Innovation with genAI, predicting insulin resistance from wearable device data (for steps, heart rate, sleep) integrated with demographics and routine blood parameters. Without CGM. @aametwally1@GoogleResearch@NatureMedicine
https://t.co/PRZPLGjuxZ
A common heuristic in LLM agent design—"more agents is better"—might be wrong.
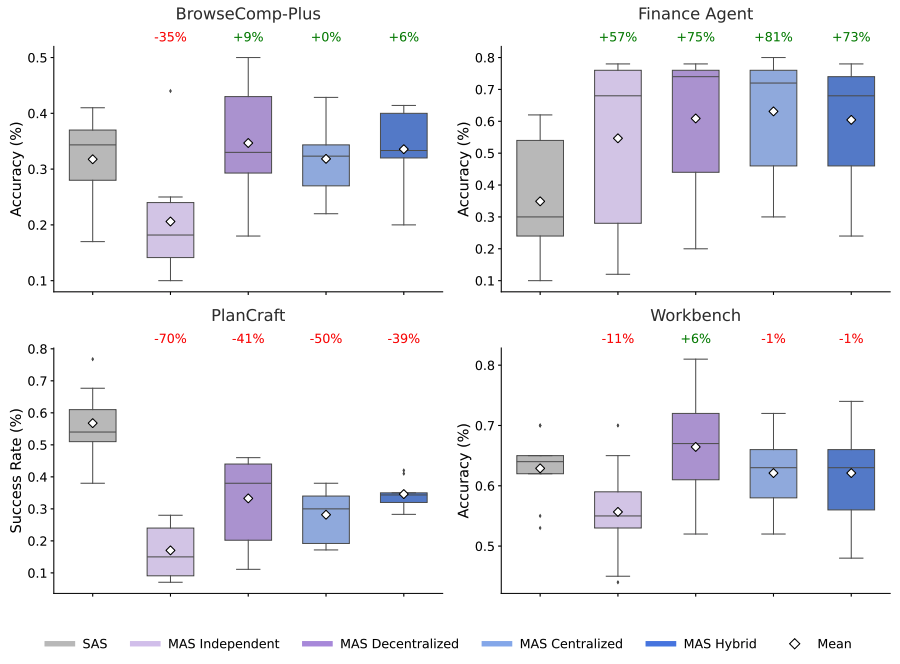
Across 180 configurations, we find multi-agent coordination is task-contingent: +81% on parallelizable tasks (finance), but -70% on sequential ones (planning). Architecture-task alignment matters more than agent count.
The AI industry hype says "more agents is all you need," but new data shows that strictly sequential tasks and tool-heavy integrations fail at scale.
https://t.co/vLVUcMr2aU
The AI industry hype says "more agents is all you need," but new data shows that strictly sequential tasks and tool-heavy integrations fail at scale.
https://t.co/vLVUcMr2aU
Major new research from Google and MIT.
"More agents is all you need" has become a mantra for AI developers. We know multi-agent systems can be effective, but we do this mostly based on heuristics.
The default approach to building complex AI systems today remains adding more agents, more coordination, more communication.
It would be helpful to have a more principled way to scale agentic systems.
This new research introduces the first quantitative scaling principles for agent systems, testing 180 configurations across three LLM families (OpenAI, Google, Anthropic) and four agentic benchmarks spanning financial reasoning, web navigation, game planning, and workflow execution.
The findings:
Multi-agent systems show an overall mean MAS improvement of -3.5% across all benchmarks, with massive variance ranging from +81% improvement to -70% degradation depending on task structure and architecture.
Three dominant effects emerge from the data:
The tool-coordination trade-off: tool-heavy tasks suffer disproportionately from multi-agent overhead. The efficiency penalty compounds as environmental complexity increases.
A task with 16 tools makes even the most efficient multi-agent architecture paradoxically less effective than a single agent.
The capability ceiling: once single-agent baselines exceed approximately 45% accuracy, coordination yields diminishing or negative returns. This is quantified as a statistically significant effect. Additional agents simply cannot overcome the coordination tax when baseline performance is already reasonable.
Architecture-dependent error amplification: independent multi-agent systems amplify errors 17.2x through unchecked propagation. Centralized coordination contains this to 4.4x via validation bottlenecks (these catch errors before propagation).
The presence or absence of inter-agent verification determines whether collaboration corrects or catastrophically compounds mistakes.
The performance heterogeneity is also interesting to look at:
- On parallelizable financial reasoning tasks, centralized multi-agent coordination achieves +80.9% improvement.
- On sequential planning tasks requiring constraint satisfaction, every multi-agent variant tested degraded performance by 39-70%.
- Decentralized coordination excels on dynamic web navigation (+9.2%) but provides essentially no benefit elsewhere.
The researchers derive a predictive model achieving cross-validated
𝑅^2=0.513 that correctly predicts the optimal architecture for 87% of held-out configurations. This model contains no dataset-specific parameters, enabling generalization to unseen task domains.
Overall, architecture-task alignment, not the number of agents, determines collaborative success. The research replaces heuristic guidance with quantitative principles: measure task decomposability, tool complexity, and baseline difficulty, then select a coordination structure accordingly.
Paper: https://t.co/6QY8rT15Pd
Learn to build effective AI agents in my academy: https://t.co/JBU5beIoD0
Major new research from Google and MIT.
"More agents is all you need" has become a mantra for AI developers. We know multi-agent systems can be effective, but we do this mostly based on heuristics.
The default approach to building complex AI systems today remains adding more agents, more coordination, more communication.
It would be helpful to have a more principled way to scale agentic systems.
This new research introduces the first quantitative scaling principles for agent systems, testing 180 configurations across three LLM families (OpenAI, Google, Anthropic) and four agentic benchmarks spanning financial reasoning, web navigation, game planning, and workflow execution.
The findings:
Multi-agent systems show an overall mean MAS improvement of -3.5% across all benchmarks, with massive variance ranging from +81% improvement to -70% degradation depending on task structure and architecture.
Three dominant effects emerge from the data:
The tool-coordination trade-off: tool-heavy tasks suffer disproportionately from multi-agent overhead. The efficiency penalty compounds as environmental complexity increases.
A task with 16 tools makes even the most efficient multi-agent architecture paradoxically less effective than a single agent.
The capability ceiling: once single-agent baselines exceed approximately 45% accuracy, coordination yields diminishing or negative returns. This is quantified as a statistically significant effect. Additional agents simply cannot overcome the coordination tax when baseline performance is already reasonable.
Architecture-dependent error amplification: independent multi-agent systems amplify errors 17.2x through unchecked propagation. Centralized coordination contains this to 4.4x via validation bottlenecks (these catch errors before propagation).
The presence or absence of inter-agent verification determines whether collaboration corrects or catastrophically compounds mistakes.
The performance heterogeneity is also interesting to look at:
- On parallelizable financial reasoning tasks, centralized multi-agent coordination achieves +80.9% improvement.
- On sequential planning tasks requiring constraint satisfaction, every multi-agent variant tested degraded performance by 39-70%.
- Decentralized coordination excels on dynamic web navigation (+9.2%) but provides essentially no benefit elsewhere.
The researchers derive a predictive model achieving cross-validated
𝑅^2=0.513 that correctly predicts the optimal architecture for 87% of held-out configurations. This model contains no dataset-specific parameters, enabling generalization to unseen task domains.
Overall, architecture-task alignment, not the number of agents, determines collaborative success. The research replaces heuristic guidance with quantitative principles: measure task decomposability, tool complexity, and baseline difficulty, then select a coordination structure accordingly.
Paper: https://t.co/6QY8rT15Pd
Learn to build effective AI agents in my academy: https://t.co/JBU5beIoD0
Our work is a start toward better analysis and benchmarking of LLMs on real-world health information-seeking conversational dynamics, not just static Q&A or synthetic, simulated conversational datasets.
This was an exciting collaboration with @MonicaNAgrawal at @DukeU alongside the rest of the Duke team consisting of Maryam Aziz, Rohit Vartak, Ayman Ali, and Best Uchehara, as well as @xliucs and Ishan Chatterjee at @UW.
👉 Check out the full paper for more details!
📜 Paper: https://t.co/iO7MDuD1Ul
💾 Dataset: https://t.co/tknqha0YGx
🧑🏿💻 Code: https://t.co/QZPnBMp1JX
True intelligence = reasoning about new information, not memorized facts.
How can we scalably create benchmarks that are completely novel yet have known answers?
Meet SynthWorlds, an eval & data-gen framework to disentangle reasoning and knowledge⬇️🧵
📄https://t.co/ITwP4YdtDG
✨ I’m thrilled to share our latest research on building personal health agents at Google! I believe it will pave the way for the future of AI-driven personal health. Please check it out! 🚀
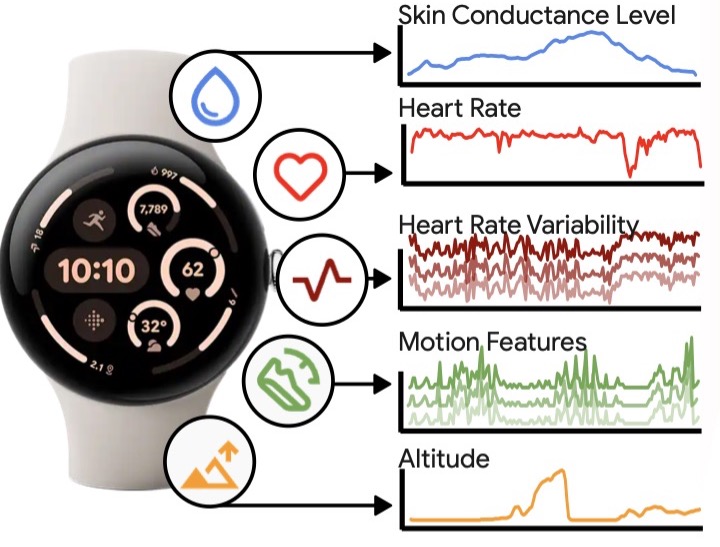
Learn about our research prototype LLM-powered personal health agent that analyzes various data modalities, including data from wearable devices, to offer evidence-based health insights and to provide a personalized coaching experience.
Read more →https://t.co/WcHpasRidz
New paper in Nature Medicine introduces PH-LLM, a Gemini-based model for personalized health. It integrates wearable device data to provide insights and coaching for sleep and fitness. The model exceeded human expert scores on professional exams and performed on par with experts on real-world case studies.
https://t.co/GYfYcD6RQ4
Let your wearable data "speak" for itself! Introducing SensorLM, a family of sensor-language foundation models trained on ~60 million hours of data, enabling robust wearable data understanding with natural language. → https://t.co/1vL6df5pMa
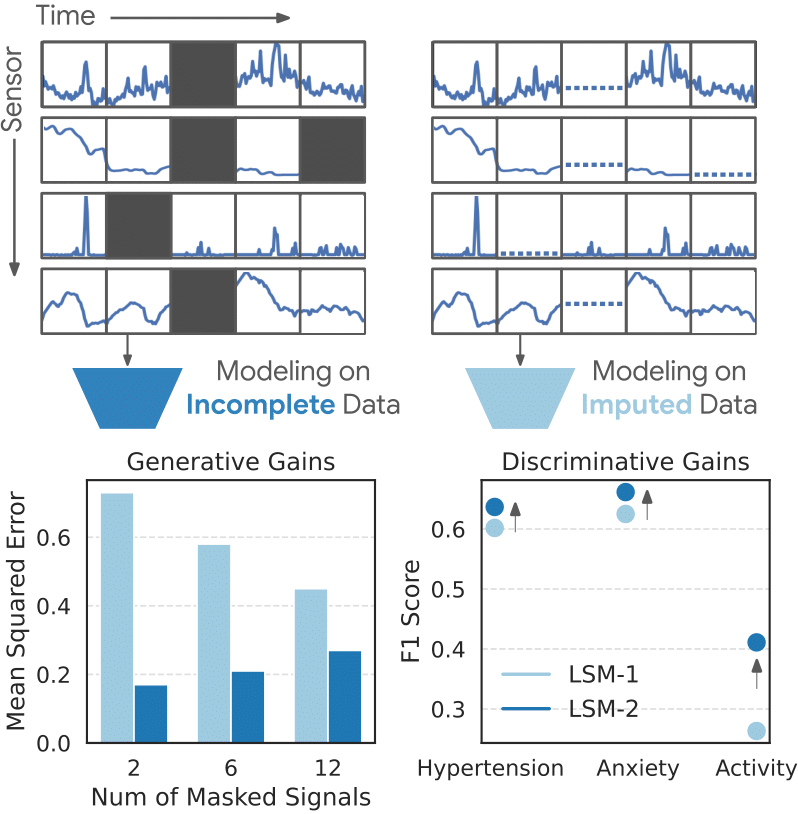
Introducing LSM-2, our newest foundation model for wearable sensor data. LSM-2 uses Adaptive & Inherited Masking, a novel self-supervised framework, to learn from incomplete data & achieve strong performance without requiring explicit imputation. More → https://t.co/jeMvzVupZg
🚨 Let your wearable data "speak" for themselves! ⌚️🗣️
Introducing *SensorLM*, a family of sensor-language foundation models, trained on ~60 million hours of data from >103K people, enabling robust wearable sensor data understanding with natural language. 🧵
🚨Are LLMs truly ready for autonomous data science?
Real-world data is messy—missing values, outliers, inconsistencies—and if not handled properly, can lead to wrong conclusions.
🌟We introduce RADAR, a benchmark evaluating whether LLMs can handle imperfect tabular data. 🧵
Congratulations to @UW#UWAllen Ph.D. grads @sharma_ashish_2 & @sewon__min, @TheOfficialACM Doctoral Dissertation Award honorees! Sharma won for #AI tools for mental health; Min received honorable mention for efficient, flexible language models. #ThisIsUW https://t.co/R2b1r3wxUP
🎉 𝐄𝐱𝐜𝐢𝐭𝐞𝐝 𝐭𝐨 𝐬𝐡𝐚𝐫𝐞 𝐭𝐡𝐚𝐭 𝐨𝐮𝐫 𝐧𝐞𝐰 𝐩𝐚𝐩𝐞𝐫, "𝐏𝐥𝐚𝐧𝐆𝐄𝐍", 𝐢𝐬 𝐧𝐨𝐰 𝐨𝐮𝐭! 🎉
💡PlanGEN is a model-agnostic, and easily scalable multi-agent framework utilizing inference-time algorithms designed to generate natural planning and reasoning trajectories to solve complex tasks.
📊PlanGEN shows improvement on challenging benchmarks including NATURAL PLAN, OlympiadBench, DocFinQA, and GPQA.
Please check out our full paper @ https://t.co/s75BOkUVGw
#NLProc #LLMs #Planning #Reasoning #Agents #AI
(1/5)
Is BIG-Bench Hard too easy for your LLM?
We just unleashed BIG-Bench EXTRA Hard (BBEH)! 😈
Every task, harder! Every model, humbled! (Poem Credit: Gemini 2.0 Flash)
Massive headroom for progress across various areas in general reasoning 🤯
Is BIG-Bench Hard too easy for your LLM?
We just unleashed BIG-Bench EXTRA Hard (BBEH)! 😈
Every task, harder! Every model, humbled! (Poem Credit: Gemini 2.0 Flash)
Massive headroom for progress across various areas in general reasoning 🤯
This is one of the most exciting projects I’ve been involved in during my career—building foundation models for wearable data and showing the scaling law of wearable data! Check out our blog and the paper! ⌚
Today on the blog, we investigate whether the principles driving the scaling of neural networks in domains like text and image data also extend to large-scale, multimodal wearable sensor data. Read more about scaling wearable foundation models →https://t.co/zD3Tx7RJAg
(reshare) I'm recruiting PhD students @uwcse@uwnlp
(https://t.co/I5wQsFnCLL). Focus areas incl Human-AI collaboration, language agents, LLM safety & applications to mental health, social sciences, education. Apply here: https://t.co/ku40wCrpYh
@uwdatascience@UW_iSchool@uwdub