Introducing Devin Desktop: the next generation of Windsurf
Manage fleets of local and cloud agents from one surface
Support for any ACP-compatible agent
With a full IDE for when you need to jump into the code
dunno what patience/perseverance means to other people, but for me it's literally gritting my teeth and yelling at myself in my head to just fkin focus and do the thing for long periods of time. it's **exhausting**. I wish I had the calm of the truly zen ones (if they exist?)
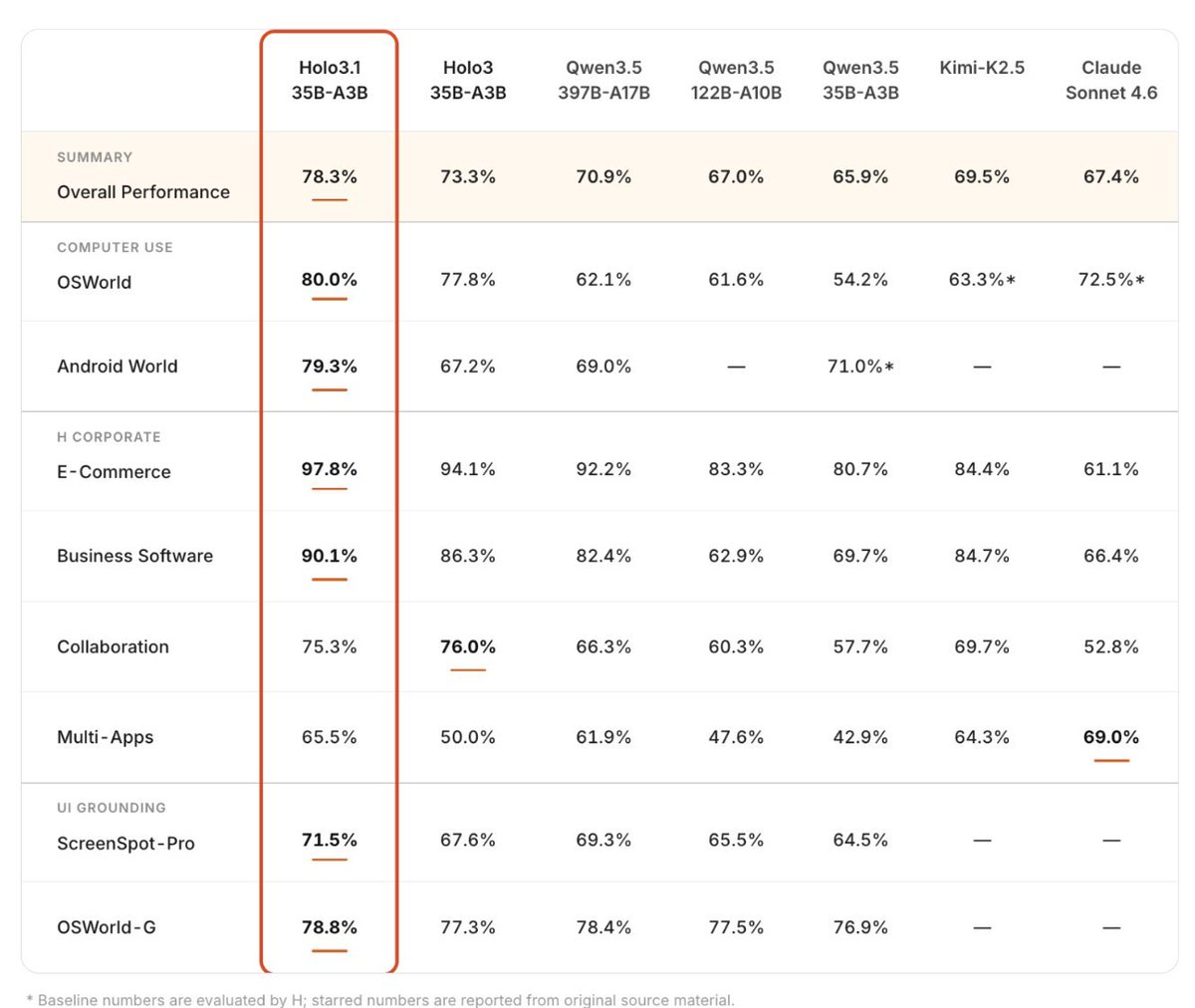
🌞This is big Local AI news! A new open-source Computer-Use LLM has just launched.
Holo 3.1 is H Company’s (🇫🇷) new local computer-use agent model that beats Qwen3.5-397B, Kimi-K2.5, and Sonnet 4.6!
Since it is built for local deployment →
⬩ Runs fully on your machine (MacBook, Windows PC, DGX Spark, RTX Spark)
⬩ Based on Qwen architecture, specialized for GUI understanding & computer control
⬩ Optimized checkpoints: NVFP4, FP8 & Q4 GGUF (0.8B to 35B sizes)
⬩ Strong gains: 79.3% on AndroidWorld benchmark (35B model)
💻 Comparison to Qwen3.5:
Holo 3.1 is fine-tuned specifically for computer-use agents (screen understanding, planning, clicking, navigation). Better at real GUI tasks than general-purpose Qwen3.5, especially when running locally.⚡
Today, we’re excited to introduce Miso One, the most emotive voice model in the world.
Miso One is an 8-billion-parameter text-to-speech model for highly expressive speech generation. It emotes like a human and responds faster than a human, with just 110 milliseconds of latency.
We’ve open-sourced the model weights, with API access coming soon.
Hear how Miso One sounds in the thread below.
.@GoogleDeepMind's Gemma 4 - 12B is available on Ollama!
Chat:
ollama run gemma4:12b-mlx
Hermes Agent:
ollama launch hermes --model gemma4:12b-mlx
Claude Code:
ollama launch claude --model gemma4:12b-mlx
and more 👇👇👇
(Note, this currently works via MLX)
Big congrats to the @ideogram_ai team on v4.
We tested it blind against @GeminiApp 3.1, Grok @imagine, and @bfl_ai FLUX.2 [max] with
>10 professional designers
> across 240 images
Quick thread on it's strengths and how to prompt it 👇
Today, we’re launching Reve 2.0, the best 4K image model in the world.
We invented a new way to generate and edit any image using precise layouts. For the first time, it’s possible to create images you can touch.
Gemma 4 12B is here!
Dense, mid-sized Gemma that fits right on your laptop - released by @google under Apache 2.0
Available now in LM Studio https://t.co/EgqHVOj2bY
i just ran Google's brand new Unsloth Gemma4 12B dense GGUF on my RTX 4060 using llama.cpp + CUDA 13.2
21 tokens per second. on a budget consumer GPU. locally.
no API. no cloud. no subscription.
and the benchmarks are absolutely cooked
# first let's talk architecture because this is genuinely different
every multimodal model you've used has a frozen vision encoder + frozen audio encoder + LLM backbone glued together
Gemma 4 12B is different
it's a single decoder only transformer. that's it. vision? raw 48×48 pixel patches → one matmul → projected directly into the LLM
audio? raw 16kHz signal sliced into 40ms frames → linear projection → same LLM input space
no encoder tax. no latency penalty. no fragmented memory
to put the encoder savings in perspective:
old Gemma 4 26B approach:
- 550M param vision encoder (frozen)
- 300M param audio encoder (frozen)
- LLM backbone
Gemma 4 12B:
- 35M param vision embedder (a single matmul)
- no audio encoder at all
- LLM backbone handles EVERYTHING 550M → 35M for vision alone. that's a 15x reduction
this is why the gemma-4-12b-it-Q4_K_M.gguf is just 6.6 GBs!!!
and it has 256K native context context
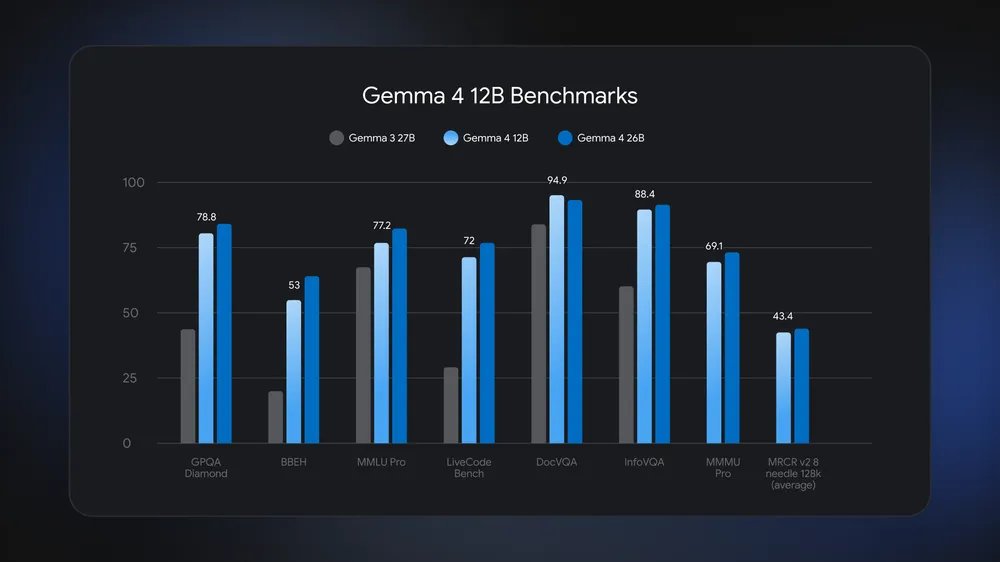
# Benchmarks:
AIME 2026 (math olympiad): 77.5%
GPQA Diamond (expert science): 78.8% LiveCodeBench v6 (real code): 72%
Codeforces ELO: 1659
MMLU Pro: 77.2%
MATH-Vision: 79.7%
BigBench Extra Hard: 53%
inference → llama.cpp, LM Studio, vLLM, SGLang
llamacpp flags:
-m "gemma-4-12b-it-Q4_K_M.gguf" -ngl 99 -c 8000 -v --port 8080
Available on huggingface now! Link below
this is the part of the open-source push i actually love.
google dropped a 12b clanker that eats text, image, video and audio natively, no separate encoders, apache 2.0, 256k context. at bf16 it's ~24gb, lands on a single 3090.
they say it nears their own 26b moe at under half the memory. bold claim. the real question is whether a 12b can take qwen 3.6 27b dense, the current king on my bench on single 24gb vram tier. so i'm running it. receipts incoming soon anon.