A Wharton economist ran a randomized controlled trial on almost a thousand high school students in Turkey.
The result was so brutal for the AI-in-education narrative that it had to be peer-reviewed by PNAS before people would believe it.
Her name is Hamsa Bastani. She teaches operations and information at the Wharton School at the University of Pennsylvania, and the study she published in 2025 alongside her co-authors is one of the cleanest experiments anyone has run on what AI actually does to learning when you remove it from the equation and check what is left.
The setup was a randomized controlled trial, the same methodology used in clinical drug trials. Nearly a thousand high school math students in Turkey were split into three groups and put through four sessions of ninety minutes each. One group practiced with GPT Base, a standard ChatGPT-4 interface that could answer any question directly. One group practiced with GPT Tutor, a version of the same model that had been prompted to guide students with hints rather than hand them the answer. One group practiced with nothing but their textbook and their own head.
During the practice sessions, the AI groups looked like a miracle. The GPT Base group solved 48% more problems than the students working alone. The GPT Tutor group solved 127% more. Every administrator looking at those numbers would have written a press release about the transformative power of AI in education and moved on.
Then the actual exam came, and AI was not allowed.
The students who had practiced with GPT Base scored 17% worse than the students who had practiced alone. Seventeen percent worse, despite having solved nearly half again as many problems in the sessions leading up to it. The students who had struggled the most, who had sat with the confusion and worked through it without a tool to rescue them, were now the only ones who could actually do the math when it counted.
Bastani's team read through the chat logs to understand what had actually been happening during the practice sessions, and the answer was exactly what the exam results had already implied. The GPT Base group had not been learning. They had been extracting answers and moving on, and every moment that felt like understanding was actually the model doing the cognitive work while the student's brain waited for the next problem to arrive. The paper describes it precisely: without guardrails, students attempt to use GPT-4 as a crutch during practice, and subsequently perform worse on their own.
The detail that should follow every conversation about AI in education is the one buried in the post-test survey results. The students who had relied on AI the most during practice were also the most confident they had understood the material. The tool had not just failed to teach them. It had convinced them they had learned something they had not, which is a different kind of failure entirely and a much harder one to correct because the student has no idea it is happening.
The crutch had made them confident and weak at the same time.
This is maybe obvious to everyone, but it just occurred to me why bioterrorism is such a significant model risk. It's analogous to code with vulnerabilities that can never be patched.
The linear representation hypothesis says neural networks encode concepts as directions in activation space.
We trained a small model where 7 of 8 features behave this way. The 8th doesn't.
$2,500+ in prizes to whoever can tell us how it's actually encoded. Bonus points if you can train a model with an even weirder representation.
Link in thread 🧵
Space launch was a clear case where there was a large difference in efficiency between what was possible and what was done in practice before SpaceX. A large part of that was due to everything being locked in to what (just barely) already worked, with huge risk aversion. WIth national prestige or a half billion dollar geosync satellite on the line, speculative engineering ideas that might result in a public debacle were not welcome.
When failure is not an option, success can stay very expensive. You need to experiment to improve, and that fundamentally means being comfortable with failure. If you know it is going to work, it isn’t an experiment.
I have long believed that nuclear power today is in precisely the same state as space launch two decades ago, but the even more pressing question now is if semiconductor fabrication might also be.
On the one hand, Moore’s Law has been a sequence of heroic miracles of technology at the wafer fabrication level, grinding out hundreds of compounding small improvements.
On the other hand, fabs are “too big to fail”, and there are elements of extreme conservatism at play. Intel’s “Copy exactly!” fab development exemplifies that mindset – instead of every new building being an opportunity to explore and optimize processes, it was deemed more valuable to just replicate.
While each individual machine may be straining against physical limits of technology, it is possible that the systems orchestrating them all together could be far from optimal.
The explore / exploit axis is fundamental to all decision making, but human risk avoidance probably biases away from optimal exploration.
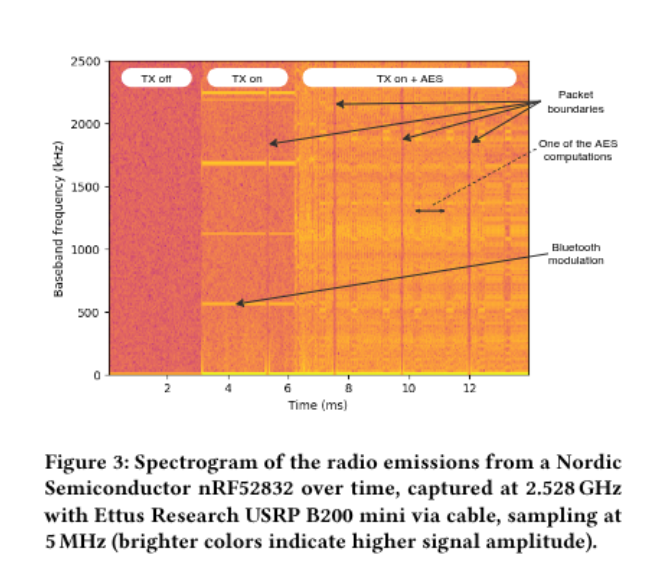
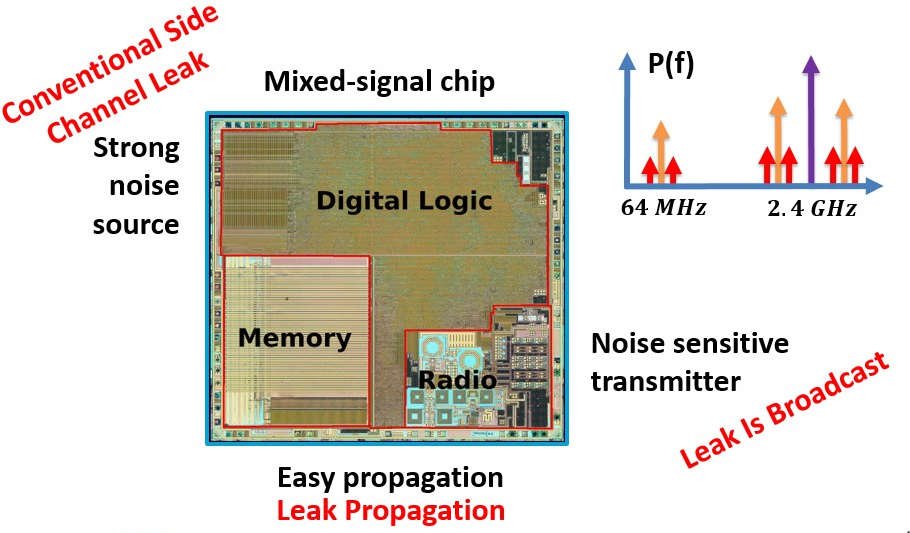
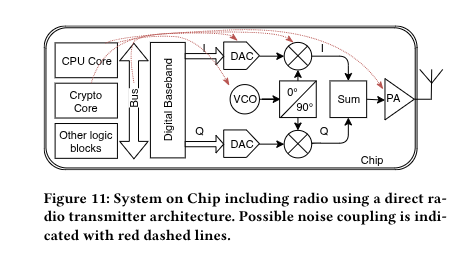
The RF world is insane.
Researchers recovered AES-128 keys from a Bluetooth chip by listening to its own antenna from 10 meters away.
Crypto-engine switching noise couples into the RF chain, rides the 2.4 GHz carrier, and leaks out as radio.
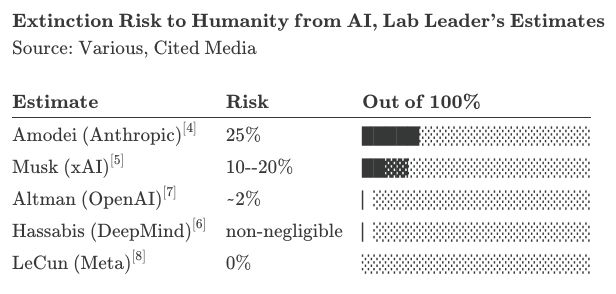
If the world’s leading scientists say there’s even a 10% chance humanity could be destroyed because of uncontrolled AI, shouldn’t we do everything possible to prevent it?
This isn’t about competition with China. It's about coming together to prevent what might be a catastrophe.
@SecScottBessent The existential threat is not about chatbots (governable by global standards). It's about the creation of superintelligent machines that nobody understands. US labs say they run that risk; foreign labs do too. We need international coordination to ensure nobody builds it.
Uncontrolled AI poses a severe danger to all of humanity.
On Wednesday, I'll be hosting a discussion with leading AI scientists from the US and China about the need for international cooperation against this existential threat. This is an enormously important issue. Join us.
In the best case scenario, Trump struck a deal to reopen a Strait that was open before the pointless war he started, with the IRGC demonstrating its control over the Strait and potentially extracting fees plus sanctions relief. Thousands of innocents - including hundreds of children - dead in Lebanon and Iran for no reason. U.S. troops killed and wounded. U.S. embassies and bases in the Middle East badly damaged. U.S. standing in the world obliterated. U.S. munitions badly depleted. Hundreds of billions spent. Prices up everywhere. More global economic fallout to come. Putin strengthened and enriched. Just a catastrophic situation even in the best of circumstances. A profoundly shameful episode in American history no matter what happens next.
Imagine Dario hopping on TikTok and saying "holy shit guys wake up, I think we're close to AIs that can automate AI research." Direct communication is underutilized.
Apparently workers in China have been creating “colleagues.skill” to distill their coworkers hoping to make them redundant hence saving themselves. In response someone has recently invented an “anti-distillation.skill” that has gone viral on GitHub.🤣