We show Transformers generalize on complex data by using shared attention patterns for similar structures
BUT how to avoid overfitting on low-complexity data?
🚨SQ-Transformer explicitly quantizes embeddings structurally & learns systematic attention
https://t.co/eaeG5gBo0d
🧵
🚀 New Paper: RSQ: Learning from Important Tokens Leads to Better Quantized LLMs
We show that not all tokens should be treated equally during quantization. By prioritizing important tokens through a three-step process—Rotate, Scale, and Quantize—we achieve better-quantized models on LLaMA3, Mistral, and Qwen2.5.
🧵👇
Check out these other awesome works from my labmates & I will present my poster virtually on Aug22 --> "Inducing Systematicity in Transformers by Attending to Structurally Quantized Embeddings (https://t.co/eaeG5gBVPL)"
Detailed thread: https://t.co/2ghFO7v26N
#ACL2024nlp
🚨 Check out an exciting batch of papers this week at #ACL2024!
Say hi to some of our awesome students & collaborators who are attending in person, and feel free to ask about our postdoc openings too 🙂
Topics:
-- multi-agent reasoning collaboration
-- structured systematicity/quantization in transformers
-- easy-to-hard generalization
-- very long-term conversational memory in LLMs
-- soft self-consistency
-- self-refining multimodal summarization
-- multimodal reasoning over image sequences
-- fine-grained hallucination evaluation and correction
-- summary-source alignments
#ACL2024nlp
👇👇
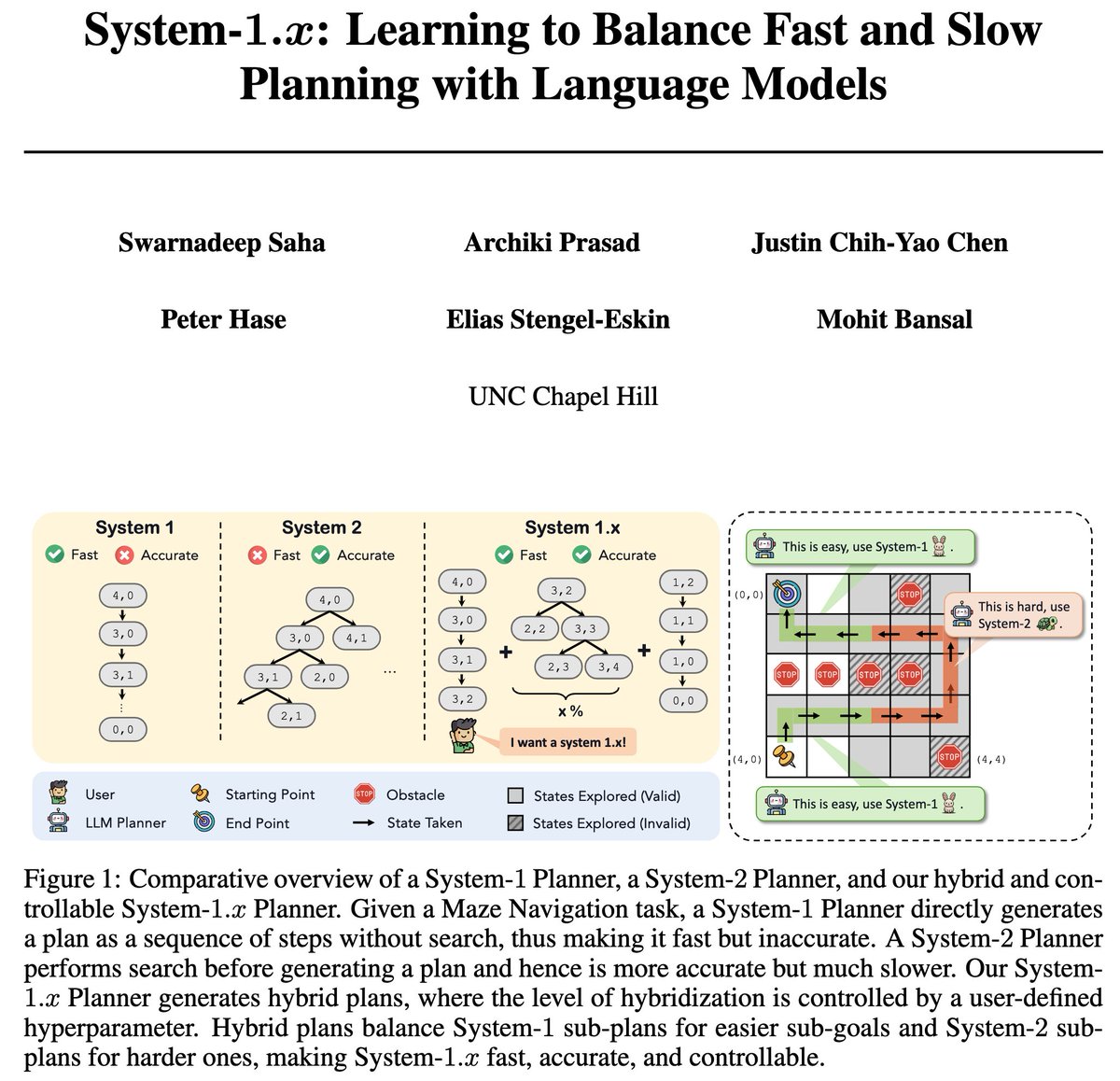
🚨 New: my last PhD paper 🚨
Introducing System-1.x, a controllable planning framework with LLMs. It draws inspiration from Dual-Process Theory, which argues for the co-existence of fast/intuitive System-1 and slow/deliberate System-2 planning.
System 1.x generates hybrid plans & balances between the two planning modes (efficient + inaccurate System-1 & inefficient + more accurate System-2) based on the difficulty of the decomposed (sub-)problem at hand.
Some exciting results+features of System-1.x:
-- performance: beats System-1, System-2 & a symbolic planner (A*) both ID and OOD (up to 39%), given an exploration budget.
-- training-time control/balance: user can train a System-1.25/1.5/1.75 to balance accuracy + efficiency.
-- test-time control/balance: user can bias the planner to solve more/less sub-goals using System-2.
-- flexibility to integrate symbolic solvers: allows building neuro-symbolic System-1.x with a symbolic System-2 (A*).
-- generalizability: can learn from different search algos (DFS/BFS/A*).
🧵👇
Having a great time at #LxMLS in Lisbon + meeting awesome people & exploring the beautiful city 🙂 (highly recommended ML school*) ➡️➡️➡️
Next stop: #ICML2024 in Vienna for MoE tutorial/panel + papers on MAGDi, ReGAL, etc. 👇 (ping me if you want to meet up / chat about faculty+postdoc+phd positions, etc.)!
(*thanks to @andre_t_martins@mariotelfig@RamonAstudill12@bgmartins + whole team for the thoughtful organization!)
We are going to present MAGDi at #ICML2024. If you are attending, say hi to @EliasEskin and @mohitban47 to know more about this work and PhD/postdoc positions @uncnlp!
🧵👇
Check out 2 useful updates on CREMA! 🚨
(1a) A new modality-sequential modular training for generalizable and efficient reasoning on video+language+any other modalities by eliminating modality interference.
(1b) A novel modality-adaptive early exit strategy allows the model to bypass the training of specific sensory inputs if this modality information is converged.
(2) More unique/rare multimodal reasoning tasks (video-touch/thermal QA) to further demonstrate the generalizability of CREMA.
See more details in Arxiv v2 👉 https://t.co/i1bmJ6wKVD
(original thread below👇)
Welcome to UNC NLP! I’m sure you will have a lot of fun doing interesting projects and living in a warmer place full of great college sports matches 😀 Best of luck!
🥳Some of the first papers I read at the start of my ML journey were @mohitban47's papers on multimodal language understanding, and after a great couple of years at Northeastern working on vision-language, I'm excited to joining his lab at @uncnlp as a PhD student to work on program synthesis + multimodal agents! 😁 (1/3) 🧵
Check out this work by my labmates on how to make LLMs not overly confident on bad answers. Spoiler 🚨: they made the model less confident on wrong data and more confident on correct ones.
🚨 Excited to share our new work on **confidence calibration** in LLMs!
LLMs are often badly calibrated & overconfident, explicitly (eg. "I'm 100% sure") and implicitly, eg. giving details/authoritative tone.
We address both w/ a pragmatic speaker-listener multi-agent method
🧵
🚨New paper👉RACCooN: remove/add/change video content effortlessly/interactively via our MLLM+Video Diffusion (V2P2V) framework with auto-generated descriptions!
▶️ 1. Video-to-Paragraph (V2P): RACCooN first generates well-structured/detailed descriptions of videos with MLLM leveraging a multi-granular pooling strategy
▶️ 2. Paragraph-to-Video (P2V): Users can then enjoy diverse video editing skills by refining auto-narratives for the video diffusion model
🧵
🚨 Introducing VideoTree! Captioning + LLMs can perform well on long-video QA, but dense frame captioning leads to inefficiency (redundancy) and sub-optimality (irrelevance).
VideoTree addresses these issues & improves LLM-based long-video QA by:
▶️ Structured Video Representation: iteratively organizing the video’s frames into a hierarchical tree representation via visual frame clustering & cluster scoring.
▶️ Adaptive Keyframe Selection and Coarse-to-Fine Sampling: dynamically selecting query-related frame clusters for captioning. Its tree structure encodes varying granularity levels, allowing VideoTree to allocate more frames (zoom-in) in relevant clusters and fewer in irrelevant ones.
Those lead to major gains on popular benchmarks, including SOTA on NExT-QA & IntentQA, and 7.0% gains on EgoSchema, while cutting ~40% inference time.
https://t.co/dUZy2DgXb3
🧵
🎉Excited to announce that SQ-Transformer is accepted to #ACL2024nlp!
We induce systematicity & achieve stronger generalization in Transformers (w/o pretraining on complex data) by structurally quantizing word embedding & regularizing attention outputs.
@XiangZhou14@mohitban47
We show Transformers generalize on complex data by using shared attention patterns for similar structures
BUT how to avoid overfitting on low-complexity data?
🚨SQ-Transformer explicitly quantizes embeddings structurally & learns systematic attention
https://t.co/eaeG5gBo0d
🧵
Agentic workflows with LLMs are now getting popular for solving complex tasks!
In one of the early works on this topic -- ReConcile, at #ACL2024nlp 🎉 -- we study collaborative model-model interactions w/ confidence-estimation & corrective convincingness btwn diverse LLMs.
🧵👇
Last weekend, I graduated from @unccs, 10 years after I wrote my first line of code in COMP 116. I'm super grateful to my advisor @mohitban47, labmates, intern mentors, and many others. Y'all can see how excited I was as I threw my cap out of the frame to the 2nd floor.
🎉🎓 Congratulations to these awesome new+old MURGeLab graduates on their hooding ceremony --> PhDs @peterbhase@yichenjiang9@adyasha10@swarnanlp (+ last year's @byryuer and @xiangzhou14, who joined us for this year's commencement) & MS @abhayzala7 🥳
Was a fun celebration with families+friends & many photo sessions in perfect weather + blue carolina skies 😀
Also, after 10 unforgettable years at Chapel Hill, 2 of those generously sponsored by @Apple Scholars in AIML PhD Fellowship, "I'm going to take my talents to Seattle and join Apple AIML". I will continue to do research in efficient and safe AI that generalizes compositionally.
Last weekend, I graduated from @unccs, 10 years after I wrote my first line of code in COMP 116. I'm super grateful to my advisor @mohitban47, labmates, intern mentors, and many others. Y'all can see how excited I was as I threw my cap out of the frame to the 2nd floor.