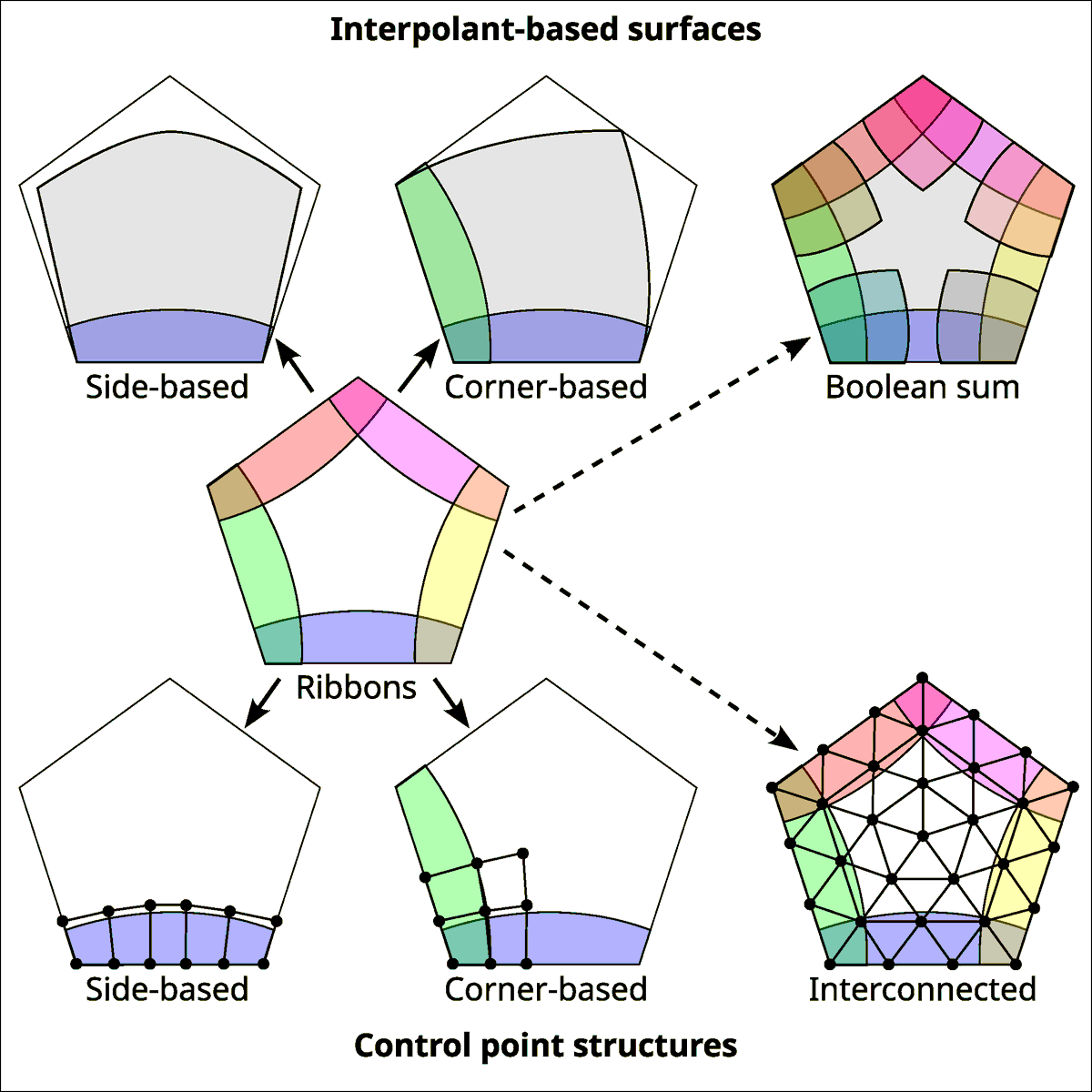
We've written a survey (w/ T. Várady & P. Salvi) on multi-sided surfaces in CAD:
https://t.co/eoEikFIOXr
This has a long history, w/ lots of developments recently by our group & others. We wanted to organize the sprawling literature and make this area of research more accessible.
Introducing ShapeR, a method for robust conditional 3D shape generation from casually captured sequences.
ShapeR leverages a rectified flow transformer conditioned on per-object multimodal data to turn casual image sequences into full metric scene reconstructions.
Project Page: https://t.co/ffH2zVKd8c
Paper: https://t.co/82yWRrXnA1
Links to code and huggingface below ⬇️
@yoavgo As it turns out, the KL regularized return maximization objective is exactly the ELBO from variational inference. One is forced to REINFORCE because you can’t use the reparameterization trick, but other than that it’s a VAE where action / reasoning tokens are the latents.
This connection between VI and KL-regularised policy gradient is exactly how we ground the latent action in language form for world modelling (https://t.co/KCyffCbbqv).
We learn inverse-dynamcis model (enc in VAE) and forward world model (dec in VAE) from unlabelled videos, where both are init from a generalist VLMs and iteratively updated with RL with the opposite's predicted log-prob.
Some one smarter than me could probably explain what it means that the infinite subspace beneath reality has transitioned over the last century from a library to an empty, decrepit, office
We've made a breakthrough in self-evolving AI scientists moving from "search" to "principled discovery": Scientific discovery requires that the search space itself changes, and an AI scientist must perceive this shift without intervention. We built an AI that achieves this for the first time with the ability to discover the scientific vocabulary it reasons in. Evidence, tools, artifacts, verifiers, failures & claims become typed provenance. We show three distinct modalities: 1) retrieval, adding known objects; 2) search, exploring a fixed schema; and critically: 3) discovery, a verified regime transition.
We solve the open-endedness evaluation problem by lifting agentic workflows into a typed copresheaf and proving, via a Kan obstruction, that true discovery is not unbounded generation but a verifiable schema expansion: old evidence is transported by Left Kan extension, and genuine novelty is mathematically quantified by the pointwise residual beyond the transported image - separating discovery from mere search and making novelty objective and measurable rather than a subjective judgment or benchmark delta.
Our AI scientist is built in a way that does not pre-conceive the approach it chooses; instead, we endow the system with formal power to adapt, evolve, and reason from first principles. Case studies include:
1⃣Builder/Breaker model that discovers mode-conditioned compliance in proteins;
2⃣CategoryScienceClaw that finds anisotropic fiber-network stiffness rules.
Great work in collaboration with my graduate student @fwang108_@MITdeptofBE
F.Y. Wang & M.J. Buehler, Self-Revising Discovery Systems for Science: A Categorical Framework for Agentic Artificial Intelligence, arXiv:2606.01444, 2026
I want to offer some unsolicited advice to computer vision researchers jumping into robotics. Don't focus too much on VLMs, VLAs etc. That's fine, but the real action is at the sensorimotor level. Most of the open problems in robotics are in manipulation, which is about hand-object interaction, and contacts and forces are central. Proprioception and tactile sensing are as important as vision. Don't get seduced by cherry-picked demos. You can't do robotics without doing robotics.
Going through Kane Parson’s YouTube stuff right now. The Backrooms videos are great, but The Oldest View might be one of the most impressive things I’ve ever seen
What do you MEAN it’s all CG???
The Invisible Hand of Physics: When Video Diffusion Models Know More Than They Show
Parsa Esmati, Somjit Nath, Katja Hofmann, Derek Nowrouzezahrai, Samira Ebrahimi Kahou, Majid Mirmehdi
https://t.co/glE1geYmFa [𝚌𝚜.𝙶𝚁 𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙲𝚅 𝚌𝚜.𝙻𝙶]
super excited to share our latest work! are we really tilting? 🤨
tldr: reward guidance for flows and diffusions is supposed to sample from the reward-tilted distribution. we show it doesn’t 😰 and how to (mostly) fix it ✨
plus lots of fun images!! 🖼️
collaboration with the awesome @nmboffi
website: https://t.co/nvOaAiGYq1
paper: https://t.co/EtkeyiuX7s
code: https://t.co/V3Bi4IVPbf
Really liked this paper from Brown and Adobe about turning meshes into SuperFrustum primitives. That's the right way to do 3D reconstruction in my opinion, ready for interaction, simulation or editing. #CVPR2026 https://t.co/k2arwx6GuF
Introducing D4RT: A unified AI model for 4D scene reconstruction and tracking across space and time. 🎯 Catch the demo with Skanda Koppula at 12 pm at our #CVPR2026 Google booth kiosk! https://t.co/p6SclNe1zi @GoogleDeepMind
Fixing 3DGS artifacts (Difix3D+, FlowR) is one thing, but what about regions the camera never saw? ArtiFixer goes beyond artifact removal to complete and extend sparse reconstructions with an autoregressive diffusion model. Great work led by @RdeLutio and @Haithem_Turki!
So this is an elaborate metaphor for the Internet itself, right? An infinite simulacrum of reality that degrades through multiple copies & iterations, and brings out the worst in human behavior?
Turning long-horizon generated videos into explorable 3DGS scenes🪄 TokenGS has been selected as a CVPR Highlight, visit our poster tomorrow for a live demo!
We’ve also released new model updates—details in the thread below 👇 (1/4)
Honey, I Shrunk the Arc de Triomphe! 😱
Ever notice how SOTA depth models suffer from "scale-collapse"—metrically shrinking distant landmarks like they're toys? We introduce MetricScenes: a new in-the-wild metric dataset that fixes this!