Unlock the full potential of your genomics analysis project! 🚀 Our whitepaper shows how 5th Gen Intel® Xeon® Processors and Altera FPGAs drive efficiency, consistency, and meet customer needs. #Genomics#TechInnovation#Intel#FPGA
https://t.co/QrbvsNUgWq
🚀Thrilled to partner with Yonsei University’s Mirae Campus & NUMP to advance rare disease research! Leveraging Intel® Xeon® processors & Altera® FPGAs, we’re speeding up genome sequencing for precision medicine breakthroughs.🔬
🎥 Watch here:https://t.co/Y4xQeQSueJ
Leap frog: We do a deep dive on MLPerf inference performance and cost for AMD MI300X and Nvidia H100, H200, and B200 GPUs. $NVDA $AMD
https://t.co/aUspfLsaq7
#RAG enhances the accuracy of #LLMs by retrieving information from external sources
This blog post explores the impact of increased context length on the quality of RAG applications
https://t.co/6RIvvXWLmY
#GenAI via @NaveenGRao
Building at Scale with #H100: #Eos as a DGX SuperPOD Reference Model for Large Data Center Builds
Presentation by @Nvidia’s Julie Bernauer (@JulieB_NV)
https://t.co/23BWcVq4cy
#AI#HPC#GPU#Top500
Tired of paying the Nvidia NVSwitch and InfiniBand premiums for AI clusters? You aren’t the only one. Nvidia’s rivals are taking both on with more open – and presumably cheaper – alternatives. $NVDA $AMD $INTC $AVGO $HPE $MSFT $META $GOOG
https://t.co/bMsOwrb8Uv
If you're studying #bioinformatics, there comes a time when you have to decide between:
- staying in academia
- going into industry
- give up #bioinformtics and do something else
Well, let me tell you what it was like for me to work as a #bioinformatics in the biotech industry! /1
SLATE: Software for Linear Algebra Targeting Exascale
Providing a new and improved dense linear algebra library for #exascale#supercomputers
https://t.co/AtFjvyiFpd
#HPC via @insideHPC@OLCFGOV
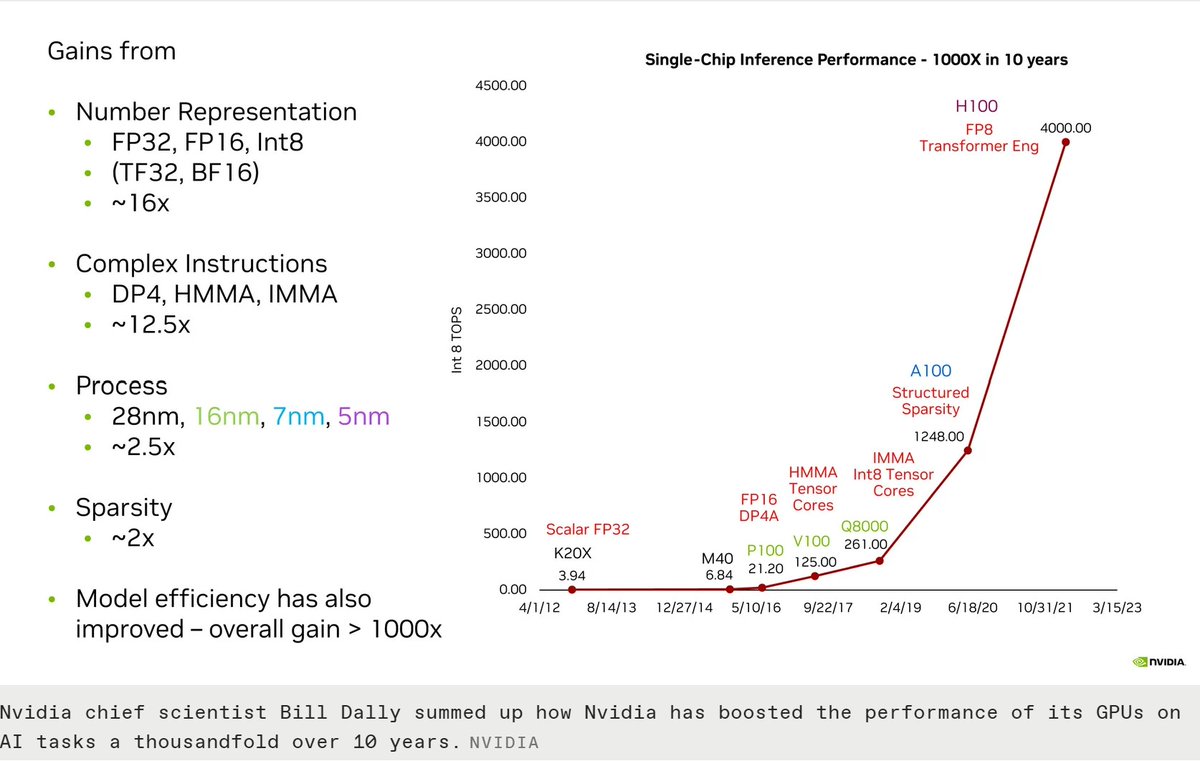
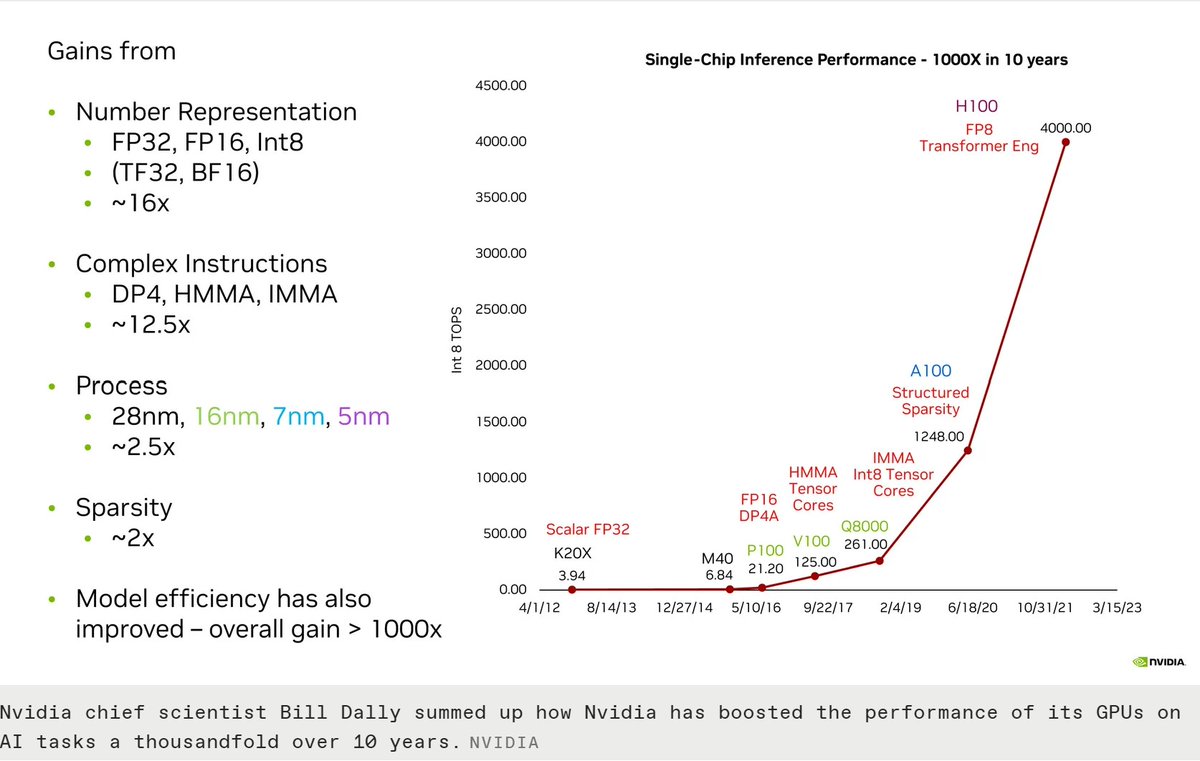
Nvidia 1000x in 10 years:
o Better Number Representation: 16x
o Complex Instructions: 12.5x
o Moore’s Law: 2.5x
(Hint: 2.5 x over 10 years should tell us something!)
o Sparsity: 2x
o Model Efficiency
#HPC#AI#GPU#HotChips2023
How did @nvidia get here? Huang's Law
The company’s chief scientist, Bill Dally, managed to sum it all up in a single slide during his keynote address to the IEEE’s #HotChips2023
https://t.co/tvJN0IPR2c
#HPC#AI#GPU via @IEEESpectrum
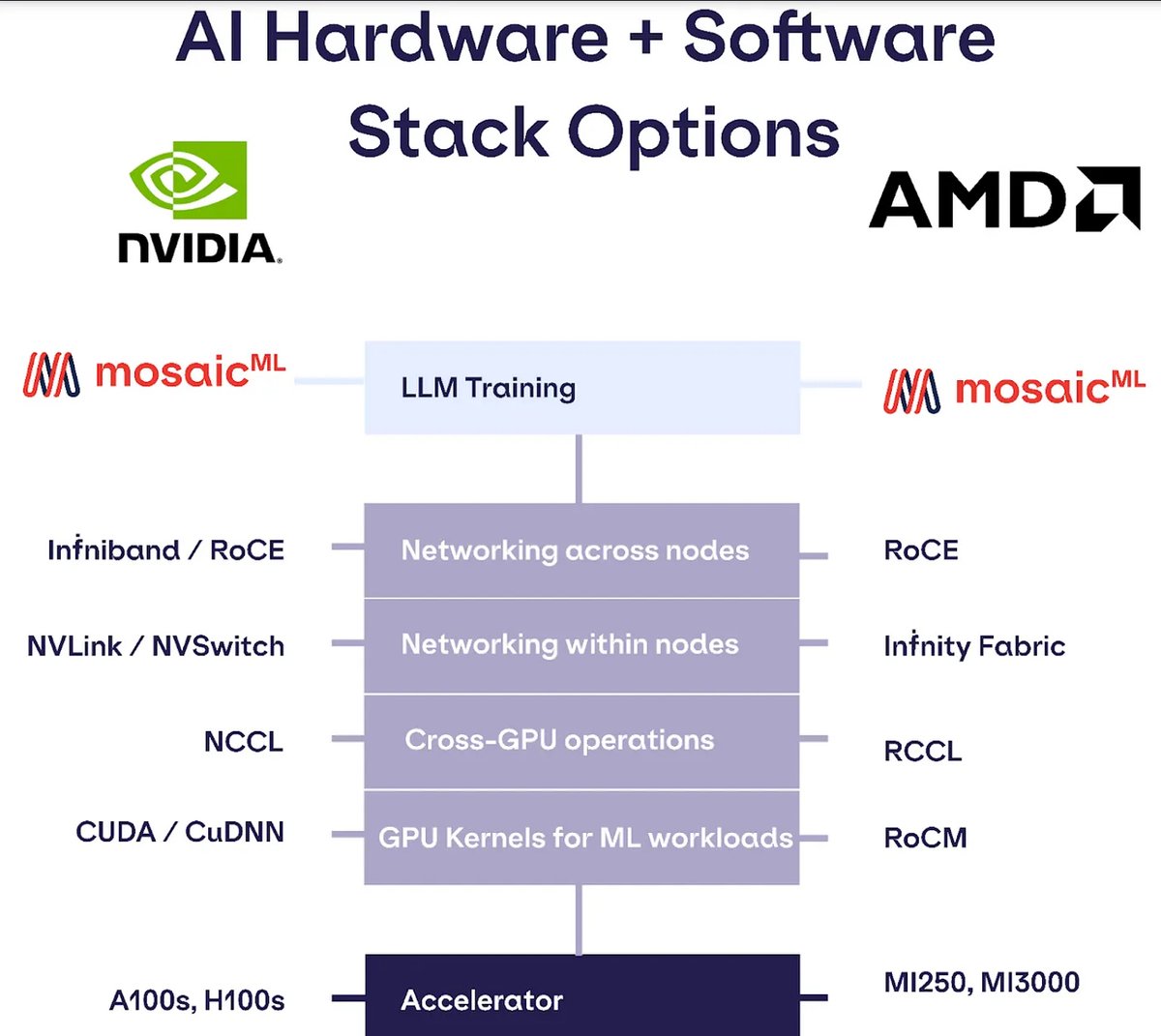
Matching Nvidia Performance With 0 Code Changes With MosaicML
With the latest @PyTorch 2.0, @MosaicML Composer, and Foundry releases, @AMD hardware is now just as easy to use as @Nvidia hardware
https://t.co/EdmrJSGwJo
#AI#GenerativeAI#HPC#GPU via @dylan522p
Introducing Open Omics Acceleration Framework: our lab's open sourced data science & AI framework for accelerating digital biology. Happy to share the first set of results of the framework in collaboration with AWS. #Genomics@wasim_galaxy@Saurabh_Kalikar@neonarendra5
Happy to share our preprint showing improvement of variant calling and expression analysis by fixing errors in GRCh38 reference. With @sedlazeck, Justin Zook @NIST @meganamsu Jonathan LeFaive, Peter Orchard
@MedhatHelmy7 @lfpaulin@dcsoto_cl@BCM_HGSC https://t.co/eyPAWlKgGw
We're excited to work together with @Advantech, @garaotus , and @IntelFPGA to deliver an ultra-fast and cost-effective genomics analysis platform to identify human genes associated with diseases. Download the white paper here! https://t.co/IMqaerd0Se
Microsoft and Intel are longstanding partners in data center optimization.
Learn how Microsoft deployed millions of Intel® FPGAs to improve efficiency and decrease latency to support disaggregation in cloud and telco markets.
Watch the video: https://t.co/rH8s30GI8y
Release of DeepVariant v1.4
Greatly simplified and sped up PacBio workflow by eliminating the need for intermediate phasing step.
Improved short-read WGS/WES accuracy (4-10% error reduction) by adding a channel for read insert size.
https://t.co/fXhSYNMlcj