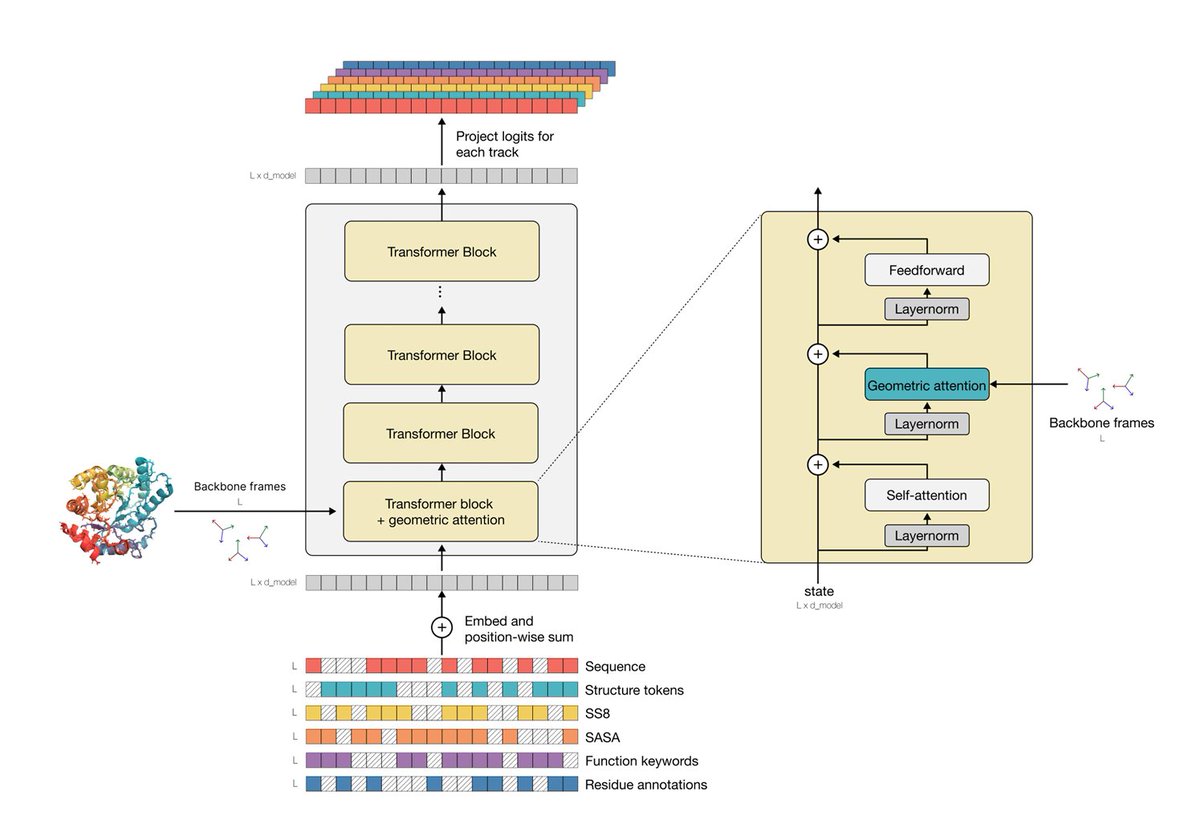
Just dived into the 40-page appendix of the latest #ESM3 paper! Combining protein function info with amino-acid sequences into a multi-modal model. Check out my observations & a simple enzyme catalytic site-prediction implementation! 🧬 🧵
For the computational community, this is the part we're most excited about 👇
APB-Display's fast turnaround (< 1 week) and low cost (<15¢/variant) could make it possible to actually close active learning loops on protein-binding models. (9/n)
With a full-stack approach to biology, integrating our entire rapid therapeutic development pipeline, from generative AI for design to GMP manufacturing, under one roof, @PopVaxIndia is built to solve problems like this at scale.
Was reading the acyclovir story and my immediate thought was, "They don't make drugs like that anymore." There is a sense in which drugs are becoming more complex (modality and mechanism-wise; usually brute forced through high throughput), but less elegant (i.e., less driven by surprising biological insights). Most ironically, even though acyclovir was part of the "rational drug design" Nobel prize in 1988 - today we don't even use that term the same way. It's rational to eyeball the structure, find pockets, dock, screen, re-dock. Back when you couldn't eyeball anything at all, you'd just end up thinking about reactions from first principles (how do viral and human kinases behave differently, let's hijack that - in the case of acyclovir). Which is all you really had! And drugs were surprising and beautiful.
In India, AI could be the ultimate anti-corruption tool: transparency, access, and smart decisions at scale. Informational transaction costs should drop to zero
A very un-patient-centric view. Why should anyone care where a drug was “invented?”
The world is flat. Either get with the times or get left in the dust.
Some more thoughts about Yann interview: Even if LLMs work great, that's missing the point. Everyone's doing the same thing now. More scale, more data, longer CoT, tweak RL. But the path to get there was completely stochastic. Attention, transformers, scaling laws, RLHF, none of it was obvious, it came from people trying very different things. We wouldn't be here if everyone had agreed early on which direction to go. Assuming the next leap comes from all of us optimizing the same recipe is dangerous. I agree that the situation today is indeed way more complicated. Back then you could test a wild idea on a few GPUs. Now every serious bet costs millions in compute. That makes it harder to explore, which makes the convergence problem even worse. But that's exactly why we need to be more intentional about funding diverse approaches, not less.
We think drugs emerge as a result of deep mechanistic foresight, but more often than not, they're the result of clinical evolution. For GLP-1 agonists, mechanistic understanding of weight loss effects emerged after, not before, the clinical breakthroughs
https://t.co/gfYuD9W9CX
"Through multiple waves of technology, from computer-aided drug design, via high-throughput screening, recombinant proteins, and genomics, techno-optimists have overestimated the innovation yield of the hot new thing. Again and again, scientists have placed too much confidence in the power of “biological insights,” or pre-clinical mechanistic foresight. Attention naturally concentrates on the few drugs that succeed, so it is easy to construct post hoc narratives of deliberate design.
Moreover, the biotech ecosystem rewards storytelling. From venture capital pitch decks to internal R&D reviews, a compelling mechanistic narrative makes a program easier to fund and justify.
Yet the empirical record shows that mechanistic foresight provides, at best, rough guidance. Drug discovery is better seen as an iterative design-make-test loop, in which real-world human data repeatedly guide the next cycle of design. Progress may depend less on hitting the best therapeutic hypothesis from the start, and more on generating a broad range of plausible attempts and winnowing them quickly based on clinical feedback. What works survives; what does not is modified or abandoned.
In previous work, we described this dynamic as clinical selection: a process in which the clinic, rather than preclinical mechanistic theory, supplies the decisive information about which interventions genuinely benefit patients. We contrasted this with the familiar “intelligent design” narrative, which imagines a linear march from target identification to rational design to cure.
Many of the most successful drugs did not emerge from deep mechanistic foresight, but from iterative, empirical exploration. The clinic functioned as an evolutionary engine. Anti-TNF drugs failed in their original indication before becoming foundational in autoimmune disease; statins survived only because physicians noticed striking patient responses after the field had largely moved on; and drugs like Avastin and Gleevec accumulated unexpected indications as human studies reshaped both their use and their mechanistic stories over time.
GLP-1 agonists offer a contemporary case in point. The earliest drugs in this class, such as exenatide, were developed for diabetes and aimed primarily at improving glycemic control. Later agents like liraglutide offered better pharmacological characteristics, making weight-loss applications more feasible. Even so, many experts thought that meaningful weight reduction was unattainable, because it required higher doses that caused unacceptable nausea. That side effect was overcome through clinical experimentation: gradual dose escalation markedly improved tolerability, enabling liraglutide’s approval for obesity in 2014.
Once a strong clinical signal existed, investment shifted back to refining the molecules themselves. Through extensive screening and chemical optimization of stability, potency, and half-life, Novo Nordisk developed semaglutide, a more durable agent suitable for weekly dosing. Clinical experimentation in patients without diabetes then delivered another surprise: patients lost far more weight than most experts predicted. At higher doses, semaglutide showed ~12.4% weight loss baseline body weight vs. placebo, a result that had previously been seen as out of reach for pharmaceutical interventions.
On the back of these results, semaglutide became one of the most commercially and clinically successful medicines of the modern era. Ongoing trials continue to reveal additional, unforeseen benefits of GLP-1 agonism, including reductions in cardiovascular events that appear independent of weight loss, as well as improvements in liver disease."
This is a good way to phrase the pitfalls of structure based modeling: compounding of errors.
Critically also there is no feedback about why something failed. Is it because the CDRs are mis aligned or because MPNN messed up or is the assumed paratope just plain wrong?
Our work blurs the line between structure and sequence-based design methods. In the past, most structure-based design methods literally specify a 3D atomic structure, then reverse-translate to an amino acid sequence with an inverse-folding model like ProteinMPNN. Approaches like these leverage strong physical priors to narrow the search space of possible sequences, but multiple modeling steps can introduce compounding errors
Biology is verifiable. Just have to run the experiments. It's "offline" verification with slow feedback loops. So, make the wet-lab go faster. Maybe paradoxically, to make AI for biology go faster, we have to make wet-lab go faster
Not specific to Noetik. If you are making a lot of function calls then any system that reduces the number of such calls makes you go faster. If this system "learns" as you make more function calls, then you have a differentiator. And LLMs are perfectly suited for this in Biology. Probably LLMs are better suited for biology than language
LLM-assisted coding killed Agile.
No business leader who saw how software can be made will ever want to wait while you t-shirt-size your features, write user stories, conduct sprint planning ceremonies, hold daily stand-ups, run retrospectives, maintain a backlog grooming ritual, estimate story points using those dumb planning poker sessions that take longer than actually building the feature, create JIRA tickets with mandatory fields that add no value, schedule cross-functional alignment meetings to align on alignment meetings, and produce burndown charts that nobody reads—all while the competition ships working software and captures market share.
A business leader will tell you what feature they need, and you will bring this feature tomorrow. The technical debt problem will be solved next year if there's still business next year.
If the end user i.e. patients benefit from this, then wouldn't that be a good thing? I find it interesting that pharma execs preach about putting patients first and without a hint of irony talk about not disclosing their targets because someone else (china) might actually solve the problem before they do
This is the most important story in biotechnology right now. We're losing the startup biotechnology ecosystem to China -- US biotech VCs are opening offices in China and large US Biopharma companies are acquiring Chinese startups (30% +of new acquisitions!) which pushes $$ back into that ecosystem. Meanwhile 30% of biotech lab space is vacant in our biotech hubs and funding of US biotech startups is at its lowest in years. This would all be a reasonable trade if there was a huge international spend on drugs that made this a global market but the US is in control of the end market for drugs as we are the ones who pay our fair share for drug development. We should flex our muscles here and keep biotech innovation in the US.
I don't see how limiting these acquisitions of Chinese companies will create any chaos as is being suggested in this article -- this isn't about drugs on the market today -- it's about the next generation of innovative medicines. For every one of these Chinese startup biotech's there is are several US competitors with a similar asset that just pays more for scientists, lab space and regulatory so is a more expensive acquisition.
Slowing or stopping these acquisitions won't be chaos -- it will just be worse returns for people that invest in Chinese startup biotechs and better returns for people that invest in US startup biotechs. If China wants to maintain a biotech ecosystem they should pay more for drugs (like we do in the US!) and support that ecosystem.
It was a mistake when we did this the first time around in the tech industry 20 years ago -- with some US tech VCs backing Chinese tech startups and building that ecosystem -- we shouldn't repeat the same mistake with biotech. And we don't need to since the US has all the cards here as we are the large majority of the end market for drugs. Hopefully WH holds the line on this one.
The fact that frontier LLMs like Claude or Gemini can take a text of thousands of lines and output (most of the time) the same input text verbatim without even a minor change is mind-blowing.
The text inside the LLM is transformed into an internal representation where no strict notion of words and their order exists, and then, after this transformation, by simply sampling tokens, this text can be perfectly reconstructed is an unbelievable feat.