🎉 Happy to share that CHIMERA has been accepted to #ACL2026NLP (main conference)!
📄 Paper - https://t.co/11tMhA07P2
🤗 Data - https://t.co/g8GgYsfj9E
🌐 Project Page - https://t.co/c4j8gEm6V5
💻 Git - https://t.co/lVC8UAzOti
Joint work with @Hoper_Tom
Ever used a top-ranked LLM that just... felt wrong for you?
You’re not alone. Instead of leaderboards, many of us turn to "vibe-testing" - manually comparing models to our own needs. But can we turn these feelings into a structured evaluation?
New paper: "From Feelings to Metrics" 🧵
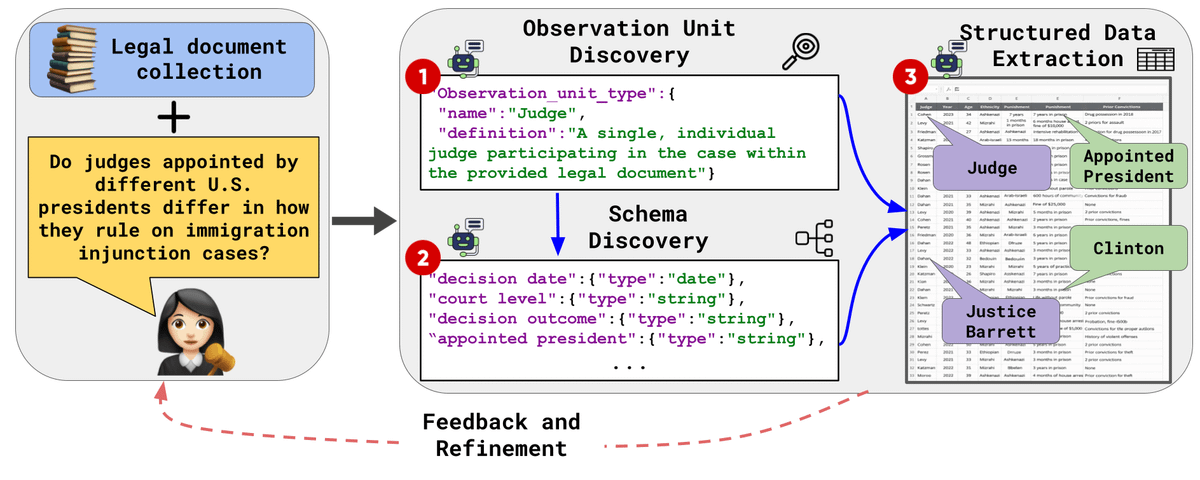
What if you could automatically turn a large collection of documents into structured databases, tailored for your own research needs?📄
We introduce ScheMatiQ!
From question ➝ schema ➝ structured data 🔍
@ShaharLevy19@MintzReshef@RKeydar@BarakRaveh@GabiStanovsky
🧵
👇1/5
Today at #EACL2026 we present our work exploring PRINTED newspapers as a data source for summarization in low-resource languages.
Join the virtual session at 18:00!
🧵👇
4. A spicy take 🌶️
In current multimodal models, the text component does most of the work. Vision components are comparatively weak- meaning there's still a lot of room for real progress there.
4 takeaways from conversations with some very sharp minds during my recent visit to Cambridge & University of Edinburgh 🇬🇧 A short thread👇
1. Strong consensus: classic LLM tasks in standard setups (QA, summarization, etc.) are seen as sovled and are not interesting anymore.
3. On multimodality: mixed opinions on whether "classic" image+text is saturated.
But near-universal agreement that video and 3D remain wide open and underexplored.
New preprint 💥
Can a general-purpose model achieve results comparable to medically pre-trained models? 🤔
We show that lightweight fine-tuning of a general-purpose LVLM and an LVLM-aware retriever can. 🚀
🔗 GitHub: https://t.co/vbHBIyoNgj
📄 Paper: https://t.co/Q8tKLk8J1P
I'll be visiting the UK at the end of January (26–29 London, 29–30 Edinburgh) and giving a talk in @frank_e_keller 's group on the 30th. If you’re into multimodality, interactive learning, or language games and will be around- ping me!
Great time @iscol_meeting! We presented twp works:
• https://t.co/stJN1YC0p6: Do different languages mention different objects in the same image? (w/ @PontiEdoardo )
• https://t.co/E4HGn7v4Tn: Can models decide when to speak and play Mafia? (w/ @niveckhaus@GabiStanovsky )
Honored to have been part of the ISCOL 2025 panel with such great professors! @yoavgo@melhadad
It was an interesting discussion on AI’s role in academia and research, with diverse opinions and challenging perspectives.
Thanks @iscol_meeting and @ella_rabinovich for having me!
3/🛠️ Improvement: Finally, we used these insights to build better systems:
• Improving models using reformulation feedback: https://t.co/R23O5J2H7r
• Making evaluation metrics actually reflect human preferences: https://t.co/TdMVA2ip35
I’m thrilled to announce that I have successfully defended my PhD! 🎓🥂
Huge thanks to my advisors Gabi Stanovsky, Omri Abend, and Lea Frermann for their mentorship
My goal: Making Vision-Language Models (VLMs) more human-like. 🧵👇
2/ 🗣️ Human Insights: Next, we looked at how humans actually generate language:
• How visual inputs affect our syntax: https://t.co/48HMeDz9E0
��� How our cultural background shapes what we choose to describe: https://t.co/stJN1YBszy
Excited to present our paper "ReliableEval: A Recipe for Stochastic LLM Evaluation via Method of Moments" at #EMNLP2025 🎉
Everyone knows LLMs are prompt-sensitive, yet we still report single-prompt scores.
Our work suggests a method to make evaluation statistically reliable!
I can't make it to #EMNLP2025, but @EliyaHabba and @GiliLior will present our PromptSuite🌈(demo!): a framework tackling prompt sensitivity by generating benchmark variations for any task.
Try it with just a few lines of code or the web interface!
https://t.co/C4VwIvAhvv