📢LAMP demo code has been released, you can try it out on any any 👓Aria Gen2 👓sequence!
💻Code: https://t.co/1XTvUx9bbh
🔗Project: https://t.co/JtKU5GuHJE
"run the model on the robot: cloud is too slow."
been experimenting. Same VLA, same arms, same task.
our custom cloud engine: 5.1x faster compute. 1.7x faster end-to-end round-trip
(more in thread)
This giant free dataset could make helper robots way smarter, way faster:
An open-source robotics stack from Berkeley AI researchers featuring the largest teleoperation dataset released to date with over 3,500 hours of bimanual manipulation data across 200 tasks.
The video showcases autonomous bimanual robot performance on dexterous tasks including box folding, Lego sorting, AirPod insertion, t-shirt folding, backpack packing, and box unlocking using learned policies.
Sim-to-real correlations, training insights like flow loss predicting real-world success, lightweight infrastructure for DAgger interventions
Thank you for sharing, @ritvik_singh9, and everyone else who contributed to this!
Links to the paper plus dataset at https://t.co/4cNtRw02mf under permissive licensing.
——-
Weekly robotics and AI insights.
Subscribe free: https://t.co/9Nm01QUcw3
We trained π0.5 to do a simple task on our Metal Arm with just 20 episodes of data.
Everything collected on our own stack teleop with gravity compensation: https://t.co/vqXJuZ2Vcu
data collection script: https://t.co/SJitGy1BmU
openpi for the policy.
custom implementation of RTC @ 60hz. The smoothness difference speaks for itself.
@Ryan_Resolution@makermodsai
We are proud to release ABC-130K, the largest open bimanual manipulation dataset.
ABC-130K includes 130K+ trajectories covering 200 complex manipulation tasks. All are performed on a low-cost bimanual rig (YAM by I2RT).
The data is available under the highly permissive Apache 2.0 license.
@ed0henderson Operating it to grab something is awful😭. You have to stick two fingers through the ring, which feels super clunky and constantly gets stuck. So the end stage need improve!
Introducing Universal Manipulation Exoskeleton (UME)
A low-cost exoskeleton with real-time haptic torque feedback for learning autonomous policies that perform highly force-mediated, tightly space-constrained, visually occluded, whole-body, and long-horizon mobile manipulation tasks.
Using UME, the teleoperator can unsheathe a heavy metal sword completely blindfolded.
https://t.co/W3PHmYRm4q
🧵1/N
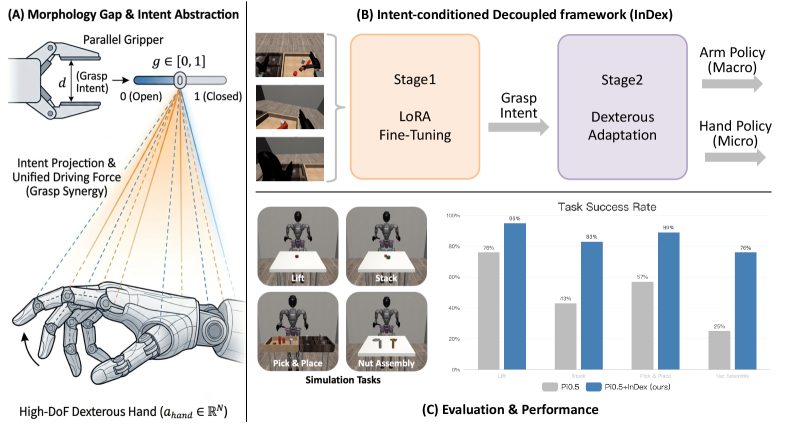
二本爪のグリッパで学習したロボット AI を、五本指ハンドにそのまま移植する手法が発表されました。形の違いを『どんな意図で動くか』で橋渡しします。
ロボット用基盤 AI モデルは、シンプルな二本爪のグリッパで学習させてある場合が大半で、五本指ハンドに移すと動作が崩れる問題がありました。新手法は、『この動きはどんな意図で行うか』を条件として AI モデルに渡し、形の違うエンドエフェクタへの移植を可能にします。
ヒューマノイド向けに学習済みの大規模 AI モデル資産を、量産現場での五本指ハンドにそのまま転用する道を作る方向性で、学習コストと運用コストの両方を下げる研究です。
Benchmarking World Models: Nvidia Cosmos 3 vs. Ctrl-World on the DROID dataset
Takeaways
- Ctrl-World shows better controllability
- Cosmos shows some weird artifacts as it rolls out
- Cosmos frequently hallucinates people 😂
This is not a completely fair comparison since Ctrl-World is fine-tuned specifically for DROID, and the code has many adjustments tuned specifically for controllability. It’s impressive that Cosmos does so well 0-shot!
A Stanford team trained humanoid pick-and-place policies on a Unitree G1 with zero teleoperation demos.
Sim data only.
And it matched or beat human teleop on every task.
The headline reads "teleop-free."
But the part worth stealing is how they made sim images real enough to actually transfer.
Most sim pipelines render the whole scene as mesh.
The images come out flat and fake, so the policy never crosses the sim-to-real gap.
LEGS renders only the robot and objects as mesh.
Then it drops them onto a 3D Gaussian Splat of the real room, a reconstruction trained against actual photos.
So the background is photorealistic, and the visual gap mostly closes.
On the hardest long-horizon task, teleop collapsed to 0/10.
Same across all three VLA backbones they tested.
The sim-trained policy still landed 2 to 6 out of 10.
The neat part: motion is recorded as a command stream, separate from how the scene looks.
So one recorded dataset re-renders under new rooms and new objects at GPU cost alone.
Covering a new scene drops from ~1.5 operator-hours to ~0.1 GPU-hours.
Worth being honest about the setup though.
SONIC runs the same whole-body controller binary in sim and on the robot.
So locomotion sim-to-real is already handled before LEGS even starts.
And the teleop baseline was a non-expert at 50 demos.
Read it as: photorealism plus procedural motion can replace teleop at the data step, in this setup.
The real lesson is the decoupling.
Once appearance and motion are separate, adapting to a new scene becomes a render job, not a collection job.
Nice work from the Stanford team
As many of you were interested in the technical details of the model, here is a followup thread to go more into technical details about VLA-JEPA.
1. Architecture
2. Training
3. Recipe for the demo
4. TLDR
🧵below