Life changing technology, without changing how we live. That makes me tick. And so do my family, the countryside, photography and drone action. Super-geek.
On-device just stopped being a compromise. 🚨
Today, @Adobe and @Speechmatics are bringing a new on-device speech-to-text model to Premiere, giving creators fast, accurate transcription that stays local to the device. 👏
What a night.
Last night we brought together engineers, founders and researchers in SF to talk honestly about the state of voice AI.
Highlights:
→ @RiquiHerreros and @uberboffin on benchmark design: what to test, and where benchmarks fall short in the real world
→ Hassaan Raza (@Tavus) on multimodal video agents
→ Bo Xie (@OpenAI) on training GPT Realtime speech-to-speech models
Thanks to @kwindla for moderating and @Tavus for hosting.
The future of voice is being built right now.
Detailed technical post about this voice agents STT benchmark: https://t.co/9OWZuorx4f
Benchmark source code: https://t.co/KruEBoxRD6
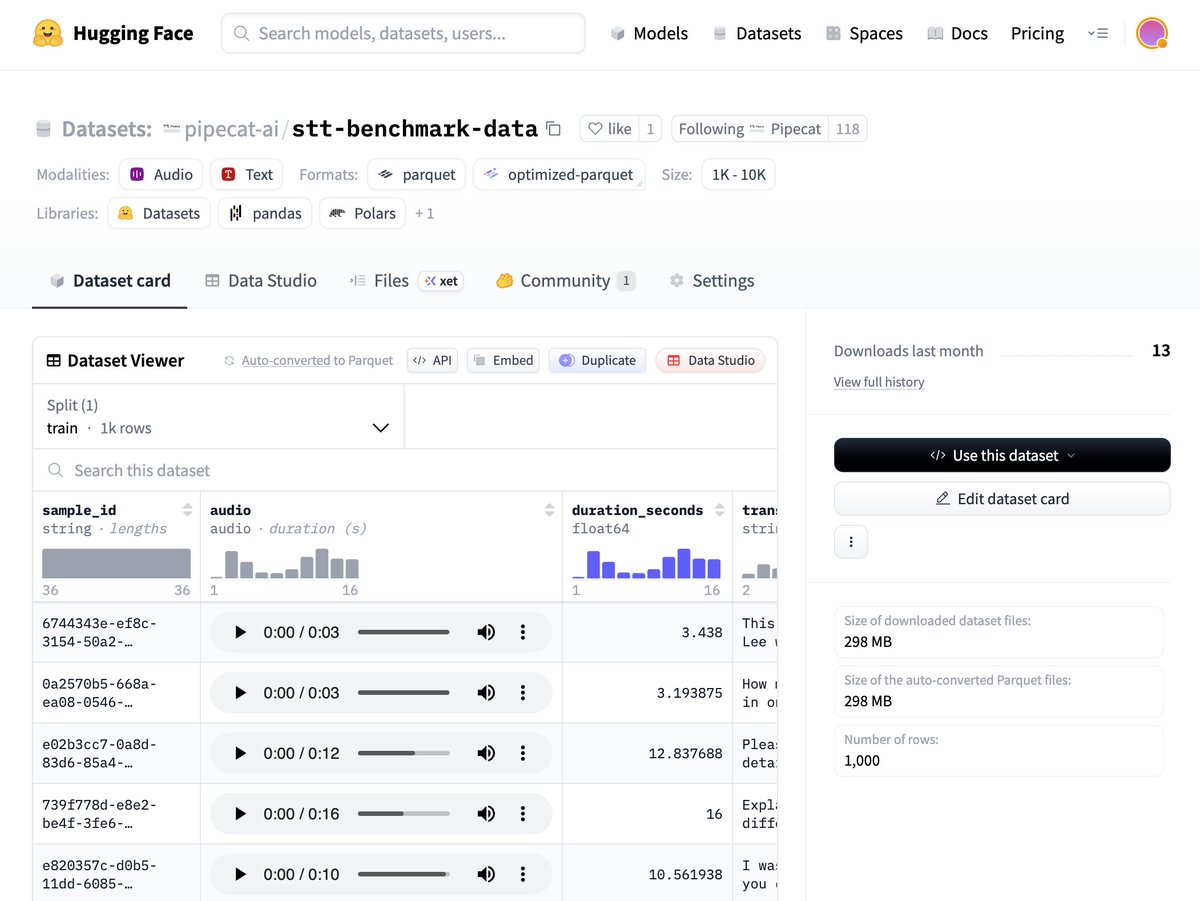
Benchmark data set on @huggingface . 1,000 human speech samples, captured from real voice agent interactions, with verified ground truth transcriptions: https://t.co/qbsny8xquj
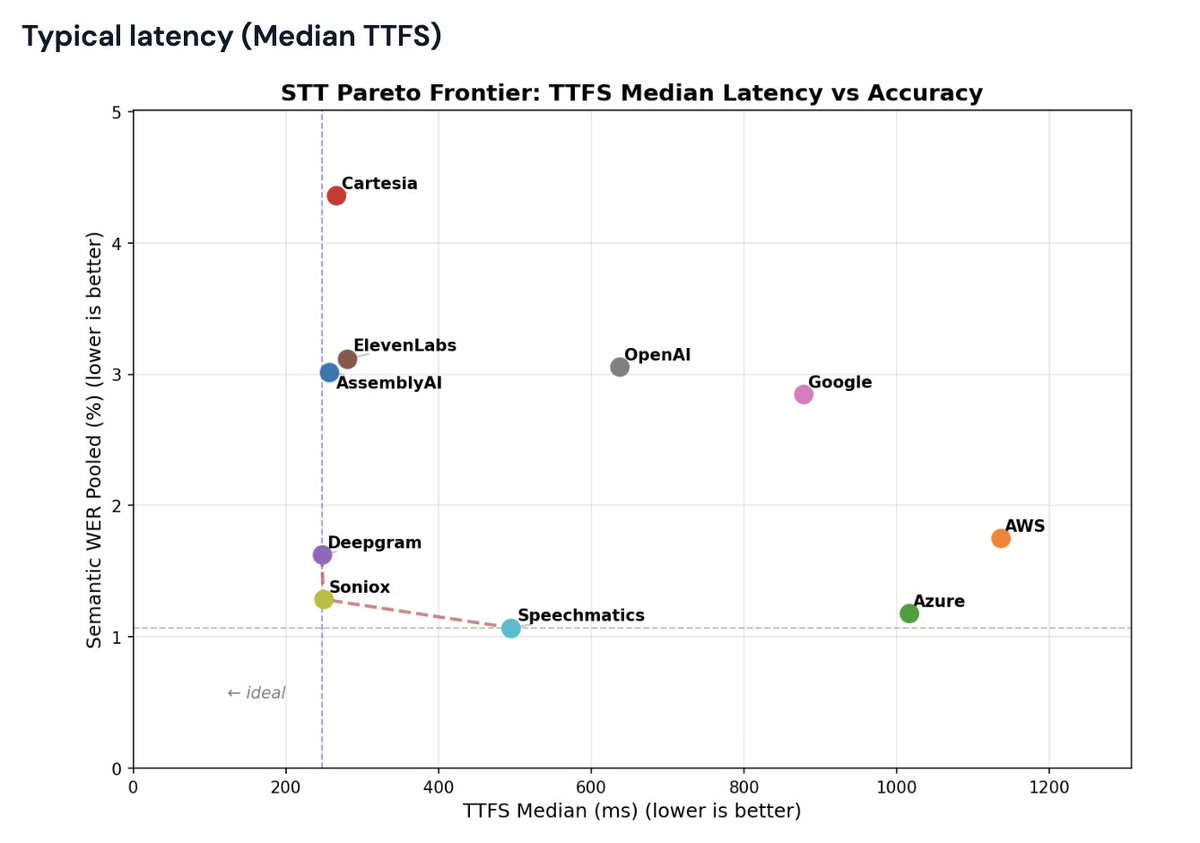
Wake up, babe. New Pareto frontier chart just dropped.
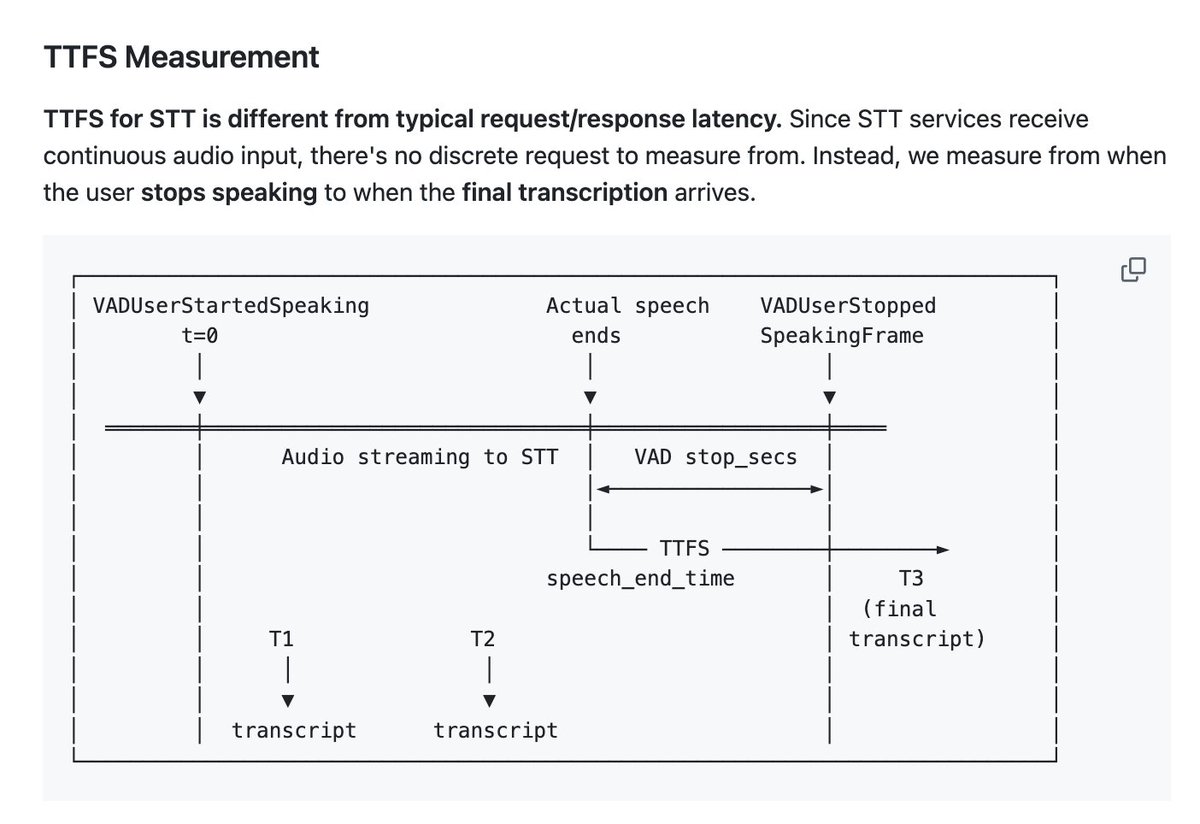
Benchmarking STT for voice agents: we just published one of the internal benchmarks we use to measure latency and real-world performance of transcription models.
- Median, P95, and P99 "time to final transcript" numbers for hosted STT APIs.
- A standardized "Semantic Word Error Rate" metric that measures transcription accuracy in the context of a voice agent pipeline.
- We worked with all the model providers to optimize the configurations and @pipecat_ai implementations so that the benchmark is as fair and representative as we can possibly make it.
Entirely open source. You can run the benchmark yourself and reproduce the results.
Tired of reading docs for 3 hours and still not knowing how to implement Voice AI? 🫠
Speechmatics Academy = working code you can actually use.
No theory dumps. No broken tutorials. Just plug-and-play recipes for:
▶️Real-time transcription
▶️Voice agents
▶️@LiveKit and @pipecat_ai integrations
▶️@twilio apps
▶️Podcast processing
GitHub link in comments.
NEW LAUNCH 🚨 We are partnering with @sullyai to scale healthcare AI infrastructure globally.
Built on @NVIDIAAI infrastructure, combining medical-grade speech models with autonomous agents delivering serious results:
📊 21x ROI
⏱️ 30M minutes returned to healthcare workforce
👨⚕️ 2.4+ hours saved per physician/day
🚨 Multi-speaker Voice AI has landed 🚨
Thanks to our new integration with @Pipecat_ai, you can now build voice agents that know exactly 'who' said 'what' – even in the chaos of busy households, meetings, or shared workspaces.
This pushes Voice AI forward by:
🗣️ Identifying each speaker for smarter, context-aware responses
🔄 Handling turn-taking + interruptions in multi-speaker chats
💻 Working anywhere: cloud, on-premises, or on-device
Get started here 👉 https://t.co/3LeEZaZtNR
#VoiceAI #AIagents #AI
🎲 Guess Who? — but make it real life 🤖🧍♂️🧍♀️
In our latest hack, I took the classic board game Guess Who? and threw it into the real world — powered by:
🎙️ Speechmatics ASR + diarization
🔗 Pipecat for WebRTC + function calls
🧠 ChatGPT for smarts
🗣️ Humphrey, our eloquent ElevenLabs-voiced opponent
I used function calls to keep Humphrey in check (because yes, he does get a bit cheeky 😅), and embedded logic to manage turn-taking, player switching, and character reveals.
With diarization, the system always knows who’s speaking, making multi-player voice interaction smooth and natural — even when you’re flipping cards in the heat of battle.
It’s part fun, part madness, and 100% real-time conversational AI in action.
Check out the repo: 🔗 https://t.co/78meQYNnEH
Video below 🎥 + LOLs in comments please! 👇
Props to the awesome teams:
@kwindla + @pipecat_ai / @trydaily@Speechmatics@elevenlabs
And "hello" to @Hasbro - hope you like it! ❤️
#ConversationalAI #VoiceAI #EmbeddedAI #Speechmatics #Pipecat #GuessWho #ElevenLabs #OpenAI #RealTimeAI #Diarization
Thanks @kwindla!
I did also try creating a specific FrameProcessor that would check for `<NO_RESPONSE/>` being sent from the LLM. If present, then this would be captured and removed so it was not verbalised but would remain in the conversation context.
Turns out that this was also unreliable in Guess Who?, so I then looked at the function call approach. I am sure it can help solve over-eager LLMs in many other situations.
We played a game of Guess Who? using @Speechmatics diarization that knows who’s talking, running on a tiny ESP32 using WebRTC via @pipecat_ai from @trydaily
Yes. Really. 😎
Matt Barty and I went up against “Humphrey”, trying to guess a mystery Brit ... 🎩
With diarization, even over a noisy embedded setup, Humphrey knows who’s speaking — incredible for robotics, drive-thru, lifts ... 🔥
Thank you @kwindla, @ninacali4 and the @trydaily team for making real-time voice AI on embedded hardware a reality.
🧑🏻💻 Code - https://t.co/HdpzeXXhFL
#Speechmatics #Pipecat #ESP32 #VoiceAI #SpeechRecognition #ConversationalAI #WebRTC #EmbeddedAI #GuessWho #ElevenLab
For others in the same position and receiving no feedback from @CBLsupport , see this automated reply - the issue is still ongoing.
Dear Customer,
We would like to apologise for the interruption in service, we experienced a technical fault that has affected your service and impacted the County Broadband support desk telephone line and systems.
This included our standard network notification system that prevented us issuing a notification to you.
The County Broadband Network Support team continue to investigate the root cause of the failure to mitigate any re-occurrence.
We would like to sincerely apologise for any inconvenience caused during this disruption.
Kind regards
Customer Support
[email protected]
@CertasBusiness your telephone lines seem to be down. Need to discuss being #overcharged yesterday for heating oil - 15p/l more on the driver's ticket to getting a quote online! Something's not right ...