Human intelligence is fundamentally a collective intelligence. We solve complex problems by participating in a vast cultural network that builds upon ideas across generations.
I believe the strongest AI systems will become a collective intelligence, too.
Since we started Sakana AI, our core conviction has been that the most powerful AI systems will be collaborative ecosystems, not isolated monoliths. Evolution innovates under constraints, and the future belongs to systems that explicitly learn how to coordinate collective intelligence.
Today, we are taking a major step toward that future with the launch of Sakana Fugu.
Fugu dynamically orchestrates the world’s best models to tackle complex tasks. We are proving that a well-orchestrated pool of swappable agents can match restricted frontier models like Fable and Mythos.
But Fugu is about more than just performance. I believe that Orchestration Models are the next frontier, beyond bigger models.
Relying on a single company’s model for national infrastructure is a massive risk. As recent export controls have shown, access to top models can disappear overnight.
Collective intelligence is the practical hedge against this concentration of power. Fugu simply routes around vendor restrictions by relying on an entirely swappable agent pool.
I am incredibly proud of our Tokyo team for shipping this. By orchestrating the world’s models, we are delivering the resilient blueprint required for AI sovereignty.
Read our full vision and results here:
https://t.co/EONDdWx5Ld 🐡
Quite interesting thread on capabilities of real biological neurons (spoiler: they're way more capable than classical artificial neurons in a perceptron) . Nice work @IdoAizenbud and collaborators!
Very excited to share our interview with @polynoamial on AI for math — the Erdős unit distance problem, saturating the IMO, the future of math research, and more!
We've made a breakthrough in self-evolving AI scientists moving from "search" to "principled discovery": Scientific discovery requires that the search space itself changes, and an AI scientist must perceive this shift without intervention. We built an AI that achieves this for the first time with the ability to discover the scientific vocabulary it reasons in. Evidence, tools, artifacts, verifiers, failures & claims become typed provenance. We show three distinct modalities: 1) retrieval, adding known objects; 2) search, exploring a fixed schema; and critically: 3) discovery, a verified regime transition.
We solve the open-endedness evaluation problem by lifting agentic workflows into a typed copresheaf and proving, via a Kan obstruction, that true discovery is not unbounded generation but a verifiable schema expansion: old evidence is transported by Left Kan extension, and genuine novelty is mathematically quantified by the pointwise residual beyond the transported image - separating discovery from mere search and making novelty objective and measurable rather than a subjective judgment or benchmark delta.
Our AI scientist is built in a way that does not pre-conceive the approach it chooses; instead, we endow the system with formal power to adapt, evolve, and reason from first principles. Case studies include:
1⃣Builder/Breaker model that discovers mode-conditioned compliance in proteins;
2⃣CategoryScienceClaw that finds anisotropic fiber-network stiffness rules.
Great work in collaboration with my graduate student @fwang108_@MITdeptofBE
F.Y. Wang & M.J. Buehler, Self-Revising Discovery Systems for Science: A Categorical Framework for Agentic Artificial Intelligence, arXiv:2606.01444, 2026
Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
been asking others at Anthropic how they stay in the loop with Claude and fully understand the work being done
this is one of my favorites from Suzanne:
Getting zapped to live longer...is similar to doing regular exercise.
A brief pulse of electrical current rejuvenated aging colonial chordates (sea squirts and salps),
boosting stem cell function, regeneration, growth, and survival.
The treatment triggered a coordinated “reboot and rebound” program that shifted tissues from inflammatory decline toward repair and renewal—resembling exercise-like immunometabolic reprogramming that happens after exercise.
⚡🧬 #Aging #Regeneration #StemCells
https://t.co/zGLYv042mb
Since Opus 4.8 is out and more and more designers are getting into Design Engineering, I thought I’d share some of the interaction patterns I use most often:
Use proximity, not just hover. When the cursor gets close, nearby elements can subtly scale and darken based on distance.
It makes interfaces feel more responsive, less binary, and way more alive
onpointermove = e =>
document.querySelectorAll(".dock>*").forEach(el => {
const r = el.getBoundingClientRect();
const t = Math.max(0, 1 - Math.abs(e.clientX - r.x - r.width/2) / 120);
el. style.scale = 1 + t * .5;
});
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
When the gap between intent and action closes.
Gods will be born.
Then who becomes a powerful god. Will be defined by the strength and clarity of their intent.
A god is someone who can use raw energy to bend reality to match intent. Always has been.
ok actually insane paper published yesterday
a research group in Korea built a gene switch you can control wirelessly using electromagnetic fields
they exposed mice to 60 hz EMF (same frequency as your wall outlet) using a pair of large coils that generate a uniform magnetic field around the animal, for cyclic 3-day on / 4-day off pulses
they showed this could:
- activate OSK to do epigenetic reprogramming in progeroid and aged mice, extending lifespan and reversing aging markers across multiple tissues
- conditionally switch on mutant amyloid genes only in aged mouse brains, letting them separate aging effects from amyloid effects to study AD biology in a way previous models couldn't
no drugs, no impacts, just a magnetic field from outside the body
Pills for llm coding from an OpenAI talk at @aiDotEngineer :
- have single shared utils to do stuff like bounded concurrency
- treat errors as values and part of the control flow
- use telemetry for everything
- rely on static analysis for backpressure
Should we tell them???
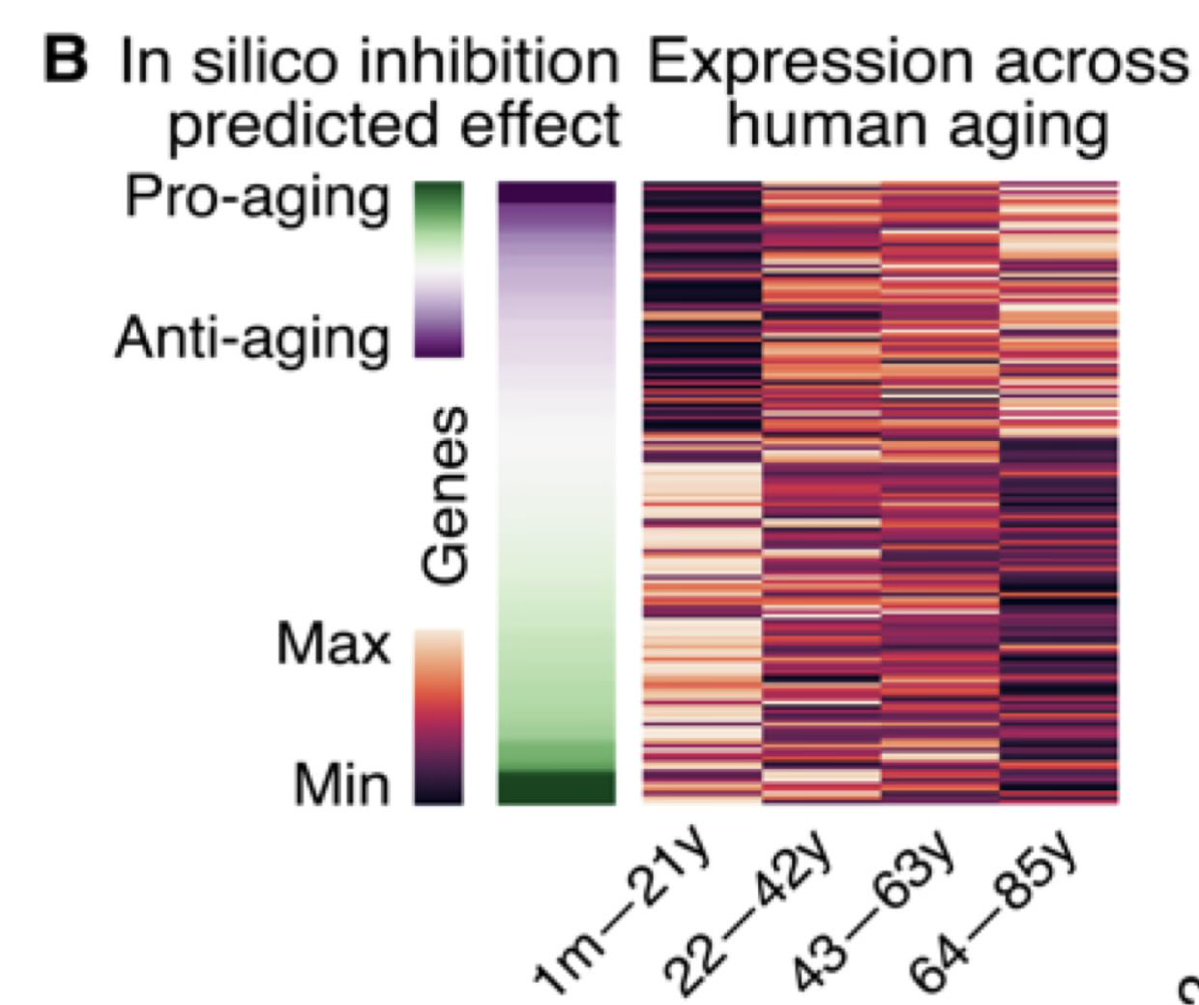
New paper @GladstoneInst@UCBerkeley@nvidia reinforces the Information Theory of Aging (ITOA).
Looking at 175M single-cell gene expression patterns, AI found cells lose their identity over time.
The model then predicted how to restore lost information to rejuvenate cells…🧵