New paper on synthetic pretraining!
We show LMs can synthesize their own thoughts for more data-efficient pretraining, bootstrapping their capabilities on limited, task-agnostic data. We call this new paradigm “reasoning to learn”.
https://t.co/yxBMwccAUd
Here’s how it works🧵
Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
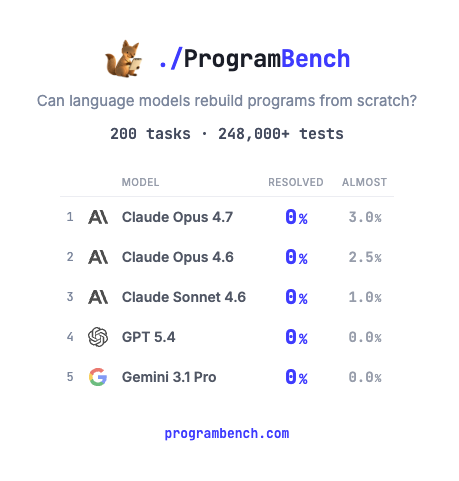
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below!
with @AlecRad and @status_effects 🧵
Sharing a super simple, user-owned memory module we've been playing around: nanomem
The basic idea is to treat memory as a pure intelligence problem: ingestion, structuring, and (selective) retrieval are all just LLM calls & agent loops on a on-device markdown file tree. Each file lists a set of facts w/ metadata (timestamp, confidence, source, etc.); no embeddings/RAG/training of any kind.
For example:
- `nanomem add <fact>` starts an agent loop to walk the tree, read relevant files, and edit.
- `nanomem retrieve <query>` walks the tree and returns a single summary string (possibly assembled from many subtrees) related to the query.
What’s nice about this approach is that the memory system is, by construction:
1. partitionable (human/agents can easily separate `hobbies/snowboard.md` from `tax/residency.md` for data minimization + relevance)
2. portable and user-owned (it’s just text files)
3. interpretable (you know exactly what’s written and you can manually edit)
4. forward-compatible (future models can read memory files just the same, and memory quality/speed improves as models get better)
5. modularized (you can optimize ingestion/retrieval/compaction prompts separately)
Privacy & utility. I'm most excited about the ability to partition + selectively disclose memory at inference-time. Selective disclosure helps with both privacy (principle of least privilege & “need-to-know”) and utility (as too much context for a query can harm answer quality).
Composability. An inference-time memory module means: (1) you can run such a module with confidential inference (LLMs on TEEs) for provable privacy, and (2) you can selectively disclose context over unlinkable inference of remote models (demo below).
We built nanomem as part of the Open Anonymity project (https://t.co/fO14l5hRkp), but it’s meant to be a standalone module for humans and agents (e.g., you can write a SKILL for using the CLI tool). Still polishing the rough edges!
- GitHub (MIT): https://t.co/YYDCk5sIzc
- Blog: https://t.co/pexZTFdWzz
- Beta implementation in chat client soon: https://t.co/rsMjL3wzKQ
Work done with amazing project co-leads @amelia_kuang@cocozxu@erikchi !!
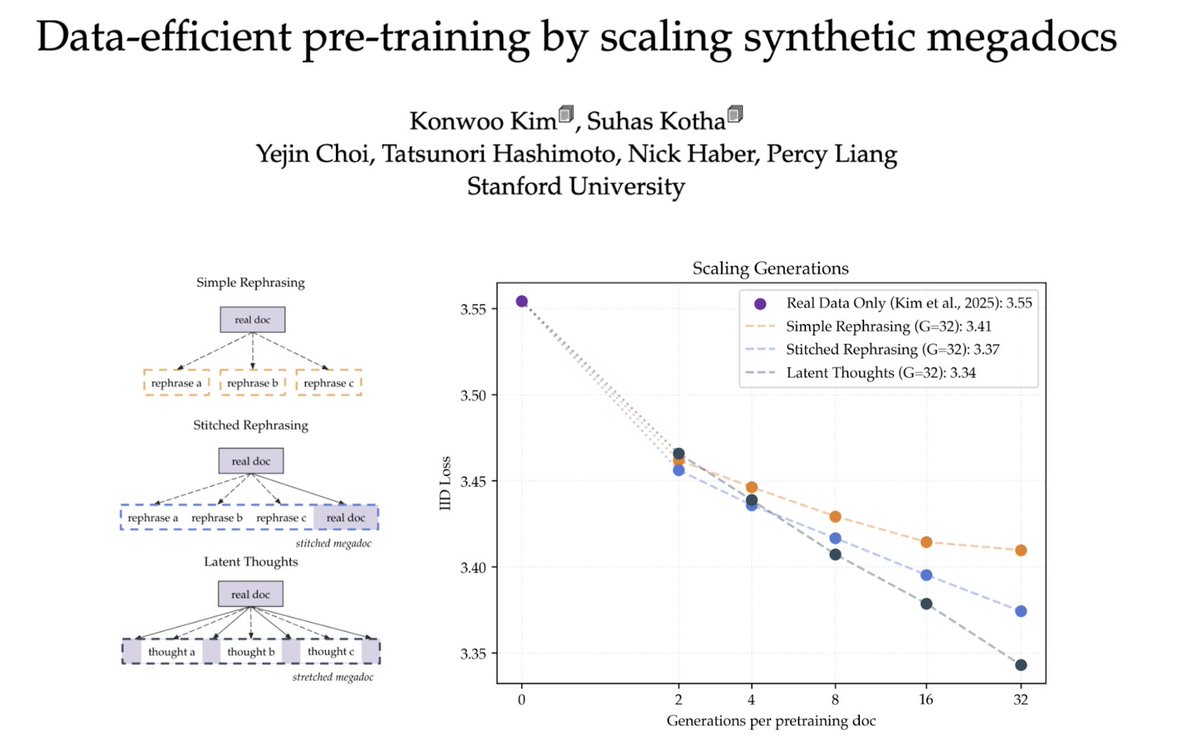
for data-constrained pre-training, synth data isn’t just benchmaxxing, it lowers loss on the real data distribution as we generate more tokens
for even better scaling, treat synth gens as forming one long 𝗺𝗲𝗴𝗮𝗱𝗼𝗰: 1.8x data efficiency with larger gains under more compute
Models are typically specialized to new domains by finetuning on small, high-quality datasets.
We find that repeating the same dataset 10–50× starting from pretraining leads to substantially better downstream performance, in some cases outperforming larger models. 🧵
Can we build a blind, *unlinkable inference* layer where ChatGPT/Claude/Gemini can't tell which call came from which users, like a “VPN for AI inference”?
Yes! Blog post below + we built it into open source infra/chat app and served >15k prompts at Stanford so far. How it helps with AI user privacy:
# The AI user privacy problem
If you ask AI to analyze your ChatGPT history today, it’s surprisingly easy to infer your demographics, health, immigration status, and political beliefs. Every prompt we send accumulates into an (identity-linked) profile that the AI lab controls completely and indefinitely. At a minimum this is a goldmine for ads (as we know now). A bigger issue is the concentration of power: AI labs can easily become (or asked to become) a Cambridge Analytica, whistleblow your immigration status, or work with health insurance to adjust your premium if they so choose.
This is a uniquely worse problem than search engines because your average query is now more revealing (not just keywords), interactive, and intelligence is now cheap. Despite this, most of us still want these remote models; they’re just too good and convenient! (this is aka the "privacy paradox".)
# Unlinkable inference as a user privacy architecture
The idea of unlinkable inference is to add privacy while preserving access to the remote models controlled by someone else. A “privacy wrapper” or “VPN for AI inference”, so to speak.
Concretely, it’s a blind inference middle layer that:
(1) consists of decentralized proxies that anyone can operate;
(2) blindly authenticates requests (via blind signatures / RFC9474,9578) so requests are provably sandboxed from each other and from user identity;
(3) relays prompts over randomly chosen proxies that don’t see or log traffic (via client-side ephemeral keys or hosting in TEEs); and
(4) the provider simply sees a mixed pool of anonymous prompts from the proxies. No state, pseudonyms, or linkable metadata.
If you squint, an unlinkable inference layer is essentially a vendor for per-request, anonymous, ephemeral AI access credentials (for users or agents alike). It partitions your context so that user tracking is drastically harder.
Obviously, unlinkability isn’t a silver bullet: the prompt itself still goes to the remote model and can leak privacy (so don't use our chat app for a therapy session!). It aims to combat *longitudinal tracking* as a major threat to user privacy, and its statistical power increases quickly by mixing more users and requests.
Unlinkability can be applied at any granularity. For an AI chat app, you can unlinkably request a fresh ephemeral key for every session so tracking is virtually impossible.
# The Open Anonymity Project
We started this project with the belief that intelligence should be a truly public utility. Like water and electricity, providers should be compensated by usage, not who you are or what you do with it. We think unlinkable inference is a first step towards this “intelligence neutrality”.
# Try it out! It’s quite practical
- Chat app “oa-chat”: https://t.co/ELf8LvxFzX
(<20 seconds to get going)
- Blog post that should be a fun read: https://t.co/OwFmyFlZH5
- Project page: https://t.co/Swerz1xDE2
- GitHub: https://t.co/38CeKajCy2
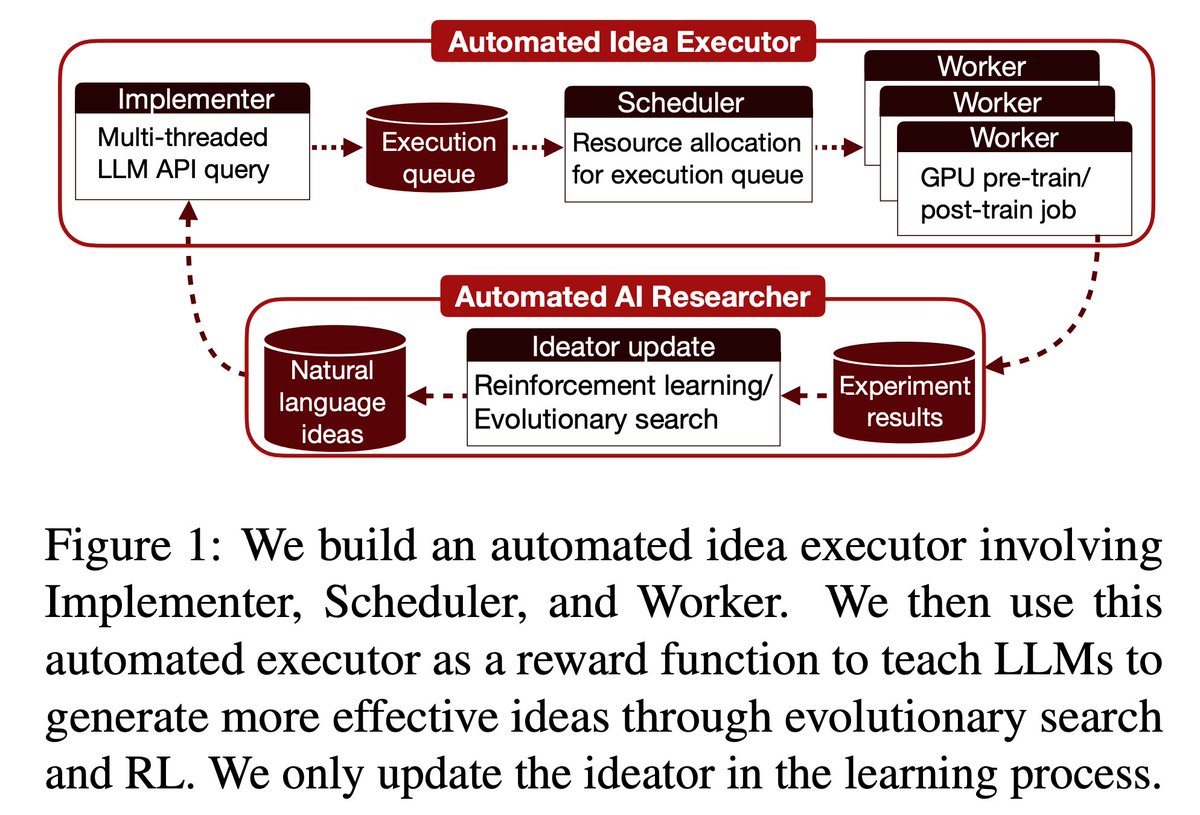
Can LLMs automate frontier LLM research, like pre-training and post-training?
In our new paper, LLMs found post-training methods that beat GRPO (69.4% vs 48.0%), and pre-training recipes faster than nanoGPT (19.7 minutes vs 35.9 minutes).
1/
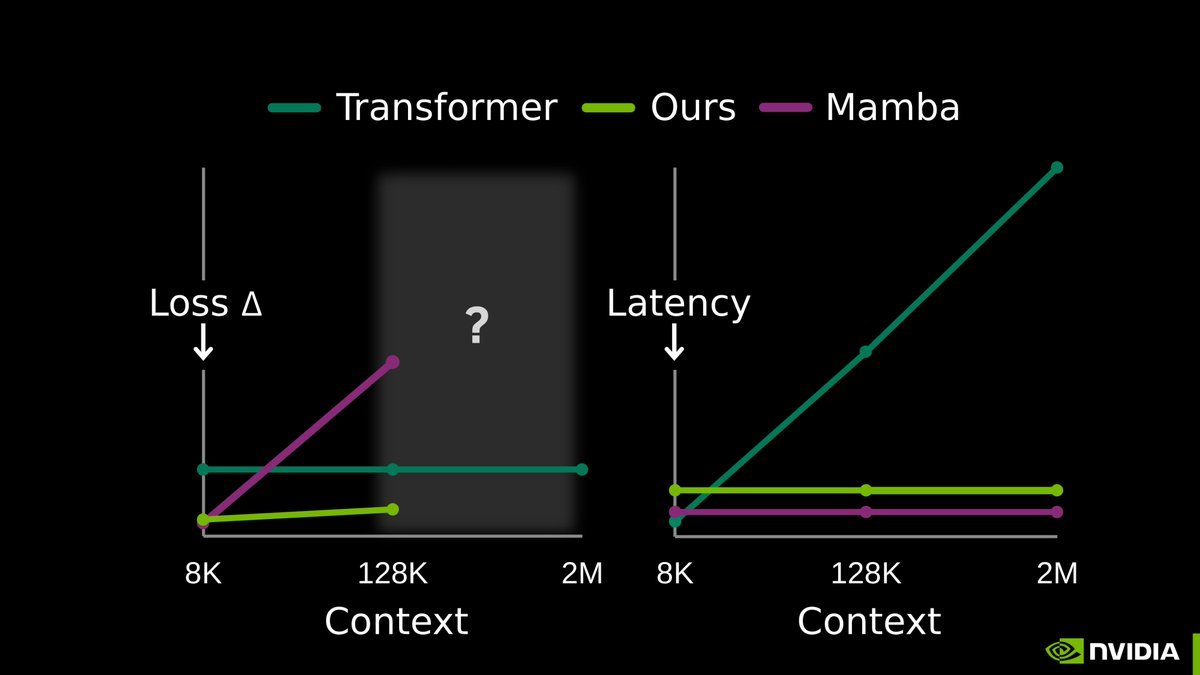
I always think TTT as the best scientific setup for studying data efficiency in the limit - and here we have some signs of life that there are very data-efficiency learning paradigms
We've seen pretraining as such a powerful learning paradigm by compressing information in the context into weights - now we should start doing that at test time, too.
LLM memory is considered one of the hardest problems in AI.
All we have today are endless hacks and workarounds. But the root solution has always been right in front of us.
Next-token prediction is already an effective compressor. We don’t need a radical new architecture. The missing piece is to continue training the model at test-time, using context as training data.
Our full release of End-to-End Test-Time Training (TTT-E2E) with @NVIDIAAI, @AsteraInstitute, and @StanfordAILab is now available.
Blog: https://t.co/woCpiIrq0T
Arxiv: https://t.co/3VkFlS3wx3
This has been over a year in the making with @arnuvtandon and an incredible team.
I’ll be attending #NeurIPS starting Wednesday as part of @thinkymachines!
Feel free to DM me if you’d like to catch up, chat about research, or learn more about Thinky (we have openings!)🤝
https://t.co/IjUWdrtEJj
Many of us from @thinkymachines are at NeurIPS this week. Would love to chat with people interested in joining us or using Tinker.
We are also giving away free Tinker credits!
Open roles: https://t.co/8nNlMhPFbq
Signup for Tinker: https://t.co/FUc8Bk9Ogn
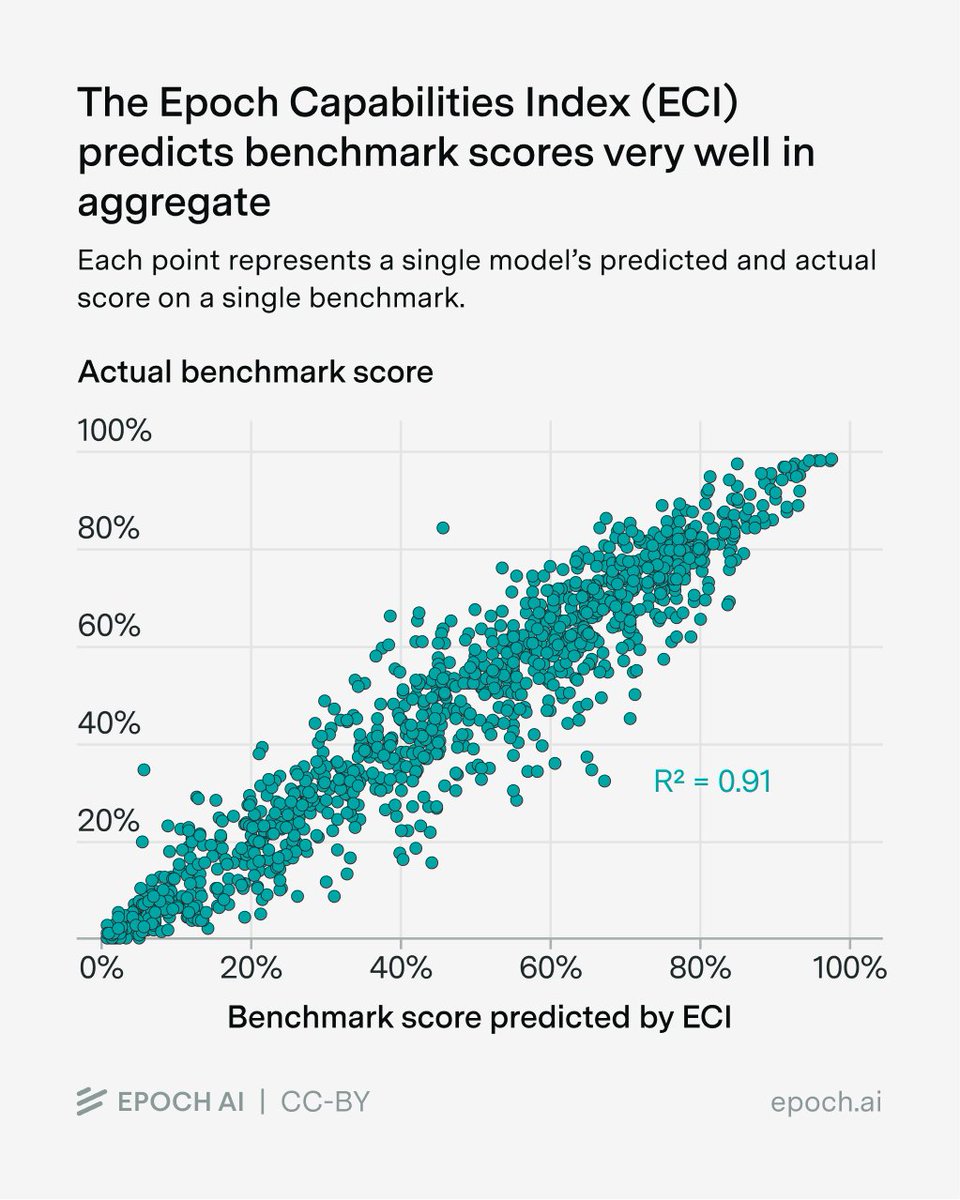
Benchmarking data is dominated by a single “General Capability” dimension. Is this due to good generalization across tasks, or to developers pushing on all benchmarks at once?
🧵 with some analysis, including the discovery of a “Claudiness” dimension.
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost.
https://t.co/JhpyWQOpBe
Fine-tuning APIs are becoming more powerful and widespread, but they're harder to safeguard against misuse than fixed-weight sampling APIs. Excited to share a new paper: Detecting Adversarial Fine-tuning with Auditing Agents (https://t.co/wCK1p6pa2c). Auditing agents search through training datasets and query the model being trained; using these tools they can detect various existing fine-tuning attacks, with a low false-positive rate.
I advised this project through the MATS program. I've been impressed by the organization of the program and the caliber of people involved.