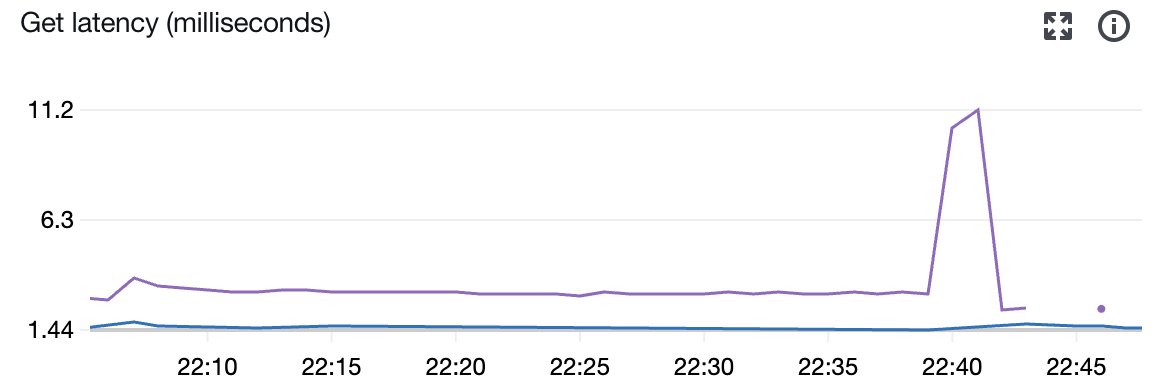
Love this. Intuiting how a complex distributed system handles these types of failures is not easy.
As we speak, I was reviewing an open PR in a large distributed system to adjust retries/timeouts in the face of overload. Excited to model out the problem in the tool.
Would love to see rate limiters, load shedding, and other common strategies in the tool to see how those affect things as well.
@MarcJBrooker What’s the latency overhead look like for this? Say us-east-1 and us-west-2? Going to try it out, but curious what you’re observing/targetting for consistent reads and writes.
Additionally, is the SLA still 5 9’s with this on?