@NielsRogge@YesThisIsLion@MLStreetTalk If you put polar coordinates into your MLP it will also learn to extrapolate the spiral. The M-Layer is just a particularly suited inductive bias for this problem, in other domains it doesn't look that impressive.
Our new paper shows that RoPE—the positional encoding used in most modern LLMs like Qwen, Gemma, DeepSeek—has a fundamental flaw: it entangles "what" (content) and "where" (position) information.
Our fix (PoPE) is simple but powerful. Paper: https://t.co/XlltfcSwHQ
Recursive reasoning beats multi-billion-parameter models
You can now easily train your own 7M param model from scratch and outperform DeepSeek-r1 on ARC-AGI 1
We provide a simple speedrun script that handles setup, training, and eval in one go.
Stronger Normalization-Free Transformers – new paper.
We introduce Derf (Dynamic erf), a simple point-wise layer that lets norm-free Transformers not only work, but actually outperform their normalized counterparts.
Larry Page & Sergey Brin had the PageRank paper (the algorithm behind Google Search) rejected. A reviewer called it “disjointed.”
Geoffrey Hinton's Dropout was rejected for being “too simple.”
I often feel the academic peer review is like a random process, especially when a paper is very innovative and changes the paradigm; it often looks "wrong" to reviewers in the old paradigm.
Interesting read from the ARChitects, 2nd place team on @arcprize competition on @kaggle .
Their combination of diffusion LLMs with iterative improvement is quite interesting. It has some ties with TRM and HRM models.
There is some irony thoough. They tried something different from their winning solution from last year because they thought it was not successful. Irony is we won reusing their last year solution (with some improvements). Key for us was to use better pretraining data.
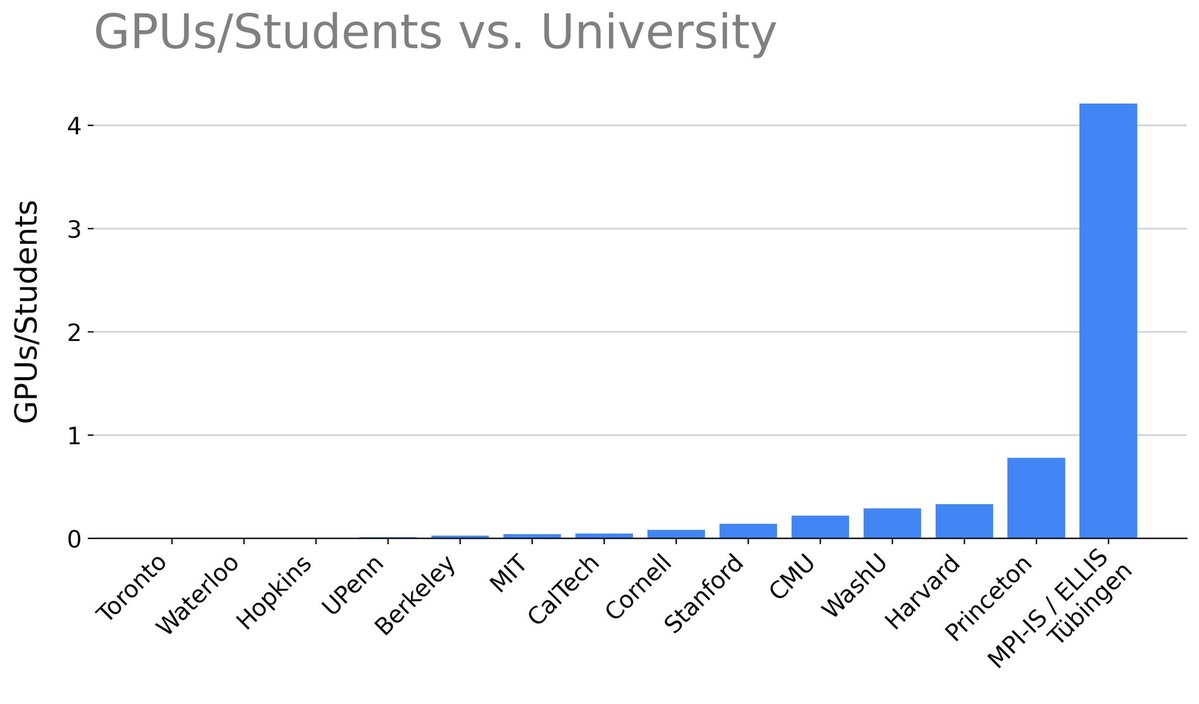
You can wait for the academic compute crisis to get solved 🥱 or...
Just come to Tübingen for the:
1) Compute
2) Talent Density
3) Aesthetics, in research, workspaces, and the city as a whole
(Job) Markets are not efficient ;)
@FrancoisChauba1's plot extended by @nikhilchandak29
Ok, let us complain about OpenReviewer's latest saga!
As you are aware, reviewer names have been leaked, including mine and yours, likely.
I think OpenReview and the conferences are trying their best to come up with solutions. I salute them for that! Thank you for the hard work on this. I know it must be very tough!
I came to learn that the distribution of reviewers is funny and weird. I kid you not, MSc and BSc students review at those top-tier conferences. I thought it was a myth, but it is not 🤓
Let us get some people upset! But, at least, let us be honest.
Now let me tell you what is wrong with that:
1️⃣ MSc and BSc students, bright as they may be, are not experts in their fields. I think it is very awkward for senior researchers and professors to work their butt off to please students who are newbies to the field, and most of the time don't understand the papers well.
Don't get me wrong, I am sure they put HUGE effort, but effort is just effort! It is not understanding!
It might now become clearer to all of us why we get reviews like do 1000 more experiments, some weird comments - well, they don't know better.
2️⃣ The above would have been OK if they had actually listened and learned during the rebuttal process. But think about it! If you are an MSc and BSc reviewer, would you ever dare to admit you were wrong? It is a big deal for you; you want to propel your career, so how can you step back from claiming something outrageous?
How mature as a researcher are you to suggest improvements to papers that have been worked on with people with over 10-15 years of experience?
Heck, imagine someone did what you want to build your career on when you are still a BSc or MSc student. Wouldn't you simply reject it since it beats you to it?
3️⃣ Students tend to over-index on surface-level details because coursework trains them to prioritise correctness, completeness, and hyper-specific checklists. As a result, their reviews often fixate on typos, notation, formatting, and endless abstractions rather than the substance of the contribution. The entire evaluation becomes a grading exercise, not a scientific one, and the core ideas of the paper get lost.
4️⃣ Students often rely on intuition or “common sense” because they haven’t yet internalised the techniques, math, empirical tricks, and failure modes of the field.
But top-tier research requires theory-backed judgment, statistical intuition, and the ability to separate real signal from noise. Those instincts take years to develop, and it's unfair to expect students to have them while evaluating frontier work.
So less mathy papers and benchmarks rise to the top, and mathy ones get rejected.
... so yeah, it doesn't make any freaking sense.
#openreview
Be me
Submit new SOTA to @iclr_conf
Reviews 8,4,4,4 Schrödinger's accept
Enter rebuttal arc, sleep schedule and will to live overfitted to this one decision
OpenReviewer rolls nat 1
Committee pushes global reset
Paper enters timeline where I hadn’t sacrificed my mental health
Clearly a pivotal moment where we need to rethink peer review. Some thoughts:
1. I have been an advocate of fully non-anonymous peer review. On one hand, people will be careful about what they write but on the other hand, most people will just not sign up for reviewing.
2. Conferences have badly failed at scaling peer review. This has been an issue at least since 2019 where I remember AAAI had close to 9k submissions. It's not possible to have 24k papers submitted per major conference and have them well reviewed.
3. At this point the review signal is extremely noisy and what determines acceptance is whether you can "trick" 3 people into following your narrative. Submit a decent paper enough times and it will get accepted.
4. There are way too many niches and too many papers coming out daily. I don't think anyone is up to date anymore. Therefore anyone reviewing your papers is likely not in a position to make a good judgement.
5. The competition due to artificially low acceptance rates is so intense that it's not unnatural for a reviewer to see any paper they are reviewing as a threat. This combined with point 4 means that the reviews will either be shallow or adversarial, both useless.
6. Clearly AI reviews are here to stay so best if we invest in proper infra and training so that people use AI ethically and appropriately and thus help repair peer review.
Now is the time!
@hive_echo The spiral example seems kind of selected for this problem since the inductive bias of the M-Layer is polynomial decomposition and regularizing for simple polynomials gives you a sort of rotation matrix. If you train an MLP in polar coodinates you get the same extrapolation.
I am an AC for ICLR 2026. One of the papers in my batch was just withdrawn. The authors wrote a brief response, explaining why the reviewers failed at their job. I agree with most of their comments. The authors gave up. They are fed up. Just like many of us. I understand. We pretend the emperor has clothes, but he is naked.
Here is the final part of their withdrawal notice. I took the liberty to make it public, to highlight that what we are doing with AI conference reviews these last few years is, basically, madness.
---
Comment: We thank the reviewers for their time.
However, upon reading the reviews for our paper, it became immediately apparent that the four "reject" ratings are not based on good-faith academic disagreement, but on a critical failure to read the submitted paper.
The reviews are rife with demonstrably false claims that are directly contradicted by the text. The core justifications for rejection rely on asserting that key components are "missing" when they are explicitly detailed in the manuscript. Some specific examples are (and many are even fake claims).
Claim: Harder tasks like GSM8K are missing.
Fact: GSM8K results are in many tables, like Table 2 (Section 4.2) and Appendix G.
Claim: The method does not use per-layer ranks.
Fact: This is the entire point of our method. The reviewer clearly mistook our method for the baselines. (Section 2, Table 1).
Claim: The GP kernel is not specified.
Fact: It is specified in Appendix E (Table 6).
Claim: There is no ablation of the method's three stages.
Fact: Section 4.4 ("Ablation Study") and Appendix J are dedicated to this.
Reviewers have a fundamental responsibility to read and evaluate the work they are assigned. The nature of these errors is so fundamental, so systemic in overlooking explicit content, that it goes far beyond what "limited time" or "oversight" can explain. This work has gone through several rounds of revision over the last year. In earlier submissions, the paper usually received borderline or weak-accept scores.
Numerous signs strongly suggest that some reviewers are relying entirely on AI tools to automatically generate peer reviews, rather than fulfilling their fundamental responsibility of personally reading and evaluating manuscripts.
We strongly protest this.
This is a gross disrespect to the authors. It is a flagrant desecration of the reviewer's sacred duty. It fundamentally undermines the integrity of the entire peer-review process.
Given that the reviews are not based on the actual content of our paper, we have decided to withdraw the submission.
We leave this comment so that future readers of the OpenReview page are aware that the items described as "missing" are already present in the submitted manuscript. These negative reviews for this submission are factually unsound and do not reflect the content of the paper. We cannot and will not accept an assessment that is not based on the work we actually submitted.
Food for thought about how our brain does it, that is, THINK -- and how it thereby uses CONTEXT INFERENCE to not get overwhelmed but to focus on what seems relevant -- consider reading our new review paper on "Contextualizing Predictive Minds" #Context
Want to know how to machine-learn contextualized, compositional world models from sensorimotor experiences and use them for planning and RL? Our #ICLR2024 spotlight paper provides an answer.