Introducing Cambrian-S
it’s a position, a dataset, a benchmark, and a model
but above all, it represents our first steps toward exploring spatial supersensing in video. 🧶
Microsoft researchers are introducing AutoGen, a framework for simplifying the orchestration, optimization, and automation of workflows for large language model (LLM) applications—potentially transforming and extending what LLMs can do. Learn more: https://t.co/NmVMCkIDsr
This is huge: Llama-v2 is open source, with a license that authorizes commercial use!
This is going to change the landscape of the LLM market.
Llama-v2 is available on Microsoft Azure and will be available on AWS, Hugging Face and other providers
Pretrained and fine-tuned models are available with 7B, 13B and 70B parameters.
Llama-2 website: https://t.co/PKrrXgHdem
Llama-2 paper: https://t.co/aINNrXNhMb
A number of personalities from industry and academia have endorsed our open source approach: https://t.co/N7HwgW9Suh
Code Interpreter Beta (rolling out to ChatGPT Plus) is quite powerful. It's your personal data analyst: can read uploaded files, execute code, generate diagrams, statistical analysis, much more. I expect it will take the community some time to fully chart its potential.
To turn on:
In ChatGPT on bottom left click on name > Settings > Beta features > turn on Code Interpreter.
Fascinating research by Google reveals the power of Language Models (LLMs) like PaLM or GPT in tackling visual tasks using in-context learning. This novel method enables LLMs to perform image generation tasks without requiring any parameter updates. #palm#GPT4#LLMs
Verifying my account on nostr
My Public Key: "npub1fhqzqm2nwm39r2mtcdgumruzcmk55kp5djq74kuagf767csq4j5qeprvss"
Find others at https://t.co/jchuaykQuk @nostrdirectory#nostr
📢 Excited to release Gorilla🦍 Gorilla picks from 1000s of APIs to complete user tasks, surpassing even GPT-4! LLMs need to interact with the world through APIs, and Gorilla teaches LLMs APIs. Presenting Gorilla-Spotlight demo🤩
Webpage: https://t.co/QZrtMaYKfa
New Open-source LLMs! 🤯 The Falcon has landed! 🦅 TII just released two new open-source LLMs called Falcon, which comes into size 7B trained on 1.5T tokens and 40B trained on 1T Tokens. 🚀🔥
7B: https://t.co/smoThB7LSX
40B: https://t.co/DEqID5C7qw
Watching @karpathy presentation from today and taking twitter notes, come along for the ride:
If you're like only the practical tips, skip to #32
@karpathy starts with stages:
1 - Pre-training - months x thousands of GPUs
2, 3, 4 - Finetuning stages that take hours or days
1/
We just released Transformers' boldest feature: Transformers Agents.
This removes the barrier of entry to machine learning
Control 100,000+ HF models by talking to Transformers and Diffusers
Fully multimodal agent: text, images, video, audio, docs...🌎
https://t.co/OILVxIX44I
IMAGEBIND: One Embedding Space To Bind Them All.
Learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data.
An open source project by Meta-FAIR.
Paper: https://t.co/g07iDT5rVO
Demo: https://t.co/80OKqOyGEb
Code: https://t.co/J4jrRm3Kik
Blog post: https://t.co/Meh7QSQsRS
🚀Introducing LLaVA Lightning: Train a lite, multimodal GPT-4 with just $40 in 3 hours! With our newly introduced datasets and the efficient design of LLaVA, you can now turbocharge your language model with image reasoning capabilities, in an incredibly affordable way.🧵
📢 Introducing MPT: a new family of open-source commercially usable LLMs from @MosaicML. Trained on 1T tokens of text+code, MPT models match and - in many ways - surpass LLaMa-7B. This release includes 4 models: MPT-Base, Instruct, Chat, & StoryWriter (🧵)
https://t.co/Zg7PcrQvOi
Mojo🔥 combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models.
Also, it's up to 35000x faster than Python 🤯 and … deploys 🏎
The code example for Denoising Diffusion Probabilistic Models in Keras is live on the site! 🥳🥳
What's in the code example, and why should you go through it?
A thread 👇
https://t.co/fu3PDX4PBB
Very excited to share an introduction to reinforcement learning from human feedback!
In collaboration with @lvwerra and @lcastricato + @Dahoas1 from @carperai. We take you on the journey I went on this week, from 0 to PhD.
https://t.co/LYeCE1lmUG
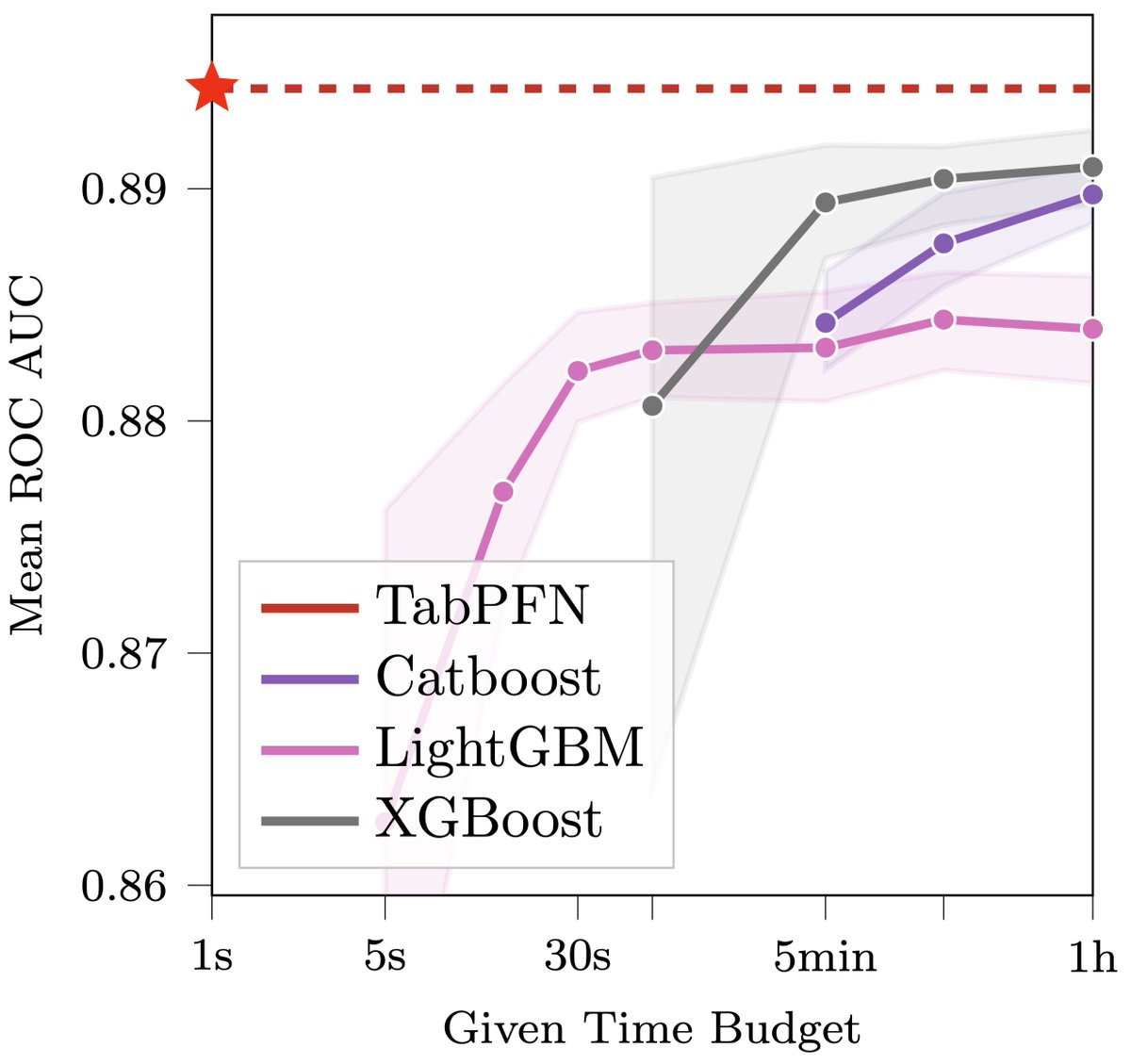
This may revolutionize data science: we introduce TabPFN, a new tabular data classification method that takes 1 second & yields SOTA performance (better than hyperparameter-optimized gradient boosting in 1h). Current limits: up to 1k data points, 100 features, 10 classes. 🧵1/6