I just gave a closed-book, pen-and-paper midterm exam in my 300-level course at UBC with 100 students. All exams were graded by an experienced graduate-level TA according to a rubric.
*** The average was 64/100.***
My class averages at UBC are usually 80-85.
Context:
• This was the first midterm, covering ONLY 4 weeks of material.
• Students had a list of possible questions in advance: no surprise questions.
• Questions included (a) 3 concept definitions, (b) 3 paragraph-long questions, and (c) a 1.5-page essay.
• I have taught this class multiple times. Nothing in my teaching style changed this semester.
• We read entire paragraphs of text in class, so students don't have to do something on their own that wasn't covered during the lecture.
• Students take a 10-question multiple-choice quiz at the end of every class (30% of the final grade).
• Attendance is 95-99% every class. Attention during lectures and participation in pair-work activities are very high → anticipating the end-of-class quiz.
*** But unfortunately, I suspect many students are not reading the material on the syllabus. They are asking LLMs to summarize it instead.***
After the midterm, students reported:
• They thought they knew concept definitions but couldn't produce them on paper.
• They thought they understood the arguments but struggled to connect them or identify points of agreement and disagreement.
My view:
It might be “cool” or “innovative” to teach students to summarize readings with ChatGPT or write essays with Claude. But we may be doing them a disservice: reducing their ability to retain material, think creatively, and reason from what they know. If you only read what AI has summarized for you, you don’t truly "know" the material.
Moving forward:
We have a second midterm coming up. I don't know how to convey to students that the best way to do better on the exam is to rely on and improve their own reading skills.
Tesla: Workers in Nueces County spotted a pipe from its new lithium refinery dumping what they described as “very dark” almost black water into a public drainage ditch near Robstown, Texas. The ditch flows toward Petronila Creek and eventually Baffin Bay, a coastal ecosystem.
Huge patchset from @TencentGlobal adding hand written assembly code for HEVC intra prediction
Up to ten times faster than C!
Companies which use FFmpeg should submit hand written assembly patches like Tencent
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
https://t.co/HmiRrQugnP
Now that everyone is an expert on curing pancreatic cancer in mice, not rats - I want to add some context that goes beyond the headline.
You will want to read this.
Cancer is cured in mice all the time.
Thousands of times. ~90% of those “cures” fail in humans.
Why?
Because mice are:
Genetically simpler.
Treated earlier.
Short-lived.
Not humans.
Mice are a filter - not a finish line.
Yes, this study matters. It comes from the Spanish National Cancer Research Centre.
Yes, it’s pancreatic cancer - one of the deadliest there is. Yes, full tumor regression is impressive.
But here’s what it actually means:
“This approach is now good enough to risk years, trials, and millions of euros on.”
Not:
“Cancer is solved.”
What happens next?
More animal work.
Toxicology.
Phase I (safety).
Phase II (maybe works).
Phase III (beats standard care?).
Maybe 8-10 years if everything goes right.
The real damage isn’t failed drugs.
It’s failed expectations.
Every “cured cancer in mice” headline trains the public to believe:
Cures are being hidden.
Progress should be fast.
Scientists are lying when reality hits.
That’s how trust erodes.
Bottom line:
This is how real cancer progress looks.
Messy. Slow. Risky. Incremental.
Not miracles.
Not conspiracies.
Just science - doing the hard work.
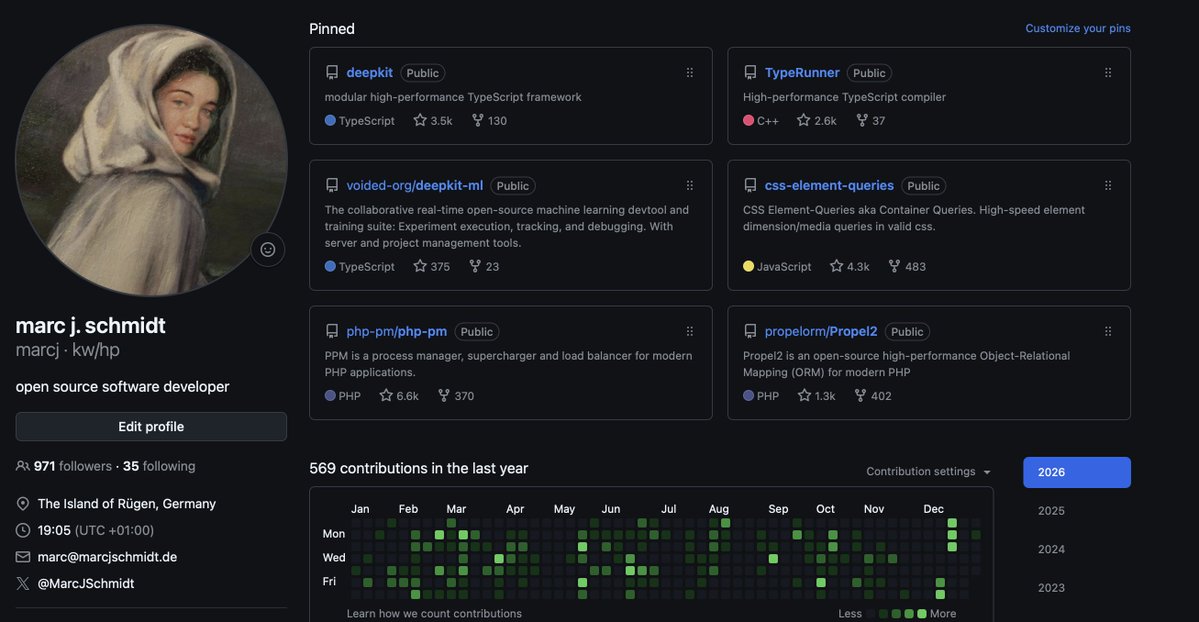
All my new code will be closed-source from now on. I've contributed millions of lines of carefully written OSS code over the past decade, spent thousands of hours helping other people. If you want to use my libraries (1M+ downloads/month) in the future, you have to pay.
I made good money funneling people through my OSS and being recognized as expert in several fields. This was entirely based on HUMANS knowing and seeing me by USING and INTERACTING with my code. No humans will ever read my docs again when coding agents do it in seconds. Nobody will even know it's me who built it.
Look at Tailwind: 75 million downloads/month, more popular than ever, revenue down 80%, docs traffic down 40%, 75% of engineering team laid off. Someone submitted a PR to add LLM-optimized docs and Wathan had to decline - optimizing for agents accelerates his business's death. He's being asked to build the infrastructure for his own obsolescence.
Two of the most common OSS business models:
- Open Core: Give away the library, sell premium once you reach critical mass (Tailwind UI, Prisma Accelerate, Supabase Cloud...)
- Expertise Moat: Be THE expert in your library - consulting gigs, speaking, higher salary
Tailwind just proved the first one is dying. Agents bypass the documentation funnel. They don't see your premium tier. Every project relying on docs-to-premium conversion will face the same pressure: Prisma, Drizzle, MikroORM, Strapi, and many more.
The core insight: OSS monetization was always about attention. Human eyeballs on your docs, brand, expertise. That attention has literally moved into attention layers. Your docs trained the models that now make visiting you unnecessary. Human attention paid. Artificial attention doesn't.
Some OSS will keep going - wealthy devs doing it for fun or education. That's not a system, that's charity. Most popular OSS runs on economic incentives. Destroy them, they stop playing.
Why go closed-source? When the monetization funnel is broken, you move payment to the only point that still exists: access. OSS gave away access hoping to monetize attention downstream. Agents broke downstream. Closed-source gates access directly.
The final irony: OSS trained the models now killing it. We built our own replacement.
My prediction: a new marketplace emerges, built for agents. Want your agent to use Tailwind? Prisma? Pay per access. Libraries become APIs with meters. The old model: free code -> human attention -> monetization. The new model: pay at the gate or your agent doesn't get in.