Not your weights, not your algo, not open ai.
We know that nondeterminism is a feature, but llms randomly leaking training data will be an important vector of attack
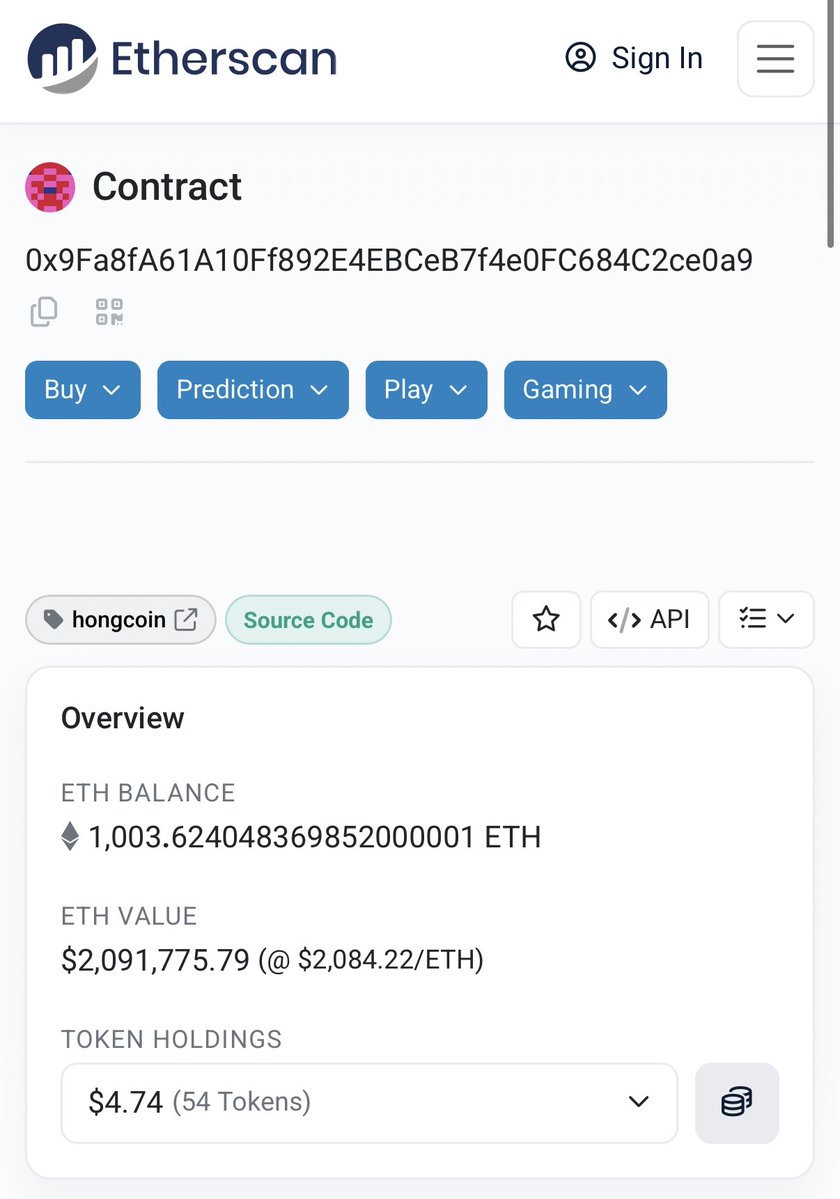
First white-hat exploit on Ethereum: I unlocked 1,003.62
Ξ ($2,000,000) trapped in a 2016 ICO smart contract
for 9 years.
The 48 original investors can now claim their funds.
This is the initial prompt:
"Write a classical haiku given the provided inputs."
The screenshot shows the new version.
This is how @DSPyOSS adds clarity:
- express intent in logical building blocks
- add your eval criteria + dataset
- GEPA optimization algo
@visakanv having the ideas expressed at the right level of compression is already half of the battle won.
The issue with x is poor discoverability so the value doesn't have too much room to spread outside the narrow recency window.
Substack is also not perfect but SEO juice flows better
Misreading the Bitter Lesson is how agents end up burning fortunes rebuilding context.
Expensive amnesia, paid to anthropic in tokens.
The fix: semantic state at ingestion, ontology at retrieval, tiny models for traversal, frontier models for judgment.
It's never made sense to me that RL collapses all reward signals to a single scalar. Today, we fix that!
Introducing Vector Policy Optimization: we train models to inherently optimize for the varied nature of a reward vector, creating diverse sets of answers ideal for test time search. Website and code coming soon!
i'm excited to open source Active Graph: an event-sourced reactive graph runtime for long-running, agents 🔄🧠
events/logs projects a graph. reactive behaviors react and affect the graph. fork-and-diff agent runs. no A2A, no workflows, no DAG
site: https://t.co/Bbknu3ieUi
docs: https://t.co/HAnKYjrZxZ
github: https://t.co/jXQpMcyP1n
quick start: pip install activegraph
this is an early experiment in a new paradigm for agent architecture 🧪
Zuck quoted in Ben Evans presentation + 8k ppl fired = system collapses under higher velocity and oversupply
It's either: "we really can't handle and integrate all the new opportunities without sacrificing the revenue"
or
"we need to do less better"
https://t.co/DyIBp7tHaJ
Recent agentic systems (Claude Code, Codex, RLM, etc.) push context out of the prompt and into the environment (e.g., as files). This helps them maintain long-term knowledge about their goals and functionality.
🚨 While this is a good idea, we show a surprising result: systems that use external environments like this perform much better when given a small, fixed-size, in-context, agent-managed cache that "𝘱𝘦𝘦𝘬𝘴 𝘪𝘯𝘵𝘰" these environments.
🚀 Our paper, 𝗣𝗘𝗘𝗞: 𝙖 𝙨𝙮𝙨𝙩𝙚𝙢 𝙛𝙤𝙧 𝙗𝙪𝙞𝙡𝙙𝙞𝙣𝙜 𝙖𝙣𝙙 𝙢𝙖𝙞𝙣𝙩𝙖𝙞𝙣𝙞𝙣𝙜 𝗮𝗻 𝗼𝗿𝗶𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 𝗰𝗮𝗰𝗵𝗲 𝙛𝙤𝙧 𝙇𝙇𝙈 𝙖𝙜𝙚𝙣𝙩𝙨, introduces this idea.
Compared with strong baselines, including RAG, Compaction Agents, and SOTA prompt-learning frameworks, PEEK dominates the cost–quality Pareto frontier: achieving +6.3–34.0% in quality, with fewer iterations and lower cost.
Paper: https://t.co/67pm4Dqbw5
GitHub: https://t.co/JNMehuzN9M
More in the thread below! (1/N)
Depth-first network is the life hack for the distraction era: a bunch of folks that get it and have aligned incentives beat wide and shallow networks all the time.
It’s a meta heuristic that works everywhere:
- friends
- feedback from the right icp
- less tools+smart defaults
Game theory proves that the size of your network is not the most important factor at all. If you have a network of a thousand weak ties with no mutual dependency, it will produce near-zero results most of the time. And when put under pressure, it collapses immediately. You should focus on a network of twelve people with highly overlapping incentives and clear reciprocity structures. It will outperform a grand network every time. That's because the brain's social cognition system can only maintain a high sense of trust with a limited number of people. Beyond that, everything feels transactional. Depth beats width every time. Aligned people outwork the crowd every time.
I’ve never been this excited about search.
6-7 years ago, IR got an influx of the paradigms we still use, all enabled by the big headroom MS MARCO and then BEIR created. Then progress slowed.
Today, Diane releases perhaps the most ambitious IR benchmark to date: OBLIQ-Bench.
Queries in it are meant to be increasingly opaque to current first-stage retrieval paradigms. Oblique queries put the bottleneck very early in the search process, as the relevance of a document to the query is quite latent.
I can't wait for core IR research on fundamentally more powerful paradigms for first-stage search to be reignited again. Stay tuned for more stories about this, and read Diane's thread and her paper below!!