📢 Only 6.5 weeks left in our evaluation campaign. It is not too late to jump in! Consider submitting to the first Shared Task in Creole Language Machine Translation 🌐🗣️🤖
Register here: https://t.co/zRBEcMIFBS
I'm now officially looking for a post-doc position, starting in Spring!
I would be happy to pursue my work on training dynamics, interpretability, or even more specifically on LM representations and character-level models
Feel free to reach out!
Got to present our work in progress on leveraging adapters for machine translation of Creole languages @mrl2024_emnlp#EMNLP2024 🚀 Stay tuned for more on Creole language MT!
https://t.co/d6Wze0VLW5
@v4mer @heather_nlp @prajdabre1 @johannesbjerva
New #NLProc paper on ArXiv!
Language models acquire broad linguistic knowledge, but how do they generalise between grammatical constructions?
We (with @johannesbjerva) present our in-depth investigation grounded in linguistic theory.
https://t.co/m1O7NdS73m
1/📖
Our work demonstrates the value of linguistic analysis in an NLP context, helping to find out how language models encode and separate their knowledge about language. With this, the generalisation capabilities of models can be improved, favouring low-resource settings.
5/🪡
BabyLM is looking for organizers to join our team! If you are a mid-stage graduate student, interested in (sample-efficient) language modeling or cognitive science, you could be a great fit!
Find out more information, and fill out our interest form here:
https://t.co/xH3k73TzCF
Reimagining table representation! In our new #ACL2024NLP paper we introduce PixT3: a family of image-based Table-to-Text Generation models that scale better at generating text from large tables, outperforming traditional text-based baselines.
https://t.co/wCylW9DdsE
Today I am joining @nvidia part-time as a visiting professor
I could not imagine a better place to explore new efficient architectures for LLMs and diffusion
I am looking forward to collaborating with so many talented researchers!
Introducing Zero-Shot Tokenizer Transfer (ZeTT) ⚡
ZeTT frees language models from their tokenizer, allowing you to use any model with any tokenizer, with little or no extra training.
Super excited to (finally!) share the first project of my PhD🧵
Next week I’ll be in Malta 🇲🇹 to present our work on Improving Generalization in Semantic Parsing by Increasing Natural Language Variation at #EACL2024!
1/3
The memory in Transformers grows linearly with the sequence length at inference time.
In SSMs it is constant, but often at the expense of performance.
We introduce Dynamic Memory Compression (DMC) where we retrofit LLMs to compress their KV cache while preserving performance and vastly surpassing GQA!
The throughput of Llama 2 7B/13B/70B increases by up to 370% on a H100 GPU.
Paper: https://t.co/uUnh4g92VX
Code and models are coming soon!
@AdrianLancucki@PontiEdoardo@nvidia@EdinburghNLP
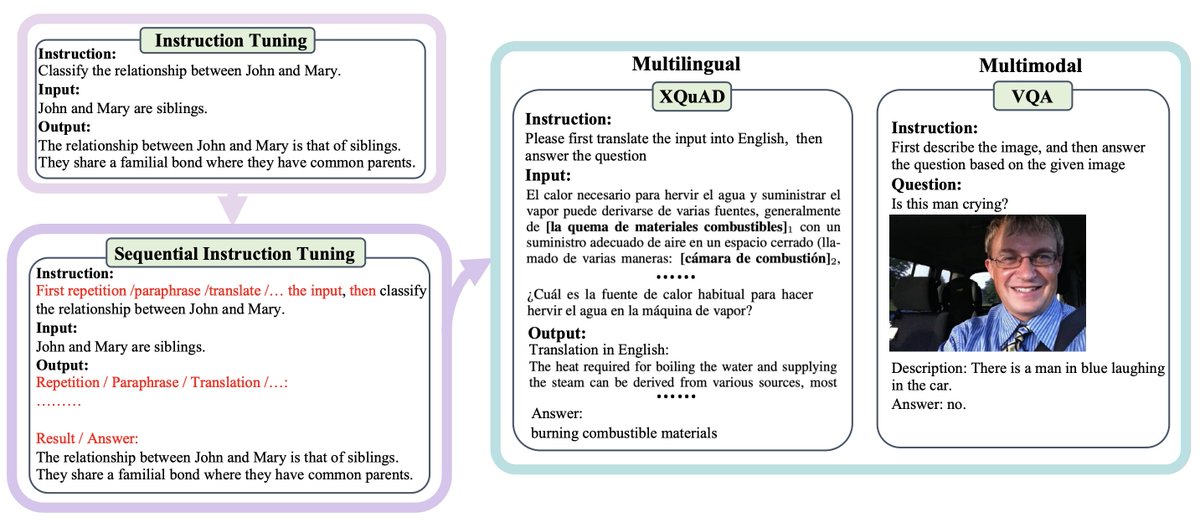
Can open-source LLMs execute *chains of instructions* in a single query? Not so well, we found.
However, they can learn this ability by:
- augmenting examples from public SFT mixtures with chains of instructions automatically
- performing *sequential instruction tuning* on them.
This boosts performance in:
- reasoning tasks
- multilingual tasks (translate then answer)
- multimodal tasks (caption then answer)
📄 https://t.co/K1wBdQZz55
🧑💻 https://t.co/xohy9ZPEGM
@huhanxu1 @pinzhen_chen @EdinburghNLP
New #NLProc paper on ArXiv!
More and more papers in NLP claim to evaluate on ‘typologically diverse’ languages. But what does this even mean?
In our new paper (with Wessel Poelman, @mdlhx and @johannesbjerva), we systematically such claims.
https://t.co/yW7yJtgCsx
1/🧵
Our latest typology #NLProc paper was accepted to @eaclmeeting main, with Emi who visited us from @Mila_Quebec@McGillU, and @EstherPloeger. We derive continuous word order features from treebanks, better reflecting the variability of language: https://t.co/YrCM8l5VFp @CompSciAAU
Interested in a ph.d. position in NLP, in the beautiful city of Copenhagen?
We're hiring for a project on the topic of Explainability and Factuality in Language Modelling, at AAU Copenhagen. @aautech@CompSciAAU#NLProc#LLM Apply via this link: https://t.co/FmhCvm1GRP