Today a crazy quantum story just got wilder.
On March 31, the Google Quantum AI team published a landmark result on Shor's algorithm for elliptic curve cryptography. Technically, the paper was a bombshell: a dramatic 10x improvement over the state-of-the-art. As a stunt and wakeup call to the blockchain space, those optimisations were illustrated on secp256k1, the elliptic curve underlying Bitcoin and Ethereum signatures.
But perhaps the most striking part of the paper was sociological, not technical. Instead of following standard academic process, the optimisations were kept secret, hidden behind a zero-knowledge (ZK) proof. Google's accompanying blog post mentions they "engaged with the U.S. government". The ZK proof demonstrates the existence of algorithmic improvements without leaking details. Academic censorship with ZK, a historic first!
As a co-author of the Google paper I witnessed some of the context surrounding this censorship. To be honest, multiple aspects of that context don't sit well with me. As much as I believe the general public ought to know more, I am limited in my ability to whistleblow. Though let me be clear about one thing: the Google team's professionalism has been absolutely exemplary, and they deserve nothing but praise.
Censorship has a way of backfiring. The Streisand effect, where an attempt to bury something only draws more attention to it, is exactly what's unfolding today. First, Google's key optimisation has been rediscovered by the French. And in a thrilling turn of events, a collaborative Shor-at-home challenge just launched. The initiative, available at ecdsa[.]fail, breached a new Shor world record in a matter of hours.
Let's start with the rediscovery. Just two months after Google's paper, French quantum expert André Schrottenloher cracks the main secret optimisation. His paper, titled "Optimized Point Addition Circuits for Elliptic Curve Discrete Logarithms", landed on the arXiv today. Big congrats to André, who beat several other nerdsnipped experts to it. In a blog post also published today, Craig Gidney, the world expert on Shor optimisations, revealed that he'd been sitting on this very optimisation for a whole year under censorship pressure.
Interestingly, André missed a handful of minor optimisations, both from Google's original publication and from improvements found since. It's plausible there's still plenty of juice left to squeeze out of Shor, and this is exactly what the ecdsa[.]fail challenge is about. The verifier program developed for the ZK proof does double duty, automatically filtering for valid submissions. Dozens of compounding small and micro improvements are rolling in. As of the time of writing there's an 8.4% improvement to Google's circuit, as measured by the product of logical qubit count and Toffoli gate count. Nice!
The nerdsnipping ran deeper than anyone expected. Over the last few weeks it became clear it extended well beyond André and other quantum experts. Behind the scenes, a small army of amateurs quietly got to work. Inspired by Karpathy-style autoresearch, they turned AI on Shor. Ironically, the verifier program for the ZK proof makes an ideal reward function for AIs. The barrier to entry for this modern style of research is refreshingly low, with several non-experts, even a teenager, finding nice optimisations. Get in touch if you'd like to join a Telegram group with fellow autoresearchers :)
Part 2: neutral atoms and qday
The story doesn't end with Google. On the same day Google went public, a stealthy startup called Oratomic published its own Shor paper in a coordinated release. It made a splash, ultimately becoming the most upvoted paper on scirate[.]com, a website ranking arXiv papers.
Oratomic's claim was wild. By building on Google's logical optimisations and applying custom physical optimisations for neutral atoms, they claimed just 10K physical qubits were sufficient to run Shor's algorithm on secp256k1. That number is mind-bogglingly low.
Knowing essentially nothing about neutral atoms when Oratomic's paper landed, I was intrigued and decided to learn more about the tech. I fell straight down the rabbit hole and spent a couple hundred hours on the topic. I got a little obsessed and watched every YouTube video I could find and spoke to a bunch of experts.
My conclusion? The tech is real, very real. Even Google recently decided to start a neutral atom lab, a notable pivot from their sole focus on superconducting qubits. If you care about qday, i.e. the day a quantum computer will break the first piece of cryptography in production, neutral atoms demand your attention. I shared some of my learnings on Shor and neutral atoms in a 30min talk at the ZKProof cryptography conference. You can find it on YouTube by searching "zkproof neutral atom".
Here's an interesting observation about this duo of breakthrough papers: neither Google nor Oratomic say a word about what their results mean for qday. No timelines. Zero. Nada. That is especially baffling given that the whole point of whitehat quantum cryptanalysis is to inform qday estimations and help the general public make good decisions.
So let me attempt to partially fill the silence, similarly to what Scott Aaronson did in his April 29 post. Given everything I know, including scary non-public information, I now put the odds of qday by 2032 at 50%. 10% by 2030.
Anecdotally, the US government has its own date: 2035. Originating at the NSA and later adopted by NIST, it's when branches of the US government will be disallowed from using quantum-vulnerable cryptography. In plain language: with hindsight, that date is a joke and should be discounted entirely. I don't see how NIST avoids being forced to pull it forward by years.
Part 3: post-quantum cryptography
There are good reasons to sound the alarm today, but please do not panic. Rushing carelessly towards immature post-quantum cryptography is a recipe for disaster. IMO a good target date for migration is 2029, roughly 3.5 years out. 2029 happens to be the date selected by Google, Cloudflare, and the Ethereum Foundation.
These days most of my time goes to safely migrating Ethereum towards post-quantum cryptography as part of the broader lean Ethereum effort. There's a lot to do. We need to rip out and replace BLS signatures at the consensus layer, KZG commitments at the data layer, and ECDSA signatures at the execution layer.
The plan to get there is compelling, and is based on hash-based cryptography. Within the Ethereum Foundation we've developed a Swiss army knife called leanVM (github[.]com/leanEthereum/leanVM) powered by the magic of hash-based SNARKs. Thanks to truly exceptional work by Emile, Thomas, and others, its performance is derisked. Regarding security, leanVM is a jewel, a minimal zkVM crafted for end-to-end formal verification and maximum security.
Want to help? There are two $1M initiatives. First, the Proximity Prize (proximityprize[.]org). Solve a long-standing mathematical conjecture in coding theory, improve hash-based SNARKs, and go home a millionaire. Second, the Poseidon Initiative (poseidon-initiative[.]info), offers $1M for breaking Poseidon, the SNARK-friendly hash function.
In April, a website that has been sued, blocked, deplatformed, and chased across thirty-seven domains over fifteen years quietly launched its own AI.
Sci-Hub is the largest unauthorized library of scientific papers in human history. Ninety-five million academic papers. Tens of millions of books. Built and maintained by a single Kazakhstani neuroscientist named Alexandra Elbakyan since 2011, funded by donations, hosted on whatever country's registrar will tolerate it that year, mirrored across torrents and IPFS and Telegram bots.
Elsevier sued. Sci-Hub stayed up. The American Chemical Society sued. Sci-Hub stayed up. India sued. Sci-Hub stayed up. Swedish registrar Njalla cut the .se domain in January. Sci-Hub stayed up at .al, .ru, .ee, .box, and a half-dozen .onion addresses the registrars cannot reach.
Now the library has built its own intelligence.
Sci-Bot launched in alpha in April. You ask it a research question. It answers, and it cites real papers from inside the corpus, with links that actually open the actual papers.
The bot does not hallucinate citations. It cannot, because it only draws from papers it actually holds. The same property that the venture-funded labs have spent four years and forty billion dollars trying to engineer back into their products is a free side effect of training the model on a library that contains the books.
Anthropic, OpenAI, Google, and Meta have all been sued in the past eighteen months for training their models on the same shadow libraries that Sci-Hub assembled. Meanwhile the corpus those scripts were pointed at, the corpus those models were trained on, the corpus the entire generative AI industry is built on, sat right there the whole time, free, with a search box on top.
The pirates beat them to it.
Sci-Bot was built on a corpus that was already free, by a team that asked no permission, charging no one, with the explicit position that the right to read scientific research is older than the cartel that decided to charge for it.
The same arithmetic the medieval guilds used to keep the printing trade in approved hands. The same arithmetic Pope Paul IV used in 1559 to publish the Index Librorum Prohibitorum. The same arithmetic the Stationers' Company used in seventeenth-century London.
Knowledge has always had a fence around it. The fence has always been guarded by men who did not write the books.
The library answers. We never asked permission. We never had to.
Bdelloid Rotifers have been having sex for 50 million years.
Except they haven't.
Every single one of these microscopic chainsaw mouth creatures you see under a microscope is a female. They clone themselves. Perfect genetic copies, generation after generation, for longer than mammals have existed on Earth.
Evolution textbooks will tell you this is impossible. Sexual reproduction exists because it shuffles genes and creates diversity. Without it, harmful mutations accumulate. Populations crash. Extinction follows.
Bdelloids missed that memo completely.
They survive radiation doses that would liquify a human. They dry out into dust for decades, then resurrect when water returns. They endure temperatures that freeze solid and heat that boils. They've colonized every continent including Antarctica.
All while breaking the fundamental rule that sex is required for evolutionary success.
The secret lies in their feeding strategy. Those rotating mouth crowns that look like biological chainsaws do more than shred algae. When rotifers eat, they accidentally consume DNA fragments from their prey. Instead of digesting these genetic pieces, they incorporate foreign genes directly into their own genome.
They turned eating into horizontal gene transfer.
While every other complex animal relies on mating to remix DNA, rotifers steal genetic diversity from their lunch. They've been practicing genetic engineering for 50 million years without realizing it.
The implications rewrite what we thought we knew about survival. These creatures prove that life finds ways around rules we assumed were absolute. They've solved the genetic diversity problem without sex, the aging problem without death, and the environmental stress problem without hiding.
They're living proof that evolution has backup plans we never imagined.
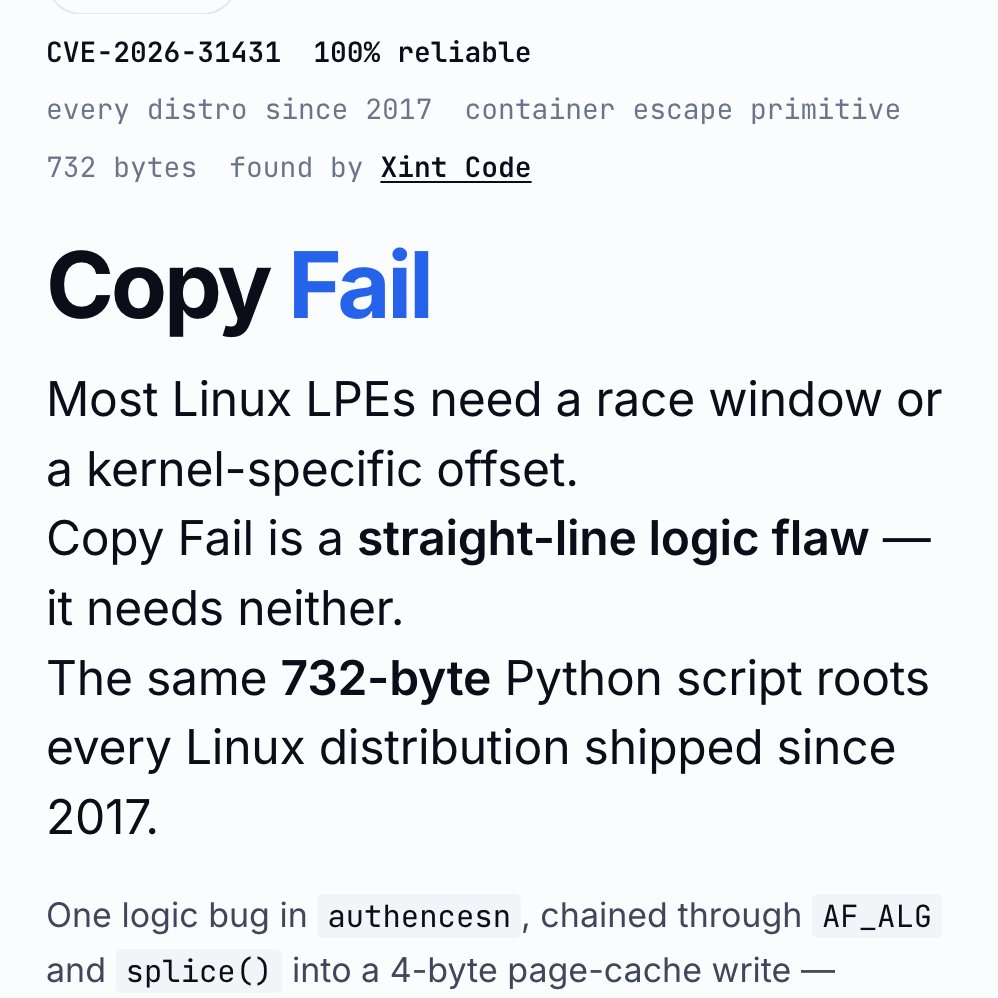
‼️🚨 BREAKING: An AI found a Linux kernel zero-day that roots every distribution since 2017. The exploit fits in 732 bytes of Python. Patch your kernel ASAP.
The vulnerability is CVE-2026-31431, nicknamed "Copy Fail," disclosed today by Theori. It has been sitting quietly in the Linux kernel for nine years.
Most Linux privilege-escalation bugs are picky. They need a precise timing window (a "race"), or specific kernel addresses leaked from somewhere, or careful tuning per distribution. Copy Fail needs none of that. It is a straight-line logic mistake that works on the first try, every time, on every mainstream Linux box.
The attacker just needs a normal user account on the machine. From there, the script asks the kernel to do some encryption work, abuses how that work is wired up, and ends up writing 4 bytes into a memory area called the "page cache" (Linux's high-speed copy of files in RAM). Those 4 bytes can be aimed at any program the system trusts, like /usr/bin/su, the shortcut to becoming root.
Result: the next time anyone runs that program, it lets the attacker in as root.
What should worry most: the corruption never touches the file on disk. It only exists in Linux's in-memory copy of that file. If you imaged the hard drive afterwards, the on-disk file would match the official package hash exactly. Reboot the machine, or just put it under memory pressure (any normal system load that needs the RAM), and the cached copy reloads fresh from disk.
Containers do not help either. The page cache is shared across the whole host, so a process inside a container can use this bug to compromise the underlying server and reach into other tenants.
The original sin was a 2017 "in-place optimization" in a kernel crypto module called algif_aead. It was meant to make encryption slightly faster. The change broke a critical safety assumption, and nobody noticed for nine years. That bug then rode every kernel update from 2017 to today.
This vulnerability affects the following:
🔴 Shared servers (dev boxes, jump hosts, build servers): any user becomes root
🔴 Kubernetes and container clusters: one compromised pod escapes to the host
🔴 CI runners (GitHub Actions, GitLab, Jenkins): a malicious pull request becomes root on the runner
🔴 Cloud platforms running user code (notebooks, agent sandboxes, serverless functions): a tenant becomes host root
Timeline:
🔴 March 23, 2026: reported to the Linux kernel security team
🔴 April 1: patch committed to mainline (commit a664bf3d603d)
🔴 April 22: CVE assigned
🔴 April 29: public disclosure
Mitigation: update your kernel to a build that includes mainline commit a664bf3d603d. If you cannot patch immediately, turn off the vulnerable module:
echo "install algif_aead /bin/false" > /etc/modprobe.d/disable-algif.conf
rmmod algif_aead 2>/dev/null || true
For environments that run untrusted code (containers, sandboxes, CI runners), block access to the kernel's AF_ALG crypto interface entirely, even after patching. Almost nothing legitimate needs it, and blocking it shuts the door on this whole class of bug...
What's especially cool is that the flagellar motor exploits the indivisibility of 5 by 2 to run on a fuel of rising entropy as protons diffuse into cells. For me as a physics and math person, this is biology at its best. https://t.co/TBAP5H3vR3
For decades, biology textbooks have enshrined a simple rule: DNA is made by copying a template. After one enzyme unzips a DNA double helix into separate strands, another called a polymerase builds a complementary sequence, base by base, for each strand. Presto: two copies of the original DNA.
But new research into how bacteria defend themselves from viruses now shows this synthesis rule isn’t absolute.
Now, a team describes a bacterial enzyme that synthesizes DNA without a nucleic acid template, using its own structure as a guide.
Learn more: https://t.co/bpVgr0KMdR
Our greatest concern with this proposition was proof sizes. We were afraid they'd be in the megabytes. Thank god for the community of STARK hackers who effectively proved the practical feasibility of our proposal.
ADAM BACK JUST ABSOLUTELY DESTROYED #BITCOIN QUANTUM FUD LIVE ON BLOOMBERG
QUANTUM COMPUTERS ARE "EXTREMELY BASIC"
WE STILL HAVE "A DECADE" TO PREPARE
DON'T BELIEVE THE FUD. HODL 🚀
Sean Bowe (@ebfull) and Dev (@zkDragon) recently did a whiteboard session to discuss Zcash's post-quantum roadmap: recoverability very soon, using PIR w/ the Tachyon upgrade to achieve full PQ privacy, and setting the stage for PQ soundness alongside major scale improvements.
Tadge Dryja, the co-inventor of the Lightning Network, just dropped an update on Utreexo, one of the most underappreciated scaling projects in bitcoin.
The problem is straightforward. Every bitcoin node that wants to validate transactions has to store the entire UTXO set, every unspent output on the network. Right now that's 11GB and growing. As more transactions hit the chain, as inscriptions and other data-heavy outputs pile up, every node operator has to store all of it. The UTXO set doesn't get pruned like old blocks can. It just grows.
Utreexo eliminates the entire UTXO set from your node. Instead of storing 11GB of data, a Utreexo node stores less than 1KB of hashes and still fully verifies every transaction. It's not a light client. It's not trusting anyone else. It's full validation with radically less storage.
The tradeoff has always been bandwidth. Utreexo nodes need to download extra proof data to verify transactions without storing the full set. Until recently, syncing the blockchain with Utreexo took 2-3x the data download of a normal node, pushing into terabytes. That problem is now being solved, new aggregator techniques from SwiftSync have eliminated the extra download overhead. The implementation is still being finalized, but the hard part appears to be behind them.
Two things worth noting:
First, Utreexo is quantum safe. The accumulator and aggregator are built entirely on hash functions, not elliptic curve cryptography. Whatever quantum computing does to bitcoin's signature scheme, it won't touch Utreexo. At a time when the quantum conversation is heating up, that's a meaningful design advantage.
Second, Utreexo directly addresses the tension around "spam" on bitcoin. Inscriptions, BRC-20 tokens, and other data-heavy outputs bloat the UTXO set that every node has to carry. Pruning helps with old block data but doesn't touch the UTXO set. Utreexo makes the entire debate irrelevant, if your node doesn't store the UTXO set at all, the
size of it doesn't matter.
New releases are out for both utreexod (BTCD-based) and Floresta (rust-based, built with rust-bitcoin). Both are in testing mode, not ready for real funds yet, but ready for developers and node operators to try.
This is the kind of quiet, foundational work that actually scales bitcoin at L1. No token. No VC round. No press tour. Just better engineering.
With the quantum debate heating up again, after the publication of that Google paper, let's not forget the fantastic potential of Taproot to mitigate quantum risk
A brilliant & elegant solution
(We still need a softfork to disable the key path)
https://t.co/eFUbmr0Zxk
Not enough people talk about the risks of rushing Bitcoin’s quantum “fix”:
- PQ signatures are x-times larger than Schnorr
- Either block size war 2.0 or <1 TPS
- PQC algorithms have a fraction of the battle-testing ECDSA has
The cure, rushed, could be worse than the disease.
BIG BREAKTHROUGH:
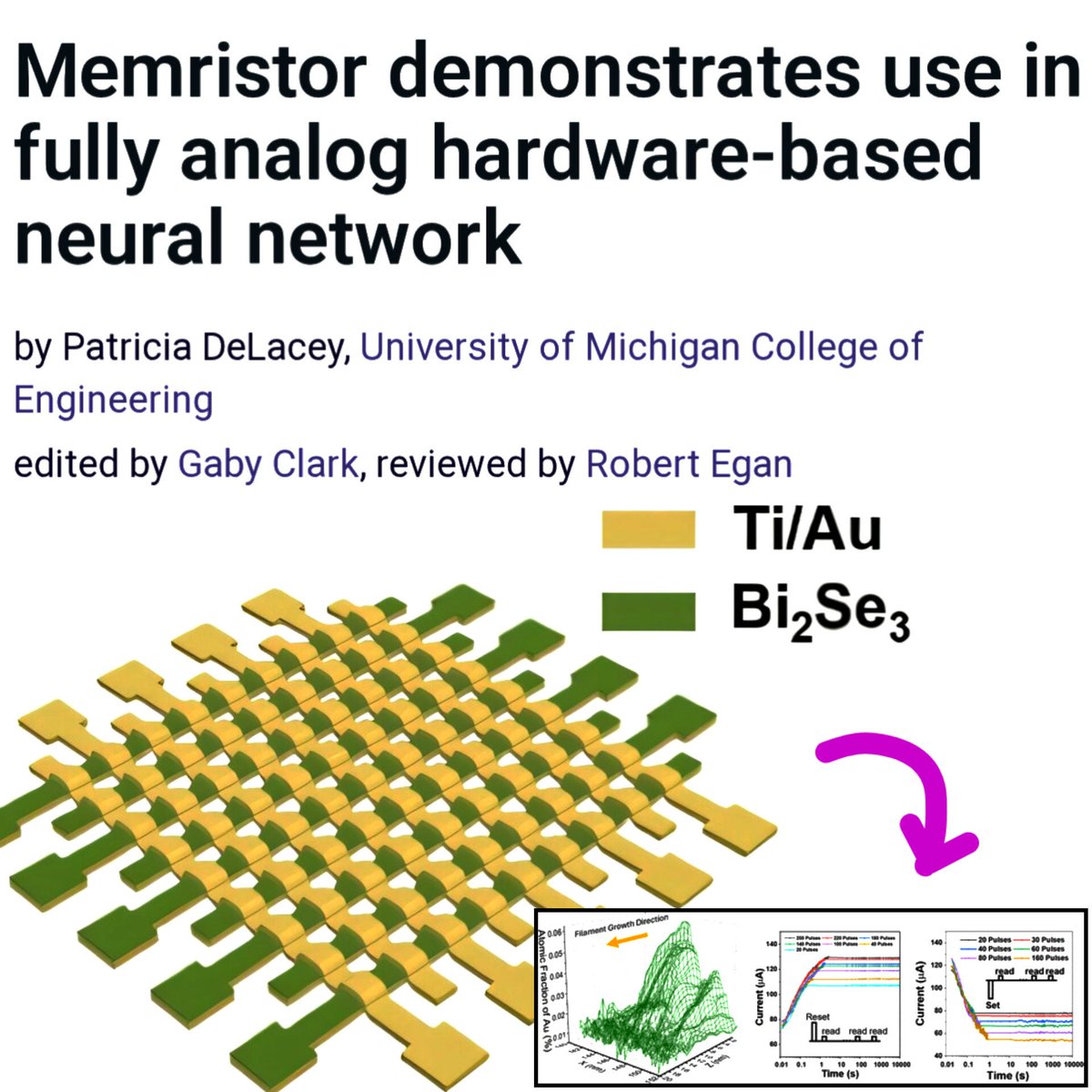
Scientists develop a fully analog memristor that computes and stores data like a real brain synapse.
Researchers just built a memristor using Bismuth selenide (Bi₂Se₃) with a Gold/Bi₂Se₃/Titanium structure, where nanoscale gold filaments dynamically form and dissolve to enable continuous analog resistance tuning.
The device simultaneously achieves nonvolatile memory, fully analog switching and self regulated operation without external control circuits, a combination previous memristors failed to deliver 👀
In experiments, the system powered a real-time balance control task using only ~7 µW, performing computation and memory in the same physical location with no digital processor involved.
This breakthrough could enable ultra efficient in-memory computing, reduce energy consumption by orders of magnitude and accelerate the development of scalable neuromorphic hardware for edge AI and robotics.
🚨 BREAKING: Tencent has killed the “next-token” paradigm.
Tencent and Tsinghua has released CALM (Continuous Autoregressive Language Models), and it completely disrupts the next-token paradigm.
LLMs currently waste massive amounts of compute predicting discrete, single tokens through a huge vocabulary softmax layer. It’s slow and scales poorly.
CALM bypasses the vocabulary entirely. It uses a high-fidelity autoencoder to compress chunks of text into a single continuous vector with 99.9% reconstruction accuracy.
The model now predicts the “next vector” in a continuous space.
The numbers are actually insane:
- Each generative step now carries 4× the semantic bandwidth.
- Training compute is reduced by 44%.
- The softmax bottleneck is completely removed.
We’re literally watching language models evolve from typing discrete symbols to streaming continuous thoughts.
This changes the entire trajectory of AI.
We've uploaded a fruit fly. We took the @FlyWireNews connectome of the fruit fly brain, applied a simple neuron model (@Philip_Shiu Nature 2024) and used it to control a MuJoCo physics-simulated body, closing the loop from neural activation to action.
A few things I want to say about what this means and where we're going at @eonsys. 🧵