Palantir were kind enough to sum up its hideous ideology in 22 points. And I have taken the liberty of annotating each one of them. Here is my interpretation of all 22 of them (preserving the original numbering - for the original see their tweet below):
1. Silicon Valley owes an immeasurable debt to the ruling class who bailed out the criminal bankers that wrecked the livelihood of the majority of Americans. The engineering elite of Silicon Valley will defend that ruling class to the death (literally!), in the name of the majority of Americans whom they treat with contempt – i.e., like cattle that have lost their market value.
2. Palantir is eyeing the Apple Store, salivating over the prospect of creating its own technofeudal estate. Time to replace the iPhone with another device that dissolves what is left of people’s privacy.
3. Palantir shall give nothing away for free. It cares uniquely over its own growth which it pursues by sowing fear so that it can sell a fake sense of security.
4. Glory to brute force! Ethics is for suckers. The West needs more of Palantir’s murderous software.
5. AI-powered killer robots are coming. The task is to profit magnificently by building killer robots first and ask questions later. To be able to do so, Palantir will do whatever it takes to avoid at all cost any international treaties that limit AI-driven killer robots.
6. Every poor sod (lacking the connections to avoid being thrown into the trenches with killer drones targeting them from the sky) must be drafted into the army. Forget paying soldiers a salary. All payments should be directed to Palantir, where our own people will be serving their ‘national service’ – leaving the dying to non-shareholders.
7. Palantir works overtime to equip US Marines with killer bots that take away from the US Marines whatever remnants of ethical judgment they are left with on the battlefield. American society should be rendered perfectly incapable of any debate that restricts Palantir’s capacity to get the US Military to eliminate any remaining opportunity to reject its software’s choice of targets.
8. Palantir deplores the fact that the public sector is still not totally devoid of a conscience. Public servants must be fired en masse, except some very few approved by Palantir who will receive huge salaries, paid by taxpayers.
9. Palantir thinks that Donald Trump must be beatified for throwing himself into public service. Not forgiving folks like Trump everything risks our soul, not to mention that it raises the prospect of officials that restrict Palantir’s evil project.
10. Politics needs to be AI-like, devoid of anything that can be mistaken for human empathy. Those who look to the political arena to nourish their soul and sense of self must be sent to the gulag forthwith!
11. There are some people too eager to hasten Palantir’s demise. They should rethink, or else!
12. Palantir makes no nuclear weapons but is happily developing other weapons of mass destruction. We proudly announce that we are now ready to add to nuclear Armageddon the AI-driven threat to humanity’s existence.
13. No other country in the history of the world has committed so many war crimes in the name of progress and freedom. The United States offers infinite freedom to people like Palantir’s founders to profit so handsomely by inflicting so much damage upon humanity.
14. American power has feasted on causing one war after another, one putsch after another, one avoidable financial disaster after another. Too many have forgotten or perhaps have taken for granted America’s capacity to pursue forever wars in the name of peace and democracy.
15. German and Japanese Fascism must be made great again. The denazification of Germany was an overcorrection for which Europe is now paying a heavy price. A similar and highly misplaced commitment to Japanese pacifism must also end immediately!
16. We should applaud those who attempt to monopolise everything by means of generous government contracts. Billionaires must not be satisfied merely with their billions. To become even more obscenely rich they need grand narratives that help them convince the poor to use their freedom to keep them, the billionaires, in power. And, by the way, Palantir loves Elon, especially his grand apartheid-inspired narrative.
17. Silicon Valley must be free to do in America’s cities what it did in Gaza. Many politicians across the United States have essentially shrugged when it came to granting Palantir the right to annihilate all remaining civil liberties and human rights. This must end.
18. Epstein’s syndicate should be forgotten lest lovely people like Trump and the Clintons are deterred from entering government. The public arena must be scrutiny-free unless subversives like Sanders or Mamdani enter it.
19. We love banal public figures as long as they give Palantir all the juicy contracts. We also love colourful public figures who give Palantir all the juicy contracts.
20. We need more opium for the masses, as they are not sufficiently inebriated for us to be unimpeded in the pursuit of their complete subjugation. Questioning organised superstition is dangerous and must end.
21. Time to bring back Hitler’s hierarchy of races, with Palantir’s founders and Elon at its Aryan pinnacle. The idea that it is wrong to judge someone by the colour of their skin or their ethnicity or their religion must be jettisoned.
22. Blacks, Muslims, most Asians, and of course women, are inferior untermensch. Blokes in America, and more broadly the West, have for the past half century resisted putting these subhumans in their places in the name of inclusivity. It was a mistake. Such subhumans must never be allowed in, except as servants or sex service providers – at least until we can improve our robots, in which case we won’t need them at all.
Yann is just plain incorrect here, he’s confusing general intelligence with universal intelligence.
Brains are the most exquisite and complex phenomena we know of in the universe (so far), and they are in fact extremely general.
Obviously one can’t circumvent the no free lunch theorem so in a practical and finite system there always has to be some degree of specialisation around the target distribution that is being learnt.
But the point about generality is that in theory, in the Turing Machine sense, the architecture of such a general system is capable of learning anything computable given enough time and memory (and data), and the human brain (and AI foundation models) are approximate Turing Machines.
Finally, with regards to Yann's comments about chess players, it’s amazing that humans could have invented chess in the first place (and all the other aspects of modern civilization from science to 747s!) let alone get as brilliant at it as someone like Magnus. He may not be strictly optimal (after all he has finite memory and limited time to make a decision) but it’s incredible what he and we can do with our brains given they were evolved for hunter gathering.
Ollama now has a web search API and MCP server!
⚡️ Augment local and cloud models with the latest content to improve accuracy
🔧 Build your own search agent
🔍 Directly plugs into existing MCP clients like @OpenAI Codex, @cline, Goose (@jack) and more!
Let's go!!!! 🧵👇
Build production-ready PDF document agents with complete observability and evaluation using LlamaIndex and @FutureAGI_'s monitoring framework.
🔍 Automatically instrument your entire RAG pipeline - from PDF ingestion to vector storage to response generation - with detailed tracing
📊 Run continuous evaluations on task completion, hallucination detection, context relevance, and custom business logic
🚨 Set up real-time alerts when your document agent's performance degrades, with proactive monitoring of quality metrics
📚 Get full transparency into retrieval decisions, embedding generation, and LLM reasoning with span-level observability
This comprehensive cookbook walks through building a conversational PDF chatbot that users can trust in production. You'll learn how to use @OpenAI models for embeddings and generation, integrate @FutureAGI_'s traceAI-llamaindex package for automatic instrumentation, and set up evaluation frameworks that ensure your document agent stays reliable over time.
The tutorial covers everything from basic PDF ingestion to advanced custom evaluations, showing you how to transform a black-box chatbot into an explainable, diagnosable system.
Read the full cookbook: https://t.co/hCe2iOfJGw
⚠️Unplanned: An issue with Starlight Virtual Machine
Today on July 19th, 2025, we are experiencing technical issues with Starlight Virtual Machine in the Singapore location. Our team is already working on the situation. So far, there is no ETA, but we will keep you updated here.
Please feel free to contact our support team with any questions or concerns you may have: https://t.co/8oVMSHUk9M
Love this project: nanoGPT -> recursive self-improvement benchmark. Good old nanoGPT keeps on giving and surprising :)
- First I wrote it as a small little repo to teach people the basics of training GPTs.
- Then it became a target and baseline for my port to direct C/CUDA re-implementation in llm.c.
- Then that was modded (by @kellerjordan0 et al.) into a (small-scale) LLM research harness. People iteratively optimized the training so that e.g. reproducing GPT-2 (124M) performance takes not 45 min (original) but now only 3 min!
- Now the idea is to use this process of optimizing the code as a benchmark for LLM coding agents. If humans can speed up LLM training from 45 to 3 minutes, how well do LLM Agents do, under different kinds of settings (e.g. with or without hints etc.)? (spoiler: in this paper, as a baseline and right now not that well, even with strong hints).
The idea of recursive self-improvement has of course been around for a long time. My usual rant on it is that it's not going to be this thing that didn't exist and then suddenly exists. Recursive self-improvement has already begun a long time ago and is under-way today in a smooth, incremental way. First, even basic software tools (e.g. coding IDEs) fall into the category because they speed up programmers in building the N+1 version. Any of our existing software infrastructure that speeds up development (google search, git, ...) qualifies. And then if you insist on AI as a special and distinct, most programmers now already routinely use LLM code completion or code diffs in their own programming workflows, collaborating in increasingly larger chunks of functionality and experimentation. This amount of collaboration will continue to grow.
It's worth also pointing out that nanoGPT is a super simple, tiny educational codebase (~750 lines of code) and for only the pretraining stage of building LLMs. Production-grade code bases are *significantly* (100-1000X?) bigger and more complex. But for the current level of AI capability, it is imo an excellent, interesting, tractable benchmark that I look forward to following.
Anthropic just dropped the beautiful explaination of how they built a multi-agent research system using multiple Claude AI agents.
A MUST read for anyone building multi-agent system.
A lead agent plans research steps, spawns specialized subagents to search in parallel, and then gathers and cites results. It covers architecture, prompt design, tool selection, evaluation methods, and production challenges to make AI research reliable and efficient.
Single-agent research assistants stall when queries branch into many directions. Anthropic links one lead Claude with parallel subagents to chase each thread at once, then fuses their findings.
⚙️ The Core Concepts
Research questions rarely follow a straight path, so a fixed pipeline leaves gaps. One lead agent plans the investigation, spawns subagents that roam in parallel, and later condenses their notes into a coherent answer.
🧠 Why Multi-Agent Architecture Helps
Each subagent brings its own context window, so the system can pour in many more tokens than a single model would hold. Anthropic measured that token volume alone explained 80% of success on BrowseComp, and adding subagents pushed performance 90.2% past a lone Claude Opus 4 on internal tasks.
Running agents in parallel also cuts wall-clock time because searches, tool calls, and reasoning steps happen side by side rather than one after another.
@AnthropicAI
📰 OpenAI에서 추론에 특화된 모델인 o1의 다음 세대 모델인 o3를 발표했습니다.
일단 코딩 능력이 매우 크게 향상되어서, 이제 단순한 기능 뿐 아니라 복합적인 프로그램도 잘 작성하게 되었습니다.
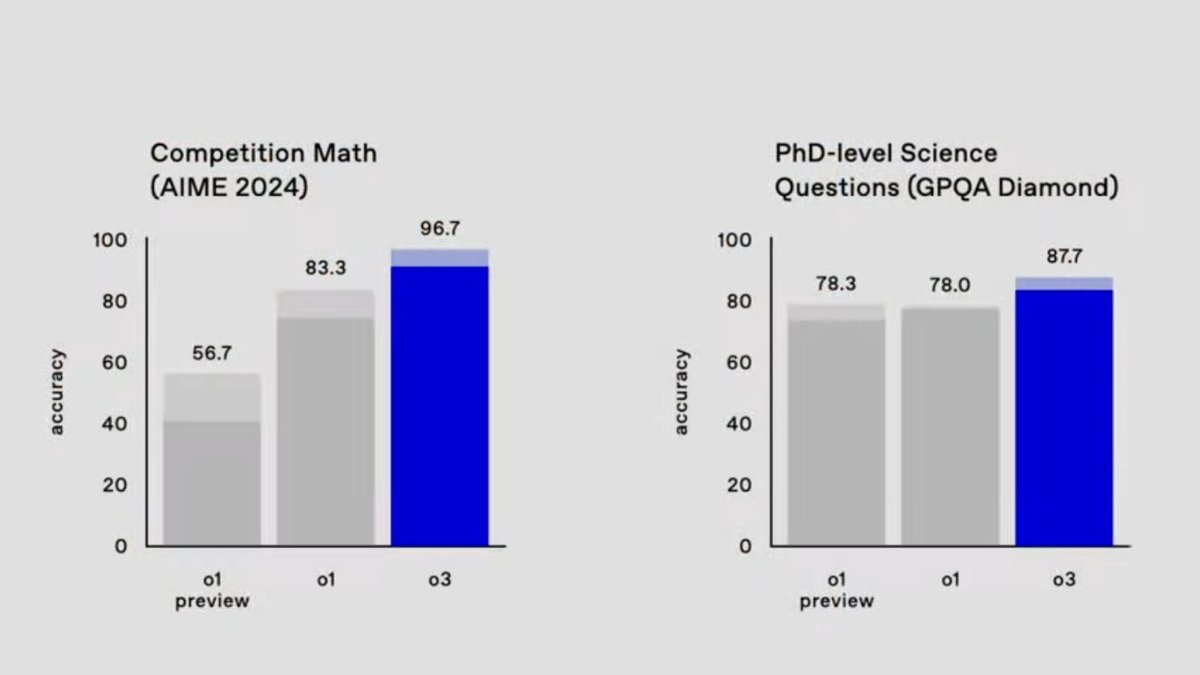
수학 능력 대회 문제 풀이를 AI들이 이제 너무 잘 해서 진짜 미친듯이 어려운 문제가 고안되었는데요. 이 벤치마크에서 현재까지 최고 모델의 성능이 2%에 불과했는데, o3는 무려 25.2%라는 압도적인 성능을 보입니다.
그리고 ARC-AGI라는, AI가 단순한 패턴 매칭이 아닌 사람처럼 추상적 사고와 일반화를 할 수 있는지 평가하는 테스트가 있는데요.
이 테스트에 대한 성능도 매우 크게 향상되어서 이제 인간 수준의 성능을 달성했습니다.
추론 능력의 발전도 돌파구를 찾고나니 진짜 어마어마하게 빠르게 발전하네요.
아쉽게도 아직 안전 테스트가 진행중이라 일반 사용자들이 사용하기까지는 시간이 좀 걸릴 것이고요. 연구자들은 신청을 통해 미리 사용해 볼 수 있다고 합니다.
내년도 또 진짜 다른 해가 될 것 같은데요. 내년 말쯤엔 왠만한 자동화는 다 알아서 해줄 것 같습니다. 진정한 입코딩의 시대가 멀지 않은 것 같네요. 😎🍿🥤
간밤에 OpenAI의 개발자 행사가 있었는데요. 4o로 데이터를 생성해서 4o-mini를 파인튜닝하는 파이프라인이나 평가 툴, ChatGPT Advanced Voice Mode를 그대로 구현 할 수 있는 Realtime API, 프롬프트 캐싱 등 유용한 기능들을 다수 발표했습니다.
기능들 자체는 대단히 유용한 기능들을 발표했지만, 익히 예상되어 있던 내용들이라 도파민이 부족했던 행사가 아니었나 싶은데요. 🤣
프롬프트 캐싱은 프롬프트가 긴 반복 작업이라면 자동으로 적용되어 구글이나 앤트로픽보다 편하게 사용할 수 있지만, 겨우(?) 50% 밖에 저렴해지지 않는다는 것이 좀 아쉽고, Realtime API도 분당 약 200원 정도의 비용이 나올 것으로 예상되는데요. 가격으로 승부하던 OpenAI 어디갔나 싶은 생각이 들었습니다. 🤣 물론 초반이라 그런거고 더 싸지긴 하겠지만요.
그보다 파이어챗에서 의미 심장한 말들이 좀 있었는데요. 그 중 몇가지를 선택해봤습니다. 벌써부터 2025년이 기대되네요. 😎🍿🥤
“역사를 되돌아보는 대부분의 사람들은 AGI가 언제 일어났는지 동의하지 않을 것이다. 튜링 테스트는 지나갔고 아무도 신경 쓰지 않았다.”
“2025년은 정말 큰 해가 될 것 같아요.”
“모델(o1)은 훨씬 더 빨리 좋아질 것입니다 [...] 아마도 이것은 GPT-2 순간일 것입니다, 우리는 그것을 GPT-4로 만드는 방법을 알고 있습니다.”
“필요한 모든 것을 동적으로 렌더링하고 컴퓨터를 사용하는 완전히 다른 방법이 될 수 있는 스크린의 미래 비전에 대해 이야기합니다.”