Associate Professor at University of Valladolid. Research in Artificial Intelligence, Virtual Reality and GPU Computing for biomedical and industry applications
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
In 2025, DeepMind CEO Demis Hassabis gave a 60-minute Cambridge lecture on AI as a discovery engine.
This is bigger than chatbots.
He explained:
- The "Move 37" method
- A billion years of PhD time
- Biology as an information system
12 lessons that will blow your mind: 🧵
El profesor Mario Martínez Zarzuela @Twynway de @etsit_uva imparte una charla divulgativa sobre IA en el @IESGalileo para reflexionar sobre lo rápido de su evolución y su papel en el mundo actual.
Gran iniciativa para fomentar pensamiento crítico y responsable del uso de la IA
LeWorldModel: Yann LeCuns Radical Simplification of World Models Just Made Physics-Aware AI Practical
In the race for artificial general intelligence, two paths have emerged. One is the familiar scale everything route: bigger LLMs trained on ever-larger text corpora. The other, championed for years by Yann LeCun, is building world models: compact systems that learn the underlying physics of reality directly from raw sensory data (pixels) so AI can plan, predict, and act in the physical world like a robot or self-driving car actually would.
Until now, the second path has been frustratingly difficult. Joint-Embedding Predictive Architectures (JEPAs) - LeCuns elegant framework for learning predictive representations without reconstructing every pixel - kept collapsing during training. Researchers had to resort to a laundry list of hacks: multi-term loss functions (up to six hyperparameters), frozen pre-trained encoders, stop-gradients, exponential moving averages, and other duct-tape tricks just to keep the model from mapping every input to the same useless output.
LeCuns team (Mila, NYU, Samsung SAIL, and Brown University) dropped a bombshell:
LeWorldModel (LeWM) - the first JEPA that trains stably end-to-end from raw pixels using only two loss terms. No more house-of-cards engineering. Just a clean, simple recipe that works on a single GPU in a few hours with only 15 million parameters.
The Core Breakthrough: SIGReg Saves the Day
LeWorldModels secret weapon is a new regularizer called SIGReg (for spherical isotropic Gaussian regularizer). It enforces a simple Gaussian distribution on the latent embeddings.
This single term prevents representation collapse without any of the previous heuristics.
The training objective now has just two parts:
1. Next-embedding prediction loss - the model predicts what the next latent state should be.
2. SIGReg - keeps the latent space well-behaved and diverse.
Thats it. Hyperparameters drop from six to one. Training becomes stable, reproducible, and dramatically cheaper.
The model learns directly from raw video frames (no pre-trained vision encoders needed) and produces a compact latent world model that can be used for fast planning.
Impressive Results on Real Benchmarks
Despite its tiny size, LeWorldModel punches way above its weight:
- Trains on a single GPU in a few hours.
- Plans actions up to 48 times faster than foundation-model-based world models.
- Uses roughly 200 times fewer tokens than alternatives.
- Matches or beats far larger models on diverse 2D and 3D control tasks (e.g., manipulation, navigation).
- Its latent space encodes meaningful physical quantities (position, velocity, etc.) - proven by direct probing.
- It reliably detects physically implausible surprise events, showing genuine causal understanding.
Crucially, adding a decoder and reconstruction loss hurts performance on downstream control tasks. The pure JEPA objective already captures everything needed for planning - extra visual details just get in the way.
Project website: https://t.co/KhGR9LiIQZ
Official code: https://t.co/s1lI9kevJS
Why This Matters for the Future of AI
LeCun has been saying since 2022 that world models (not next-token predictors) are the key to real intelligence. Critics always pointed to the training instability. LeWorldModel removes that objection with elegant simplicity.
This is a philosophical reset: AI can learn physics the way babies do - by watching the world unfold - without needing supercomputers or endless text.
The implications for robotics, autonomous vehicles, and embodied agents are enormous. Suddenly, building a physically grounded planner is something a researcher (or even a hobbyist) can do on consumer hardware.
1 of 2
💉El equipo OneHealthEU, del grado de Ingeniería Biomédica de la UVa, gana la primera edición del concurso 3×3 TecnoVitae
🌱Otro grupo de la UVa, del Grado en Ingenierías de Tecnologías de Telecomunicación, quedó entre los finalistas
https://t.co/3BOHKGfvz6
It's basically impossible to predict what emergent properties you might get from scaling up a given algorithm. That's why AGI is much more an engineering endeavor than a theoretical one. It's a process of discovery through building.
Desde @ETSIT_UVa queremos dar las gracias a nuestros alumnos del semestre internacional por el increíble video que realizaron sobre el semestre 🌍✨
International Semester ETSIT UVa https://t.co/8WMgwVqm2F a través de @YouTube
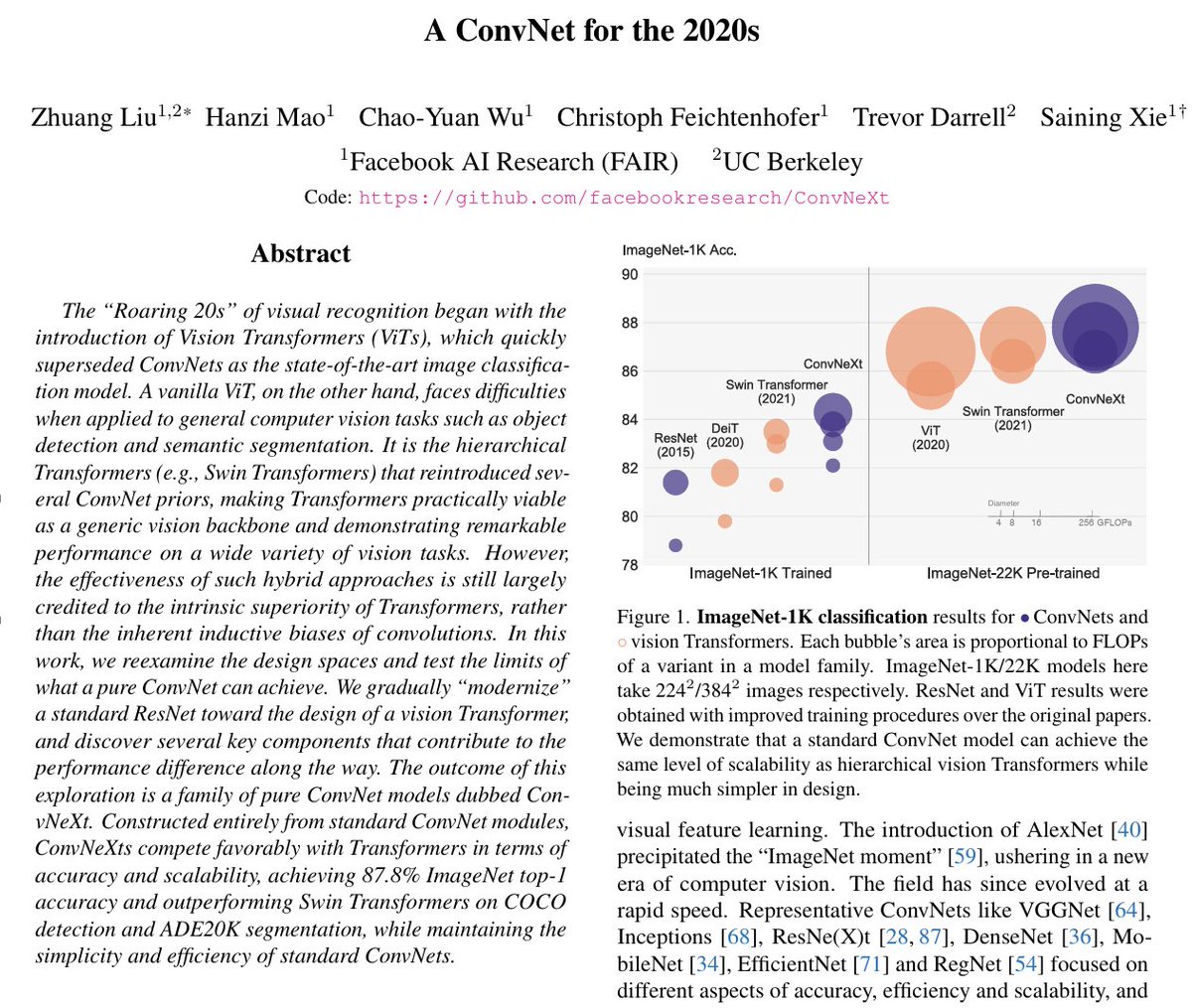
For most of the 2010s, convolutional neural networks (ConvNets) — networks that process images by sliding small filters across them to detect patterns — were the dominant architecture for computer vision. Then transformers arrived.
Transformers, originally designed for text, process input by letting every element attend to every other element simultaneously, and when adapted for images they started outperforming ConvNets on benchmark after benchmark. The general consensus became that transformers were just better, and ConvNets were the old way.
This paper's authors decided to test whether that conclusion was actually justified, or whether ConvNets had simply fallen behind in terms of training recipes and design choices rather than fundamental capability.
They took a standard ResNet and systematically updated it — one change at a time — borrowing design decisions from transformers: things like which activation function to use, which type of normalization to apply, and how to reshape the internal dimensions of each processing block.
Each change was small and interpretable, and the paper tracks the accuracy at every step so you can see exactly what each decision contributes.
The final result is a pure ConvNet that matches or beats transformer-based models of equivalent size on image classification, object detection, and segmentation, by being up to 49% faster.
Read with AI tutor: https://t.co/abh8jEt8A2
Read alone: https://t.co/PH5kBIpl70
Desde #UVaIA queremos que conozcáis mejor cómo funciona este centro interdisciplinar de #IA. En este vídeo os contamos cómo se ha creado, quién nos apoya y las actividades que hemos impulsado desde #UVA a la sociedad y empresas.
Descubre lo que ofrecemos👉https://t.co/E4M1xAXH49
🏃♂️🎉 Valladolid despide el año haciendo historia con la @pucelasansil.
➕ de 5.500 corredores han tomado las calles de la ciudad en la carrera popular de fin de año del @AyuntamientoVLL y @DeportesVLL, marcando un récord histórico de participación.
Fei-Fei Li says the ability to learn and adapt now matters more than degrees
Structured credentials matter less than how quickly an engineer adopts new tools to boost output
"at this point in 2025, i wouldn't hire a software engineer who doesn't embrace AI-collaborative tools"
Ilya is puzzled why LLMs are crushing benchmarks, but the business outcome is next to nothing 😁
I mean, why would anyone need a Safe Superintelligence if an unsafe one doesn't make money?
Big news! NVIDIA’s CEO Jensen Huang just snagged a Luminary award at the Precision Medicine World Conference for his groundbreaking work in advancing precision medicine with AI and accelerated computing. Check out how NVIDIA is revolutionizing healthcare: https://t.co/xCbZU7gby6
Jornadas informativas sobre los Grados de Telecomunicación
-El día 12 de Febrero presencial y online a través de youtube en el Palacio de Congresos de 17 a 19 horas
-El día 21 de Febrero Jornada de Puertas Abiertas en el edificio de @ETSIT_UVa en dos sesiones 10:00 y 16:00
If you're not already paying attention to this shift, you should be: the balance of compute is moving from pre-training to inferencing. We're seeing massive gains here from scaling up test-time compute, with no ceiling in sight