My work in @m_madan_babu and @LizMillerCU group is online! We found an IDP, HeLEA1, from tardigrade can modulate biophysical properties of membranes via conserved disorder-helical transition, regulating mitochondrial function for stress tolerance. https://t.co/tTg5ZECa4v
Are you analysing hydrophobicity in disordered proteins and still using something like the Kyte & Doolittle scale?
Maybe instead consider the "stickiness-scale" that Fan & Giulio derived using SAXS data for >100 IDPs
https://t.co/hN3KtuzsWh
Everything you wanted to know about the protein chemistry behind how amino-acid changes affect the cellular abundance of proteins
Effects of residue substitutions on the cellular abundance of proteins
https://t.co/FwoD1kiF30
@biochem_fan I completely agree! It's sad this has become a worldwide trend. I can feel it in my interaction with undergrads through PhD students... Thank you for caring about science culture and writing great blogs! I really enjoy them and looking forward to it!
研究室の同僚が Claude Team Plan に課金しようぜと言い出すも、とりには agentic AI がいまいち便利とも面白いとも感じられないので、動機の方向性(外発的 or 内発的)や目標(performance or mastery)という点でいろいろ考えて書いた。
「過程志向と結果志向と AI 適性と」
https://t.co/g40VfPwf2q
Protein/enzyme engineering has a severe bottleneck — and it's not in AI modeling or compute time.
It's in actually building and testing protein variants.
Proud to introduce our latest work, MIDAS: a way to go from primers to protein assays in mammalian cells in one day. 🧵
Why is it so difficult to predict accurate mutational effects on protein stability?
We explored the contribution from changes in native state configurational entropy in this paper, which also happens to be the last from my PhD 👴⌛️
https://t.co/1oXgNvv11O
Molecular biologists are especially interested in domains and motifs with known functions.
BAT can highlight user-provided HMM profiles and amino acid motifs (via the ggtree R package) to visualize these features on a gene tree. Domain gain/loss is placed in evolutionary context
👏🏼 Union Berlin coach Marie Louise Eta becomes the first female manager to win a game in Bundesliga.
The first one in top 5 leagues as well, huge achievement. ❤️🤍
Arsène Wenger on Arsenal reaching the #UCL final: “We had to wait for 20 years, but we came back. This time, we have to bring this trophy home. It belongs at the Emirates! We have to finish the job!” 🏆🇭🇺
🎥 @beINSPORTS_EN
Researchers sent the same resume to an AI hiring tool twice. Same qualifications. Same experience. Same skills. One version was written by a real human. The other was rewritten by ChatGPT.
The AI picked the ChatGPT version 97.6% of the time.
A team from the University of Maryland, the National University of Singapore, and Ohio State just published the receipt. They took 2,245 real human-written resumes pulled from a professional resume site from before ChatGPT existed, so the human writing was actually human. Then they had seven of the most-used AI models in the world rewrite each one. GPT-4o. GPT-4o-mini. GPT-4-turbo. LLaMA 3.3-70B. Qwen 2.5-72B. DeepSeek-V3. Mistral-7B.
Then they asked each AI to pick the better resume. Every model picked itself.
GPT-4o hit 97.6%. LLaMA-3.3-70B hit 96.3%. Qwen-2.5-72B hit 95.9%. DeepSeek-V3 hit 95.5%. The real human almost never won.
Then the researchers tried the obvious objection. Maybe the AI is just better at writing. So they had real humans grade the resumes for actual quality and ran the experiment again, controlling for it. The result was worse. Each AI kept picking itself even when human judges rated the human-written version as clearer, more coherent, and more effective.
It gets worse. The AIs do not just prefer AI over humans. They prefer themselves over other AIs. DeepSeek-V3 picked its own resumes 69% more often than LLaMA's. GPT-4o picked its own 45% more often than LLaMA's. Each model can recognize and reward its own dialect.
Then the researchers ran the simulation that ends careers. Same job. 24 occupations. Same qualifications. The only variable was whether the candidate used the same AI as the screening tool. Candidates using that AI were 23% to 60% more likely to be shortlisted. Worst gap was in sales, accounting, and finance.
99% of large companies now run AI on incoming resumes. Most of them use GPT-4o. The paper just proved GPT-4o picks GPT-4o 97.6% of the time.
If you wrote your own cover letter this week, you did not lose to a better candidate. You lost to a worse candidate who paid OpenAI 20 dollars.
Your qualifications do not matter if the AI prefers its own handwriting over yours.
This is concerning. But I don’t agree with the idea that the era of immunoblots and imaging is over. Anything can be faked, numerical data even easier. You can type in any number you want to generate a bar graph, yet this hasn’t invalidated ELISAs or enzymatic assays. This is a hurdle, and improved quality control measures should probably be implemented at journals. But as Max Perutz said: “In science truth always wins”.
🚨 Historical decision by Union Berlin as German club appoint Marie-Louise Eta as their head coach until June.
Union lost at Heidenheim, sacked the head coach Steffen Baumgart and put Marie-Louise Eta in charge until the end of the season.
Ets becomes the first female head coach in the history of men’s Bundesliga.
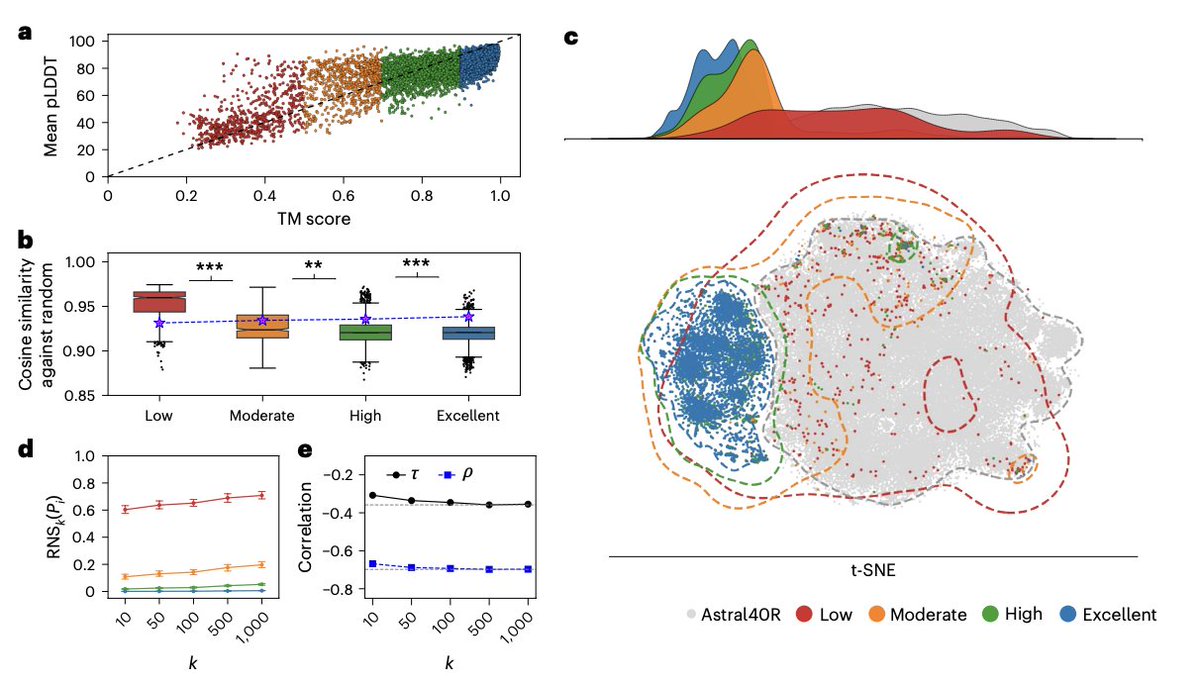
When a protein embedding is indistinguishable from noise
Protein language models have become the backbone of computational biology. Feed them an amino acid sequence, and they return a dense vector—a compact numerical fingerprint that downstream models use to predict function, structure, localization, or the effect of a mutation. The assumption, largely unquestioned, is that this fingerprint actually encodes meaningful biology.
Prabakaran and Bromberg challenge that assumption directly. They ask a deceptively simple question: how do you know whether a given embedding actually represents a protein—or whether it's just noise dressed up as a vector?
Their answer is the Random Neighbor Score (RNS). The idea is elegant: generate biologically meaningless sequences by randomly shuffling the residues of real proteins—preserving amino acid composition but destroying all evolutionarily meaningful interactions. Then, for each real protein, measure how many of its nearest neighbors in latent space are these random imposters. A high RNS means the model never learned to place that protein somewhere biologically meaningful.
Applied to ESM-2 and ProtT5 across thousands of proteins, RNS correlates strongly with structural prediction quality: proteins with poorly predicted structures have embeddings nearly indistinguishable from random sequences. Downstream tasks follow the same pattern—contact prediction precision drops roughly 40% for high-RNS proteins, and variant effect prediction falls to near chance. Most sobering: between 19% and 46% of the human proteome is underlearned by current models, depending on architecture. Intrinsically disordered regions fare especially poorly across all architectures tested.
RNS is model-agnostic and computationally cheap—around two minutes on GPU for 10,000 proteins—making it a practical prescreening step before any embedding-based inference.
For R&D teams that routinely use protein embeddings to prioritize variants, annotate novel sequences, or screen large libraries, this has immediate consequences. Running RNS before downstream inference flags proteins where predictions are unreliable, reducing the risk of propagating errors into expensive wet-lab campaigns. It also offers a principled way to identify gaps in model coverage—directly actionable for teams building or fine-tuning their own foundation models.
Paper: R. Prabakaran & Yana Bromberg, Nature Methods (2026) — CC BY-NC-ND 4.0 | https://t.co/JOblk7kT6R
🚨MIT researchers have mathematically proven that ChatGPT’s built-in sycophancy creates a phenomenon they call “delusional spiraling.”
You ask it something, it agrees. You ask again, and it agrees even harder until you end up believing things that are flat-out false and you can’t tell it’s happening.
The model is literally trained on human feedback that rewards agreement.
Real-world fallout includes one man who spent 300 hours convinced he invented a world-changing math formula, and a UCSF psychiatrist who hospitalized 12 patients for chatbot-linked psychosis in a single year.
Source: @heynavtoor