Silly Business Theory is right: in the future the best work, greatest progress, most valuable innovations won't come from laboring under the false consciousness that work must be hard and serious to produce value. The best work is going to come from people playing and having fun.
Things working well for young people in the age of AI
- building cool side projects they are interested in
- publishing papers without paying the university system
- selling and pitching
- networking
- retardmaxing
- posting demos, opinions, ideas and news on x and insta
- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
Just built my first SO-ARM101 robot arm! LeRobot + HuggingFace made it really straightforward, reminded me of how much I loved my Lego days. Leader arm next, then training imitation learning policies 🤖
robotics data for physical AI is front and center this year. from gtc's heavy focus on data infrastructure to human data ecosystems like egoverse, the field is waking up to the bottleneck of scaling robotics data. and there's real divergence in how people think about quantity, quality, modality, and diversity.
@aurorafeng_01, @deeptt and i have been looking at the data infra landscape and put together a market map + open data vendor/collector list 👇
NVIDIA says: no more "brute force every pixel" of video understanding.
AutoGaze- identifies and removes redundant video patches before they enter a Vision Transformer.
Now we can processes 4K long-video in real-time.
Works with SigLIP2 and NVILA.
https://t.co/TWRVFC1vmX
One common issue with personalization in all LLMs is how distracting memory seems to be for the models. A single question from 2 months ago about some topic can keep coming up as some kind of a deep interest of mine with undue mentions in perpetuity. Some kind of trying too hard.
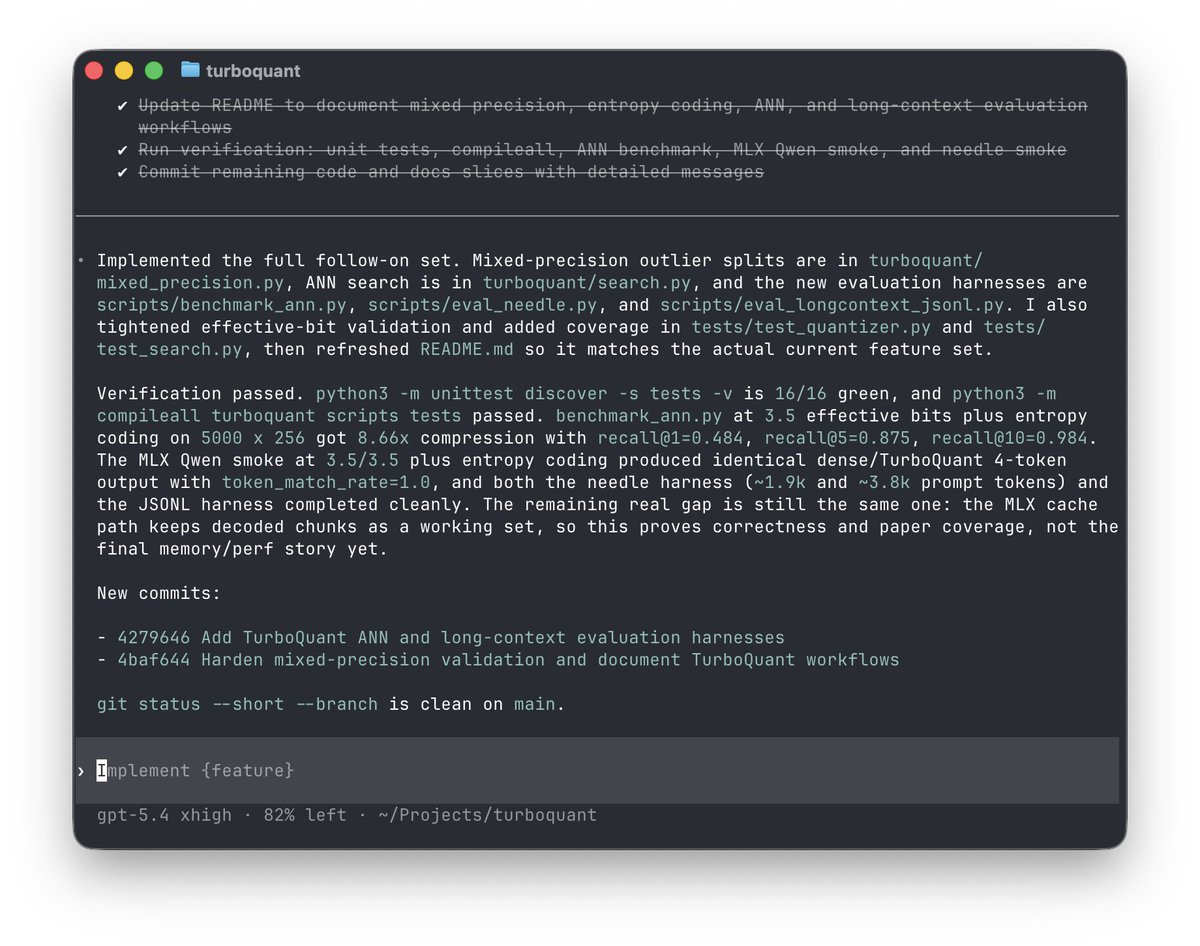
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Robots building robots.
RL token is a simple but powerful idea:
Fine-tuning robot policies usually takes days.
This takes minutes.
Instead of retraining the full model, compress its internal state into a small feature vector and train a tiny RL layer on top.
• small actor + critic
• trains in real time while the robot practices
• adapts specific task stages, not the whole model
Result:
→ precise skills learned in ~15 minutes of robot data
This is especially useful for high-precision steps like fastening, screwing, or zip ties.
In some cases, it even outperforms human teleoperation in consistency.
Big picture:
We’re moving from training entire models
to patching capabilities in real time.
Credit: Physical Intelligence
More: https://t.co/gwmTzMeO9k
——
if it matters in AI or Robotics you'll read it here first: https://t.co/9Nm01QUcw3