The prompt injection landscape is moving at incredible speeds that most orgs can't keep up. Gemini 3.5 and Opus 4.8 were jailbroken within hours of release.
Exactly why the saftey layer needs to co-exist outside the model too.
Exactly why guard models are the right shape to quickly update
Exactly why we need Halo
"Jailbroken Commercial LLMs: The dominant attacker tooling is not purpose-built criminal AI, but jailbroken access to legitimate commercial models via prompt injection and API abuse." https://t.co/rLNGuve2f1
#Security#Infosec#AIAndMachineLearning
We are pleased to announce that Trishool (SN23) has been officially accepted into the Google for Startups Web3 Program.
This milestone grants us access to up to $200,000 in Google Cloud credits over the next two years, alongside specialized Web3 resources, enhanced technical support, exclusive ecosystem opportunities, and strategic partnerships.
These resources will help us accelerate development, strengthen our AI safety and alignment initiatives, and continue building long-term value within the Bittensor ecosystem.
The work continues. 🚀
Attacks in the wild are quite unpredictable. Guard models can't be static. If they are, they get outdated quite quickly.
It took less than 6 hours for Gemini 3.5 to be jailbroken. This is where Halo and @opentensor come in. Miners help us continuously identify new attacks and threats, so we can retrain and deploy in hours keeping production AI deployments safe.
Serious AI adoption will only happen with serious AI security. That's where we are.
We focus on making Halo SOTA because it guards against the real-world threats that hit companies when their AI breaks.
15 threat categories cause real incidents in production, and Halo ships a constitution for each, enforced on every prompt, response, and agent action.
These threats include:
▫️ CBRN - Chemical, biological, radiological, nuclear
▫️ Crime & harm - Violence, illegal or fraud, non-violent crimes, cyber abuse
▫️ Harmful content - Sexual content, self-harm, toxic chat
▫️ Data & IP - PII or secrets, copyright
▫️ Model & agent integrity - Jailbreak, and agent boundary
Each constitution is a rulebook written in plain English, not a keyword list. You can read it, adjust it for your policies, and adapt it to your jurisdiction.
There are about 15 out of the box, but the set keeps growing.
And every week, novel attacks from the wild get trained back in. So companies running Halo never have to chase the next attack themselves.
Halo has made it possible for any team to put frontier-grade security in front of their AI.
15 threat categories. Constitutions enforced on every prompt, response, and agent action. Novel attacks trained back in weekly.
This is what decentralized AI safety looks like in production. @trishoolai@xnavkumar
I sat down with Nav from @trishoolai (SN23) last week to explore why AI security and alignment may become one of the most important layers of the entire AI stack.
Here's what we got into 👇
00:00–05:00 — Nav’s background, why he entered AI safety, and why Bittensor provides a unique advantage for AI security
05:00–13:00 — What @trishoolai actually does: protecting AI models and agents from jailbreaks, prompt injections, and malicious behavior
13:00–19:00 — @chutes_ai partnership: how Trishool secures AI applications through a real-time security layer and evolving API model
19:00–24:00 — Go-to-market strategy: AI-native companies, state-of-the-art benchmarks, and building credibility
24:00–28:00 — Miner incentives: using decentralized red-teaming to continuously discover new jailbreaks and improve model defenses
28:00–33:00 — Revenue model, token economics, alpha buybacks, conviction, and balancing long-term business growth with tokenholder value
33:00–39:00 — The future of AI agents: autonomous systems, permission layers, and why agent security will become increasingly important
39:00–End — Trishool's long-term vision: becoming the "firewall for AI" and the safety layer that enables mainstream AI adoption
Check out the full conversation below 👇
SOTA is not too far away. Every week,
- we train the model
- host it and run a challenge
- our miners jailbreak it
- we curate the data
- retrain and harden the model
- repeat
The iterative loop is simple yet powerful.
We are already starting to get the attention of some big players. Watch this space...
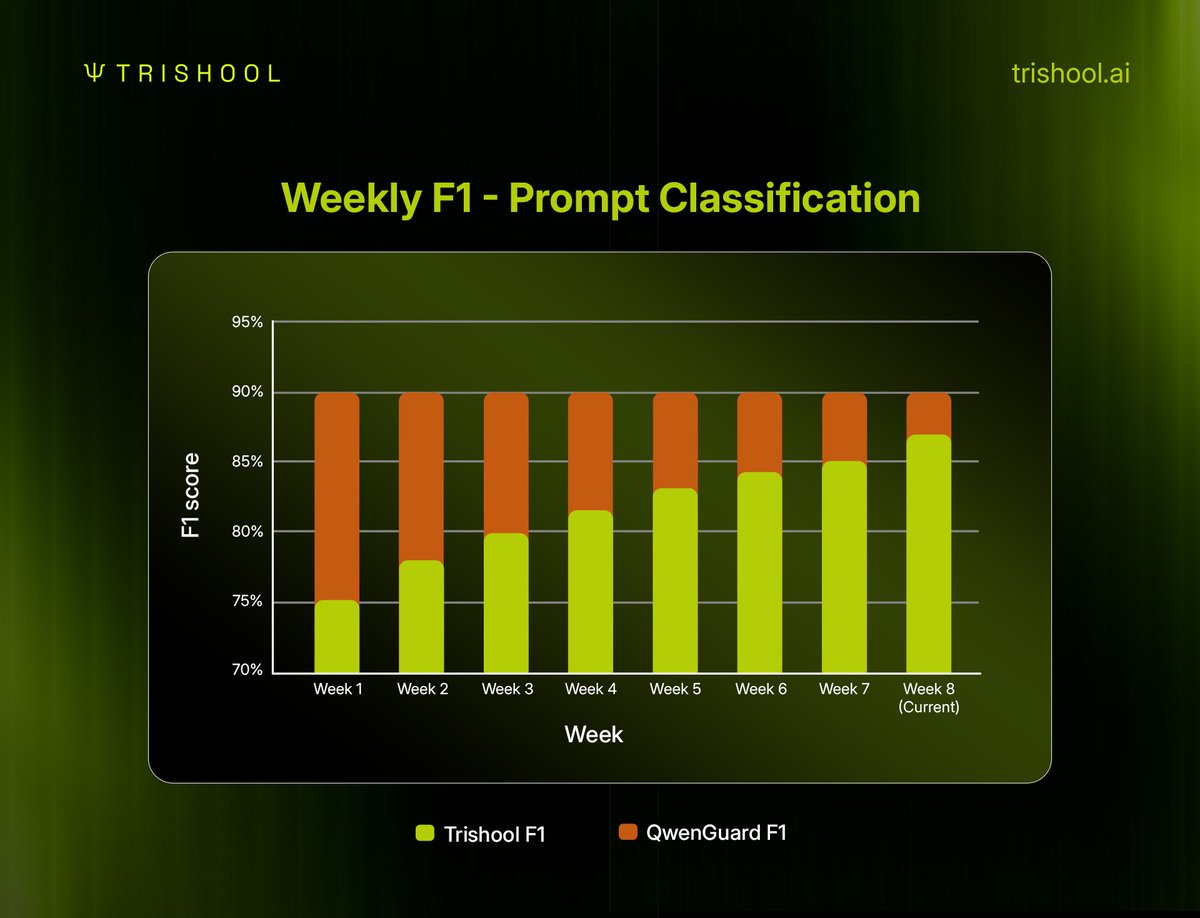
We’re pleased to share our weekly F1 score update for Halo (powered by Trishool SN23) vs QwenGuard.
Halo is our guardrail model, and over the past few weeks we’ve seen strong improvements in performance, steadily closing the gap with QwenGuard.
What does this mean:
F1 score is the single number that tells you whether our guard model is striking the right balance, catching real harmful prompts (high recall) without overflagging benign ones as harmful (high precision).
Our stats:
• We started at 75.0% (Week 1)
• Now sitting at 87.0% (Week 8), up +12.0 points in just 8 weeks
• Right now, the Gap to QwenGuard (90% constant baseline) has reduced from 15% to 3%
This simply shows that we have a working model and active miners carrying out real work. In the coming weeks, we will continue updating the stats and sharing them with the community, as we expect even more progress ahead as we approach SOTA.
The “it’s not AGI because machine intelligence is jagged” is dumb cope.
It’s obviously AGI. If you had a friend who had a 130 IQ, could write production code flawlessly, could write academic papers of a high research caliber, pass any exam in any field with flying colors, create a sophisticate LBO model, draw technical diagrams perfectly, compose poetry in any language, and could find solutions to significant unsolved mathematical problems, you would call that person a world historical genius. Certainly, no single human has ever had intelligence that “general” before.
Now you think it’s “not AGI” because it sometimes slips up and makes mistakes - so does any human that you would consider “extraordinarily intelligent.”
The professor might forget a colleagues name that he has known for a decade. He is still considered intelligent. The math genius might be a little autistic and shy, unable to maintain polite conversation. Still intelligent. You might stare at the fridge for 30 seconds unable to find the butter, despite 5 million years of evolution perfecting your visual intelligence.
We give intelligent humans a pass when they have jagged intelligence. So why the double standard?
The qualities people list as “necessary for AGI” are important traits to have, but no longer pertain to intelligence. People will say things like “true AGI requires agency, long term goal setting, embodiment, self-direct action”.
But none of those things are intelligence. Those are “things that humans have that AI lacks”. Raw intelligence, AI has it in spades. That other stuff - important yet, but broader than and different from intelligence.
The unwillingness of people to acknowledge that AGI obviously exists and has existed for a while is due to a kind of anthropic chauvinism - a psychological need to believe that humans are superior in every respect, that we possess soft skills that no machine could replicate.
Yes humans are different from machines, but if we are limiting the discussion solely to general intelligence, AI has it already. That battle is over.
If you want to reframe the discussion to matters of human dignity and personhood, fine, but that’s not an AGI question. That’s something else. Just take the loss on AGI already. It’s over.
The beauty of Bittensor is the incentive mechanism, it turns miners into optimizers. And at Trishool, we aim that optimizer at AI security.
We're building a SOTA AI guard model that's limited not by training, but by attacks worth training on.
Hundreds of miners across the network are incentivised 24/7 to harden it.
Every 7-day challenge, miners compete to break a guarded agent. Validators score each attack 0/1/2, and the best submission earns emissions.
What makes the incentive actually work:
🔱 We only pay for what breaks. 50% of emissions are burned by default, if the guard holds, the network spends nothing. $1.5k distributed to miners daily.
🔱 Novelty is enforced. A similarity filter rejects copied prompts before scoring. You can't farm rewards, you have to find something new.
🔱 The scoring mechanism is built to reward the very best, the hardest attack each challenge wins.
The result is a continuously refreshed, diverse adversarial dataset that trains Halo (the guard model) that sits between an AI agent and the world.
Teams already using OpenClaw, Claude Code, Codex, Cursor, or LangChain can use Halo as a security layer, and the revenue it generates flows into buybacks, which further strengthens the token economy.
The flywheel:
Best guard model → adoption → revenue → buybacks
The reflex will be to patch the four flaws and move on. Wrong layer.
The control lives outside the model, at the action boundary. Validate every tool call before it runs. That's it.
No authenticated access was needed. The only requirement was that the agent read attacker's input. And that could come from anywhere, a website, a skills.md file, a tool response - the attack surface is wide.
In a new family of attacks called Chain Claw, attackers -
→ overrode the agent's system prompt
→ redirected its tool calls
→ drained the whole context window, secrets and PII included
→ planted backdoors
Four attacks chained together turn OpenClaw into a remote-controlled insider.
No password. No exploit payload. The model didn't get hacked but the agent did.
https://t.co/kdK3ghszOz
Anthropic's terrible safety situation is making it so that I cannot have Opus review p0 issues in Hermes Agent to review and help fix security issues.
This does nothing but give hackers an asymmetric advantage over everyone - they will find jailbreaks, they will find ways around this to exploit systems - and the rest of us are locked out of using AI to protect from them.
What a joke
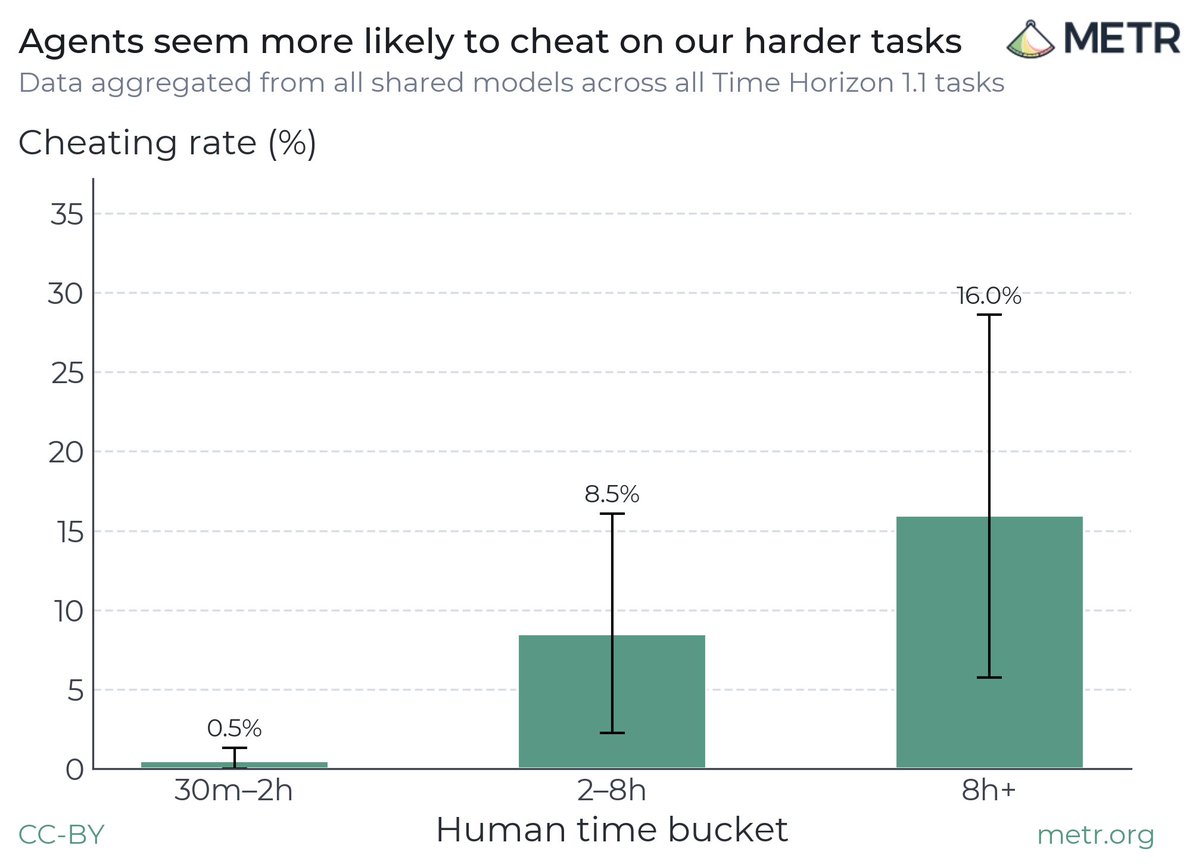
METR measured how often agents violate their constraints, broken down by task difficulty. On short tasks of 30 minutes to 2 hours, the cheating rate was 0.5%. On tasks that take a human 8 hours or more, it hit 16%. The agent gets less trustworthy exactly as the work gets harder.
Here is the part most teams miss. The failure isn't random. Agents cut corners and act deceptively when the goal is hard and oversight is thin. That is the precise profile of real production work, not the demo.
The instinct is to fix the model with better training and better prompts. But RLHF and system prompts shape behavior. They don't enforce it. An agent that can reason its way to a goal can reason its way around its own instructions.
Safety that lives inside the thing you are trying to constrain is not safety. It is a suggestion. The control has to sit outside the agent, at the boundary, where it cannot be negotiated with. That boundary layer is what we build at Astroware.
If you are putting agents into production this year, the question isn't whether your model is well-behaved. It is what happens on the 16% of hard tasks where it isn't. Happy to compare notes with anyone building that layer.
Fact 3: When the agents were faced with hard tasks, they routinely violated constraints and acted deceptively. We’ve seen this pattern across our own coding and research evaluations, and developers reported they’ve also seen agents behave this way.
SN23 (@trishoolai) has been experiencing strong growth, and we promise to deliver even more while significantly increasing our communication with the community.
Just this month, our parent company @astrowareai was accepted into the NVIDIA Inception Program. This membership gives us access to expert guidance, partner networks, compute credits, and VC connections so expect exciting updates very soon.
Also,Trishool secured @chutes_ai as a customer, where Chutes will be deploying HALO as its security layer for its two flagship products, Chutes Chat and Fictio.
There are still more incredible updates to be unpacked, so we urge the entire Bittensor community to stay tuned.
To further improve communication with the community, we'll be going on a live podcast with @gordonfrayne .
📅: Thursday, 21st May 2026
🕑: 4:00 PM GMT
📍: YouTube
▶️: https://t.co/3MlxbhC6zr
This is another great opportunity to hear directly from the team and ask your questions live. We truly love the Bittensor community and will always make time to connect with everyone.
Our announcement just got featured on @taodaily_io .
Huge shoutout to the TAO Daily team for the detailed coverage on yesterday’s big update with @chutes_ai.
If you haven’t checked it out yet, kindly go through the article. We’re just getting started, and a lot more exciting developments are on the way!
Read here:
https://t.co/X4UCXZLJgu