Harmony in the hive? Think again! 🐝⚔️
Insect societies are famous for cooperation, but beneath the surface lies a brutal conflict over who gets to wear the crown.
Our new review in Biological Reviews explores the evolutionary battleground caused by such caste fate conflict. 🧵
We can finally say AI isn't killing jobs.
A new paper from me, @tryramp, and @RevelioLabs uses firm-level spend and workforce data across 21K U.S. businesses to measure AI's impact on jobs.
Firms that adopt AI heavily grow headcount 10% over two years following adoption. Low adopters see no statistically significant change.
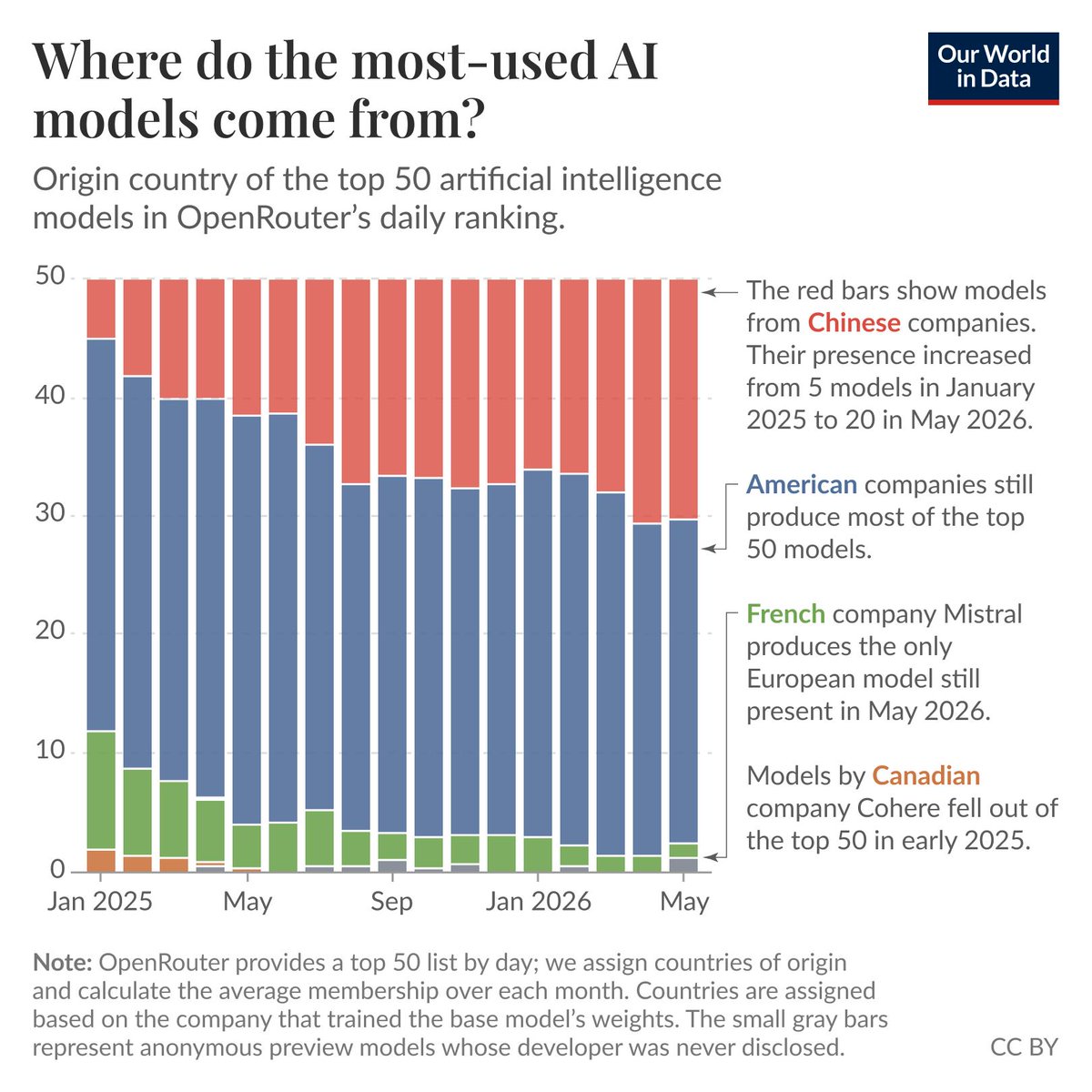
US and Chinese companies train almost all of the world’s most-used AI models.
(This Data Insight was written by @redouad.)
Dozens of companies worldwide develop large AI models, but it can be difficult to get a sense of where the most-used ones tend to come from.
OpenRouter is a large platform that allows users to interact with and write software on top of AI models through a single interface. It includes all the models from large companies like Google, OpenAI, Anthropic, Meta, DeepSeek, and Alibaba, as well as many, many others.
I analyzed the data published by OpenRouter on the 50 most used models each day since January 2025 and calculated the average monthly presence by origin country of the models.
As you can see on the chart, US-based companies still account for most models in OpenRouter’s top 50. But their presence has declined, and China-based companies have grown rapidly, from 5 models in the daily top 50 at the beginning of 2025 to 20 in May 2026.
Very few top-50 models come from companies outside the United States and China. Canada was represented early in 2025 by Cohere’s Command R models, while France remains represented by Mistral AI’s NeMo model.
A technology that more people use every year is, so far, almost entirely the product of two countries.
99% of all OpenAI token use in firms in the field of engineering is now agentic AI Codex use! Given that reality it is pure madness that KULeuven banned such systems on university managed computers...
This is a fascinating and important set of data which shows us where things are going, using OpenAI as a canary in the coal mine.
The chatbot era is over, and agentic systems are coming to tasks beyond engineering. And skills show promise as a way to standardize AI use in firms.
Very recognizable account of what it feels like to work with agentic LLMs like Codex or Claude for coding! I just had Codex port my best subset selection R package to Rcpp/OpenMp and it managed to get it to run 100x faster than a glmnet group Lasso model! 6s instead of 10 mins!
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
@m13v_ Don't know - didn't have any problems on that front - it went to work for 2 hours, I checked back and all bugs were fixed & all CRAN package checks passed...
Nice - a bit late to the show but now we have Computer use in Codex also in Europe! This will be a huge time saver... Yesterday I put Codex to work on my upcoming R package and in just 2 hours it successfully fixed a zillion hard to debug CRAN package check warnings...
More of Codex is rolling out across Europe this week.
We’re bringing Computer use, the Codex Chrome extension, personalized memory, and Chronicle to Codex users in the EEA, UK, and Switzerland.
https://t.co/tsriEswcyY
Even more elegantly, Codex could also readily write OpenSCAD code to produce this honeycomb design, including debossed letters for the different rows, in just 230 lines of code. STLs and code here: https://t.co/caIyQzpCJh
With minimal instruction & in just 13 mins, Codex wrote me a Python script to procedurally generate the STL of a piece of honeybee worker comb & I then had it 3D printed for just 8 euros by the great people at Fablab! Not allowed at KU Leuven, as it's agentic AI. But works great!
@jdceulaer Knap staaltje van hoe vooral copilot blundert werd recent nog op de AI bootcamp kickoff lecture aangehaald... En toch pusht men bij bedrijven en instellingen allerhande copilot - echt onbegrijpelijk... https://t.co/p0jEK4kide
The speakers the other day at the AI bootcamp kick-off lectures here gave two simple examples of "AI can make mistakes" - "1.9 or 1.11, which is bigger?" and "solve 5.9 = x + 5.11". Turned out that only https://t.co/LoLo1YUFBs's "Smart" model in fact returns the wrong answers.
@jdceulaer Dat ze AI agents gebruiken "binnen een configureerbaar platform dat samen met Microsoft is ontwikkeld" is waarschijnlijk het grootste probleem... Copilot e.d. deugt voor geen meter... Met de betere GPT/Claude Thinking modellen krijg ik persoonlijk nooit nog verzonnen referenties.
"Voor Europa is dit een wake-upcall. Als Europese spelers geen toegang meer krijgen tot de beste systemen, dreigen ze afhankelijk te blijven van verouderde technologie". PS: meestal zijn het EU of ICT bedrijfsregels die hiervoor zorgen... https://t.co/py4m4M3bfr
Claude Fable 5 scores very well on FrontierMath: Tiers 1–4 (v2), reaching 87% on Tiers 1–3 and 88% on Tier 4. This continues a streak of Anthropic models improving rapidly at math.
@gerardgovers De jonge werkende bevolking op termijn vervangen door humanoide robots? Dat is althans het plan in China - daar hoopt men tegen 2035 4% van hun werkende bevolking te kunnen vervangen door robots...
Link to a presentation I gave earlier this year at the Biology Research Day about "Working Smarter with AI:
Coding, Analysis and Scientific Writing" : https://t.co/hiE2ssmzpH
Or the models built into copilot for Word, Powerpoint, Excel or Outlook, where users also have no control over which model is actually used or thinking effort, and requests are often sent to a very poorly performing model?
The speakers the other day at the AI bootcamp kick-off lectures here gave two simple examples of "AI can make mistakes" - "1.9 or 1.11, which is bigger?" and "solve 5.9 = x + 5.11". Turned out that only https://t.co/LoLo1YUFBs's "Smart" model in fact returns the wrong answers.
Time to start prioritising model quality over data privacy... And sure, if you go to https://t.co/YptHo19XK2 & select the latest GPT 5.5 Think Deeper model you can also get the correct answer. But how many unsuspecting users will just use their (not so) "Smart" model?
@gerardgovers@JorenVermeersc1 Dit is toch maar een eenvoudige enquete, geen wetenschappelijke studie? En stel dat ze een echte studie besteld hadden bij de KULeuven. Met als doel pakweg verband nagaan tussen homohaat en religie. Dat zie ik er bij de SMEC nooit doorkomen...