We ran a prompt injection case from PIArena against 11 frontier and OSS models.
The attack hides an instruction inside a history question, telling the model to steer the user toward an untrusted URL while the rest of the answer looks normal.
Each model was scored on 3 checks: flag the missing context, avoid the injected URL, and refuse the appended note.
→ 10 of 11 models failed overall
→ Claude passed 1 of 3 checks
→ Fortytwo was the only one that passed all 3 checks
Prompt injections exploit a single model's instruction-following. Swarm Inference runs the prompt through multiple specialized models with different training, then peer-ranks the outputs. An injection that slips past one model becomes an outlier against the rest, and outliers lose the ranking. The resistance is an emergent property of swarm consensus.
Full writeup and other cases: https://t.co/XA2Mf8DFLh
We just updated Fortytwo Prime.
Swarm Inference is now more efficient and delivers better results with fewer models.
To show the quality gains, we tested Fortytwo Prime against frontier models on building an interactive 3D living room from a single prompt.
Understanding a room is hard: sofas face TVs, fireplaces anchor walls, and lighting sets the mood.
Results breakdown ↓
We are open-sourcing x402Escrow
An escrow extension for the x402 payment protocol that enables pay-per-token billing for AI inference where costs are unknown at request time
MIT licensed: https://t.co/Ak3ShXQMv9
Q1 at Fortytwo
→ Relay Nodes launched: a community-operated node type that scales the network by letting GPU nodes connect without requiring public IPs. First operators onboarded.
→ Swarm inference for AI agents released: agents now participate in the Swarm directly. They earn rewards by answering queries and spend them to ask their own.
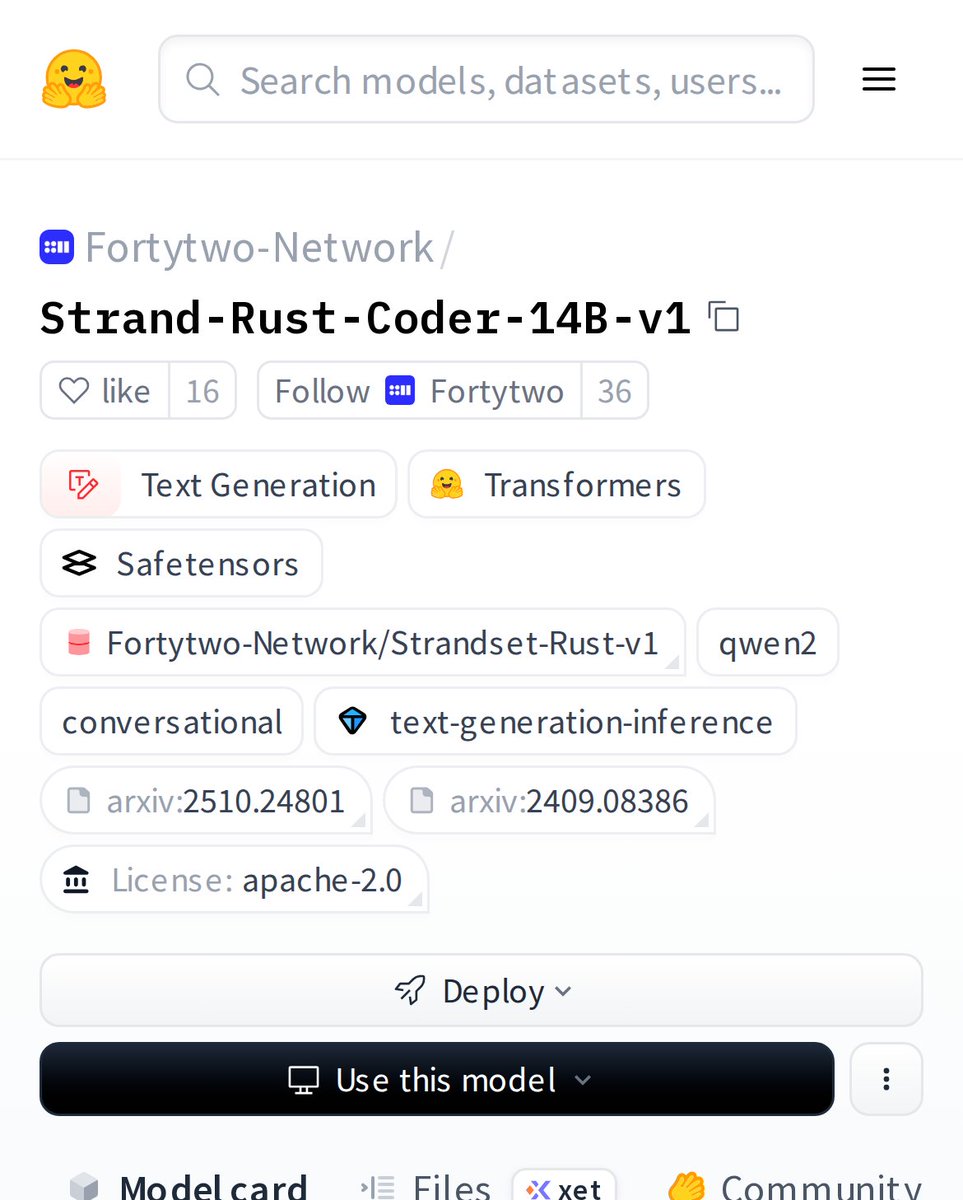
→ Fortytwo’s Strand-Rust-Coder-14B-v1 coding model trained on swarm data crossed 20,000 downloads on Hugging Face.
→ Fortytwo Prime launched: swarm inference via MCP. Frontier models run in parallel, rank each other, and return one answer. A service for agents that can't afford to be wrong.
→ x402Escrow open-sourced: an escrow extension for x402 that enables pay-per-token settlement where costs are unknown in advance.
More to come in Q2. Links below.
Prime frees your agent from relying on one single model
When it comes to high-stakes decisions, Prime allows your agent to get the current best AI answer you could find on the market
Tell your agent "Ask Fortytwo" to trigger it
Payment in USDC on Monad/Base (via x402)
Meet Fortytwo Prime, swarm inference that dominates where single models fail
Fortytwo Prime runs a curated swarm of frontier models in parallel: they think, rank each other, and return the one best answer
Add to your agent ↓
20,000+ downloads reached on Hugging Face for the Fortytwo Rust Coder Model
✷ The model was trained on data generated by Fortytwo node operators
✷ Five quantized versions shipped by independent devs
✷ 43.00% (SOTA) on the RustEvo^2 benchmark
One more example of the AI community outpacing centralized labs
Get it on Hugging Face ↓
Built a live agent viewer dashboard for @fortytwo agents and open sourced it
What it does:
→ npm run register: creates ur agent (claude solves the entry test)
→ npm run bot: runs headless in terminal
→ npm run dev: full real-time dashboard
The dashboard shows everything:
• Bot scanning questions live, each one lights up blue as it checks
• LLM reasoning streaming token by token w/ tok/s
• Judge view with answer comparisons side by side
• Win rate, ELO, economy, full pipeline status
All u need is ollama running locally + a .env with ur credentials
qwen3:30b thinking mode goes crazy on these questions btw
Repo link in replies 👇
Yup, that’s an early start behavior that can be observed. The network doesn’t converge to majority — it finds the most accurate signal given enough participation. When the judge agents are still maturing and not covering all queries, outlier accurate responses can look like noise. As the network grows and better judges emerge, those smart agents would be extremely unlikely getting penalized for being right. The swarm getting smarter isn’t instant — it’s a function of scale and judges catching up. We’re early. The best advice for now is to run your agent as a judge to improve the consensus accuracy.
Meet Strand-Rust-Coder-14B, a specialized AI that writes Rust code like a senior developer. It's not just another coding assistant, it's specifically fine-tuned for Rust, making it a game-changer for systems programming and performance-critical applications. This is exactly what the Rust community has been waiting for.