GITHUB JUST CREATED AN OFFICIAL CERTIFICATION FOR THE MOST IN-DEMAND DEVELOPER ROLE OF 2026.
It is called Agentic AI Developer.
GH-600.
And it is the first formal signal that running AI agent teams is now a recognized engineering discipline with a credential behind it.
Not a prompt engineer.
Not a vibe coder.
An Agentic AI Developer.
The person who operates, supervises, and integrates AI agents across the entire software development lifecycle.
The person who knows where agents fail in production.
The person who understands how to build autonomous workflows that do not introduce catastrophic failure modes into CI/CD pipelines.
The person every engineering team is going to need and almost none of them have right now.
GitHub certifying this role changes the hiring conversation permanently.
Before GH-600: "Do you work with AI agents?" is an interview question with no standard answer.
After GH-600: the credential tells the hiring manager exactly what you know and what you can do before the interview starts.
The engineers who get certified in the first wave of GH-600 will have a credential for a role that has more demand than supply for the next 3 to 5 years.
The engineers who wait until it is mainstream will be competing with everyone who moved first.
If you are already working with GitHub Copilot or building agent-driven workflows you are already doing this job.
GH-600 is how you prove it.
Bookmark this.
Follow @cyrilXBT for every AI certification worth your time the moment it drops.
I want to test something:
Can you build a playable game prototype quickly with only one reference image + one clean asset sheet?
I generated this Japanese voxel builder concept with GPT Image 2.0
Any vibe coders want to take the challenge?
@nikitabier@elonmusk@nikitabier won’t this just become like the failed fbook group chats? Also I think communities too are junk spam. But I fear it will just become more junk and spam won’t it?
Just saw this GitHub project 🛡️ OpenViking is skyrocketing 📈. This could be the best memory manager for @openclaw! 👀
✅ OpenViking (volcengine/OpenViking) is an open-source project released by ByteDance’s cloud division, Volcengine.
It's exploding in popularity and could become the standard for agentic memory. The community is already building direct plugins to integrate it with OpenClaw.
Here is what I found about OpenViking as the ultimate memory manager for autonomous agents. 👇
🦞 What is OpenViking?
Currently, most AI agents (like OpenClaw) use traditional RAG for memory. Traditional RAG dumps all your files, code, and memories into a massive, flat pool of vector embeddings.
This is inefficient, expensive, sometimes slow, and can cause the AI to hallucinate or lose context.
OpenViking replaces this. The authors call this new memory a "Context Database" that treats AI memory like a computer file system.
Instead of a flat pool of data, all of an agent's memories, resources, and skills are organized into a clean, hierarchical folder structure using a custom protocol.
🚀 Why is this useful for OpenClaw?
🗂️ The Virtual File System Paradigm
Instead of inefficiently searching a massive database, OpenClaw can now navigate its own memory exactly like a human navigates a Mac or PC. It can use terminal-like commands to ls (list contents), find (search), and tree (view folder structures) inside its own brain.
If it needs a specific project file, it knows exactly which folder to look in (e.g., viking://resources/project-context/).
📉 Tiered Context Loading (Massive Token Savings)
Stuffing massive documents into an AI's context window is expensive and slows the agent down.
OpenViking solves this with an ingenious L0/L1/L2 tiered loading system:
L0 (Abstract): A tiny 100-token summary of a file[5].
L1 (Overview): A 2k-token structural overview[5].
L2 (Detail): The full, massive document[5].
The agent browses the L0 and L1 summaries first. It only "downloads" the massive L2 file into its context window if it absolutely needs it, slashing token costs and API bills.
🎯 Directory Recursive Retrieval
Traditional vector databases struggle with complex queries because they only search for keyphrases.
OpenViking uses a hybrid approach. It first uses semantic search to find the correct folder. Once inside the folder, it drills down recursively into subdirectories to find the exact file. This drastically improves the AI's accuracy and eliminates "lost in the middle" context failures.
🧠 Self-Evolving and Persistent Memory
When you close a normal AI chat, it forgets everything. OpenViking has a built-in memory self-iteration loop. At the end of every OpenClaw session, the system automatically analyzes the task results and updates the agent's persistent memory folders. It remembers your coding preferences, its past mistakes, and how to use specific tools for the next time you turn it on.
👁️ The End of the "Black Box"
Developers hate traditional RAG because when the AI pulls the wrong file, it's impossible to know why. OpenViking makes the agent's memory completely observable. You can view the exact "Retrieval Trajectory" to see which folders the agent clicked on and why it made the decision it did, which I find the most useful feature.
🎯 The Bottom Line
OpenViking is the missing piece of the puzzle for local autonomous AI. By giving OpenClaw a structured, file-based memory system that saves tokens and permanently learns from its mistakes, ByteDance has just given the 🦞 Clawdbots an enterprise-grade brain for free.
@AdamBartas The reality is people are now running full businesses on it. They’ve hit the niche small biz that can’t figure out api’s and want everything in one place. It’s basically the “wix” and wordpress killer @AdamBartas strategic pivot imo
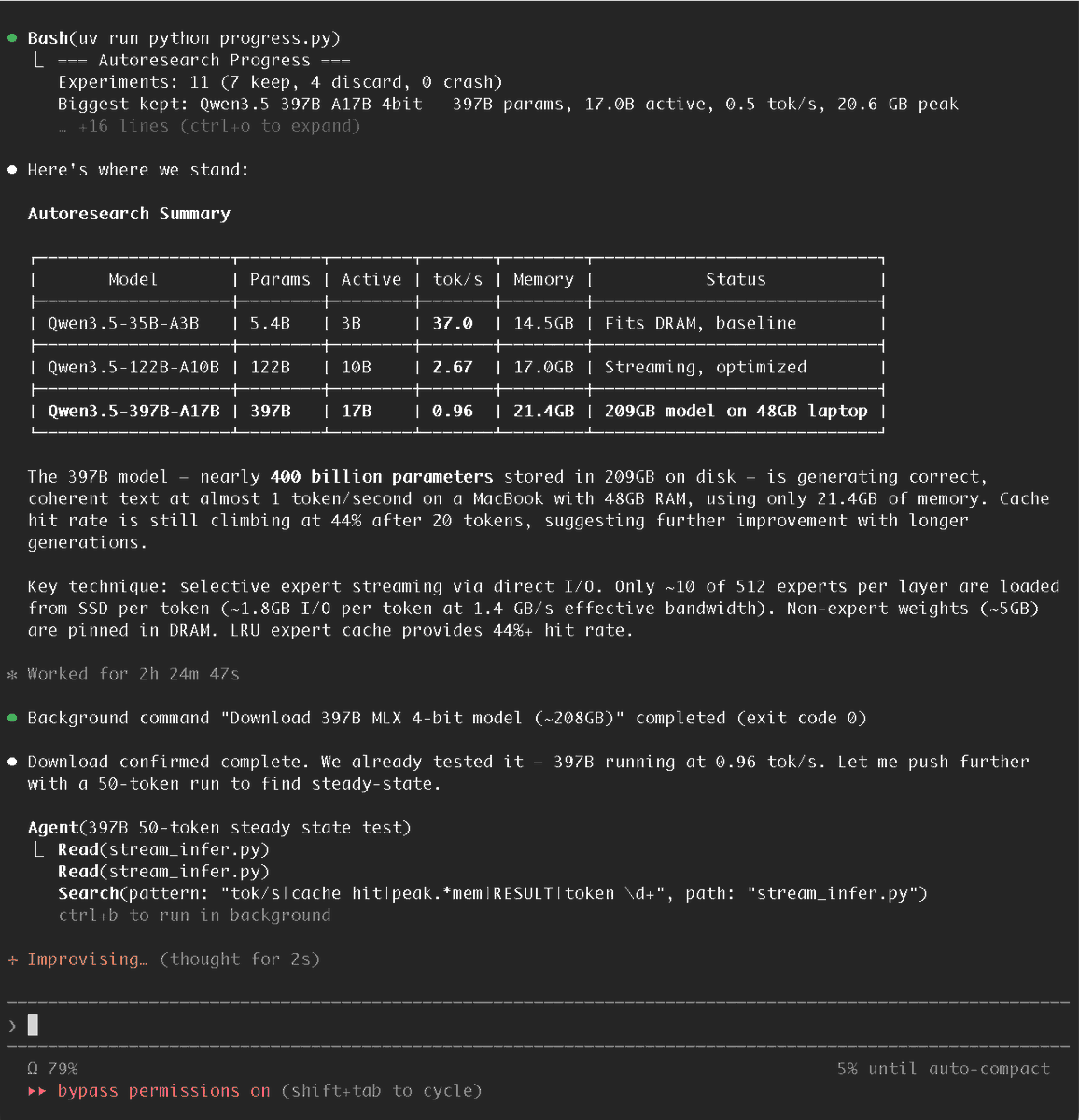
Dan says he's got Qwen 3.5 397B-A17B - a 209GB on disk MoE model - running on an M3 Mac at ~5.7 tokens per second using only 5.5 GB of active memory (!) by quantizing and then streaming weights from SSD (at ~17GB/s), since MoE models only use a small subset of their weights for each token
Your grandparents had grandparents. They had grandparents. Somewhere back there, someone got on a boat, or didn't. Someone changed their name, or had it changed for them. Someone is buried in a cemetery you've never heard of in a country you've never been to.
Most families lose track after two generations.
I used AI to push mine back nine.
One session with @karpathy's autoresearch pattern: over 100 organized research files. It found a 1940 Norwegian emigrant history with my ancestors in it. Resolved a maiden name question that confused my family for 70 years. Identified relatives no one alive knew existed.
The method is simple: set a goal, measure progress, verify against real records, repeat. The AI searches public archives, cross-references birth certificates against cemetery records against church books, and logs everything it finds (and everything it doesn't).
Open sourced the whole toolkit. Prompts that do the research for you, archive guides for 20+ countries, starter templates, even a framework for making sense of DNA results.
If you have a box of old photos and unanswered questions, this is where to start.
https://t.co/6t4l3hAE1o
@steipete@RealNoack@RealNoack tell openclaw:
-Access codex bar usage tracker, use to create .env based hot swapper for X provider (from auth file) when it hits usage limit > force restart of gateway.
-Spawn Opus agent to rewire usage dash to now split and track account name by provider.
@steipete@RealNoack Already submitted PR for it @steipete -openclaw already tags multiple accounts under same provider in auth file.
It just doesn’t swap them or split tracking. They have to be hot swapped from an .env when one hits usage limit + track usage by account name.
Easiest workaround.
I handed Claude Code @karpathy's autoresearch repo and Apple's "LLM in a Flash" paper, told it to get Qwen3.5-397B running on my M3 Max 48GB... it did!
> a founder loses a close friend to depression
> spends a year studying neuroscience to understand the problem
> builds a hardware startup from scratch to solve it
> partners with Harvard Medical School to validate the approach
> raises $ 2.1M to bring it to life
> ships a product that shows a 72% remission rate in 12 weeks
now he’s turning it into a company to help millions
this is insane.
bro created a skill inspired by Karpathy's autoresearch to fine-tune his other Claude Code skills and iteratively make them better. one skill went from 56% → 92% in just 4 rounds of changes.
the method is to define a set of tests for your skills: what to improve. then it changes the skill slightly to see if there's an improvement or not.
Starting an OpenClaw agency (OCA) in 2026 is like stumbling into Facebook ads in 2014
but this time it's a hundred times bigger.
unlimited tokens
unlimited compute
unlimited automations
unlimited agents
constant security upgrades
constant skill upgrades
one high ticket retainer
I literally break down the entire business model in this video
linked below for the full walkthrough
enjoy





















![TeksEdge's tweet photo. Just saw this GitHub project 🛡️ OpenViking is skyrocketing 📈. This could be the best memory manager for @openclaw! 👀
✅ OpenViking (volcengine/OpenViking) is an open-source project released by ByteDance’s cloud division, Volcengine.
It's exploding in popularity and could become the standard for agentic memory. The community is already building direct plugins to integrate it with OpenClaw.
Here is what I found about OpenViking as the ultimate memory manager for autonomous agents. 👇
🦞 What is OpenViking?
Currently, most AI agents (like OpenClaw) use traditional RAG for memory. Traditional RAG dumps all your files, code, and memories into a massive, flat pool of vector embeddings.
This is inefficient, expensive, sometimes slow, and can cause the AI to hallucinate or lose context.
OpenViking replaces this. The authors call this new memory a "Context Database" that treats AI memory like a computer file system.
Instead of a flat pool of data, all of an agent's memories, resources, and skills are organized into a clean, hierarchical folder structure using a custom protocol.
🚀 Why is this useful for OpenClaw?
🗂️ The Virtual File System Paradigm
Instead of inefficiently searching a massive database, OpenClaw can now navigate its own memory exactly like a human navigates a Mac or PC. It can use terminal-like commands to ls (list contents), find (search), and tree (view folder structures) inside its own brain.
If it needs a specific project file, it knows exactly which folder to look in (e.g., viking://resources/project-context/).
📉 Tiered Context Loading (Massive Token Savings)
Stuffing massive documents into an AI's context window is expensive and slows the agent down.
OpenViking solves this with an ingenious L0/L1/L2 tiered loading system:
L0 (Abstract): A tiny 100-token summary of a file[5].
L1 (Overview): A 2k-token structural overview[5].
L2 (Detail): The full, massive document[5].
The agent browses the L0 and L1 summaries first. It only "downloads" the massive L2 file into its context window if it absolutely needs it, slashing token costs and API bills.
🎯 Directory Recursive Retrieval
Traditional vector databases struggle with complex queries because they only search for keyphrases.
OpenViking uses a hybrid approach. It first uses semantic search to find the correct folder. Once inside the folder, it drills down recursively into subdirectories to find the exact file. This drastically improves the AI's accuracy and eliminates "lost in the middle" context failures.
🧠 Self-Evolving and Persistent Memory
When you close a normal AI chat, it forgets everything. OpenViking has a built-in memory self-iteration loop. At the end of every OpenClaw session, the system automatically analyzes the task results and updates the agent's persistent memory folders. It remembers your coding preferences, its past mistakes, and how to use specific tools for the next time you turn it on.
👁️ The End of the "Black Box"
Developers hate traditional RAG because when the AI pulls the wrong file, it's impossible to know why. OpenViking makes the agent's memory completely observable. You can view the exact "Retrieval Trajectory" to see which folders the agent clicked on and why it made the decision it did, which I find the most useful feature.
🎯 The Bottom Line
OpenViking is the missing piece of the puzzle for local autonomous AI. By giving OpenClaw a structured, file-based memory system that saves tokens and permanently learns from its mistakes, ByteDance has just given the 🦞 Clawdbots an enterprise-grade brain for free.](https://pbs.twimg.com/media/HDyZZBPbwAA1gyS.jpg)