJL (Quantized Johnson-Lindenstrauss).
Après PolarQuant il reste une petite erreur résiduelle. QJL la corrige avec 1 seul bit par nombre.
Le principe vient d'un théorème mathématique qui dit qu'on peut projeter des données de haute dimension dans un espace plus petit tout en préservant les distances entre les points.
QJL pousse ça à l'extrême : il réduit chaque valeur projetée à juste son signe (+1 ou -1). Un seul bit. Et grâce à un estimateur spécial qui combine la query en haute précision avec ces données ultra compressées, le modèle calcule toujours des scores d'attention précis.
Les résultats sont assez dingues.
Sur les benchmarks long-context (LongBench, Needle in a Haystack, RULER...) avec Gemma et Mistral : zéro perte de performance à 3 bits. Le KV cache est réduit d'un facteur 6x. Et sur H100, le calcul des scores d'attention est jusqu'à 8x plus rapide qu'en 32 bits.
Le tout sans aucun fine-tuning ou entraînement supplémentaire. Tu branches, ça marche.
Et le plus intéressant : ça ne sert pas qu'aux LLMs.
TurboQuant surpasse aussi les méthodes state of the art en vector search, c'est à dire la techno qui permet de chercher par similarité dans des bases de milliards de vecteurs (ce qui fait tourner Google Search, les systèmes de recommandation, le RAG...).
Mon take : l'inférence c'est là où se joue la vraie bataille économique de l'AI.
Les marges de toute l'industrie dépendent du coût par token en production. Un gain de 6 à 8x sur la mémoire et la vitesse d'inférence, sans aucune perte de qualité, ça change fondamentalement l'équation.
Ce type de recherche ne fait pas de bruit sur Twitter mais son impact business est potentiellement supérieur à celui d'un nouveau foundation model.
Stop burning tokens on Claude Code.
Use this instead 👇
A free GitHub repo (80K⭐) that turns your CLI into a high-performance AI coding system.
Link → https://t.co/XVvfJvrJvE
Why it’s different:
→ Token optimization
Smart model selection + lean prompts = lower cost
→ Memory persistence
Auto-save/load context across sessions
(No more losing the thread)
→ Continuous learning
Turns your past work into reusable skills
→ Verification loops
Built-in evals to make sure code actually works
→ Subagent orchestration
Handles large codebases with iterative retrieval
Most people think Claude struggles with complex repos.
It doesn’t.
They’re just not using the right setup.
This fixes that.
Bookmark this for your AI stack. ♻️
#AI #Claude #AIAgents #LLM #GenAI #DevTools
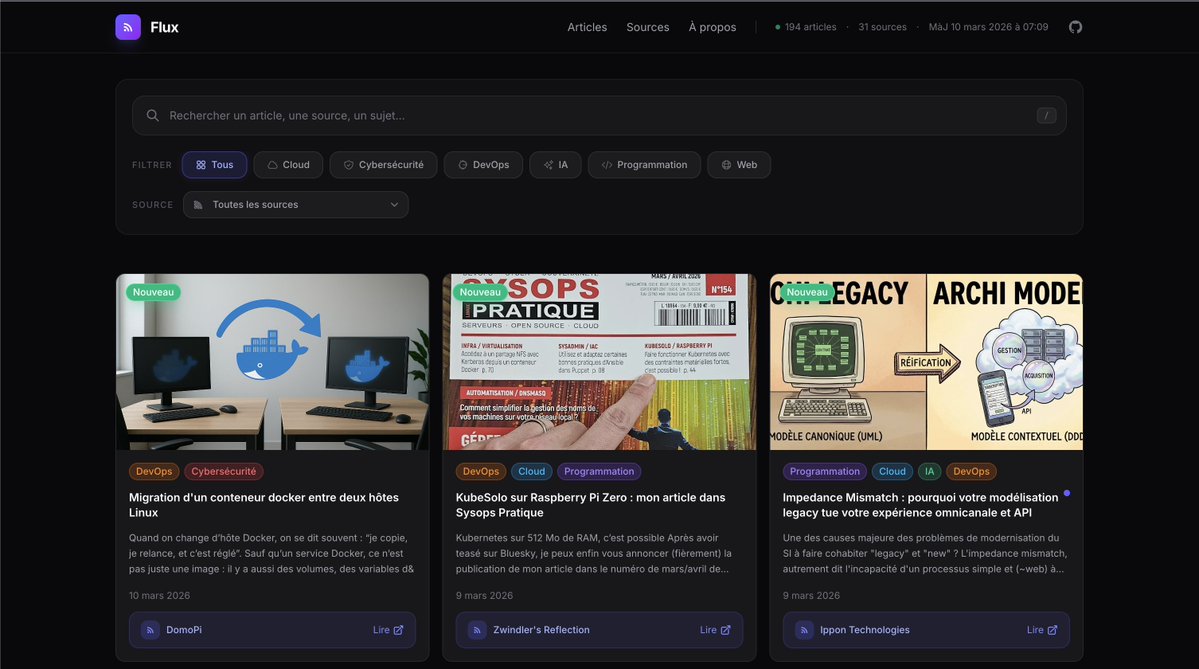
Je vous présente Flux.
Flux, c'est mon outil de veille, débarrassé des recommandations algorithmiques des réseaux sociaux avec une trentaine de flux RSS francophones Tech/Dev/Ops/IA.
C'est une sélection perso, il manque forcément des gens très bien.
https://t.co/1a2yVcHC2y
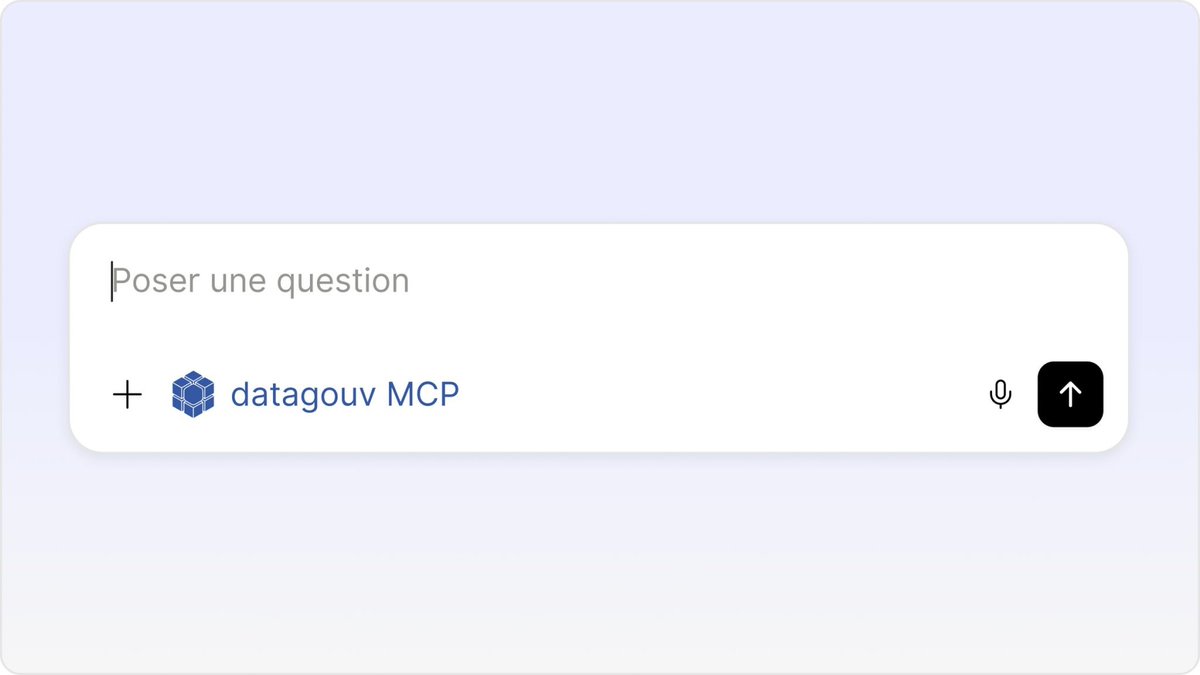
Les données disponibles sur https://t.co/Yz6AmwMTfb sont désormais interrogeables via un serveur MCP dédié en experimentation, vos retours sont bienvenus !
💻 Le code est ouvert et accessible sur GitHub :
https://t.co/AmY04V22TH
Pour en savoir plus : https://t.co/V7UJrc6uUq
Opus 4.6 vient de sortir avec 6 nouveautés majeures. Voici le résumé en 30 secondes 👇
1. Agent Teams : des équipes d'IA qui bossent en parallèle sur ton projet. Un lead coordonne, les agents se parlent entre eux.
→ settings.json → claude_code_allow_agent_teams = true
2. Adaptive Thinking : tu choisis l'intensité de réflexion (low, medium, high, max). Fini de deviner le budget tokens.
→ /model + flèches gauche/droite dans Claude Code
3. Interleaved Thinking : le modèle réfléchit entre chaque appel d'outil au lieu d'une seule fois au début. Moins d'erreurs en chaîne.
→ Activé automatiquement avec Adaptive Thinking
4. 1M tokens de contexte : analyse des bases de code entières. Première fois sur un Opus.
→ Je te montre dans la vidéo comment l'activer
5. Mémoire persistante : Claude se laisse des notes entre les sessions dans .claude/project/memory/memory.md
→ Activé par défaut
6. Context Compaction : les anciens messages sont résumés automatiquement quand la conversation devient trop longue.
→ Activé par défaut
La vidéo complète 👉 https://t.co/swMO0BXkuZ
Anthropic ont sorti un guide de 33 pages sur l'écriture des skills.
5 points importants :
> Skills = dossiers structurés qui enseignent à Claude des workflows précis
> Architecture en trois niveaux pour éviter de surcharger le contexte
> Dans l'idéal donne un trigger clair sous forme de commande "/"
> Une fois le skill terminé : effectuer teste de déclenchement + résultats + performance
> Respecte le format d'entrée attendu par le skill (si tu dois lui donner des logs bruts donne lui des logs bruts etc..)
En ce moment je monte des WAF pour mes clients, j’avais besoin d’une solution facile et rapide pour tester et démontrer l’utilité avec mes clients ..
Du coup, j’ai dev cette solution, et évidemment, c’est en open source et disponible pour tous !
🔥 https://t.co/MHR46UME0Q
🎁 CONCOURS 🎁Un setup à 7 600€ à gagner ! #30ansLDLC
Pour participer :
▪ FOLLOW @LDLC
▪ RT CE TWEET
💻 La config en détails👉 https://t.co/DZQyAksy7p
📢 Joue aussi sur Instagram, Facebook et dans tous nos magasins pour multiplier tes chances.
Bonne chance ! 🍀
🥳TAS le 10/02/2026
Concours 🎁 Petit Papa TopAchat 🎄
🔥 + 34 000 € de matos à gagner !
Place au Setup Final de 4733€ !
Pour participer :
🔁 RT ce tweet
➡ Follow @TopAchat
💬 Commente avec #PetitPapaTopAchat
Participe aussi ici ⬇
https://t.co/P9SiyHUTTx
🍀 TAS le 29/12 à 12h
@AORUS_France

























![Lab312_'s tweet photo. 🚨 @Bitwarden serait en train de subir une refonte discrète et inquiétante, sans aucune communication officielle. 🤔
👉🏼Le fondateur/ancien PDG Michael Crandell a été remplacé en février par un nouveau CEO (Michael Sullivan) dont la spécialité est les fusions-acquisitions et le private equity (il a géré des deals à 1 milliard $). Le CFO a aussi été changé.
👉🏼Le slogan « Always free » a disparu du site en avril. Le plan gratuit existe encore… pour l’instant.
👉🏼Les valeurs de l’entreprise (GRIT) ont été modifiées : Inclusion et Transparency ont été supprimées au profit de Innovation et Trust. L’annonce ? Un simple edit silencieux d’un vieux billet de blog de 2022 qui se contredit maintenant.
👉🏼Tout est fait en douce : pas de communiqué, pas de blog post, juste des changements enterrés.
L’auteur [source en commentaire], qui utilisait Bitwarden cloud, a déjà tout migré sur Vaultwarden, la version self-hosted.
Il voit un schéma classique : on gagne la confiance, on crée la dépendance, puis on change les règles petit à petit en vue d’une vente ou d’une exit (probablement à un gros acteur).
Risque pour les utilisateurs : le modèle open source et le self-hosting pourraient être fragilisés à terme (même si ce n’est pas immédiat).
Il conseille de passer à une instance personnelle tant que c’est encore facile.
En résumé : Bitwarden passe d’un projet communautaire à une boîte gérée comme une startup PE prête à être vendue.
Le gratuit et la transparence ne sont plus des priorités affichées.](https://pbs.twimg.com/media/HIoEjkUXoAAbn9S.png)