Awesome, however, this approach requires token_type_id for Token-Aware Clustering, which is only available in self-hosted ColBERT deployments. Most embedding-as-a-service providers don't expose this, limiting the algorithm's applicability.
this is such an impressive result: search over ~600,000,000 colbert vectors in 10 milliseconds, with a *single* CPU core.
and since this algorithm has sub-linear latency, there’s no excuse for anyone up to tens of billions of tokens
Your coding agent is burning tokens on grep like it's 1973
Because semantic search means remote APIs & babysitting an index
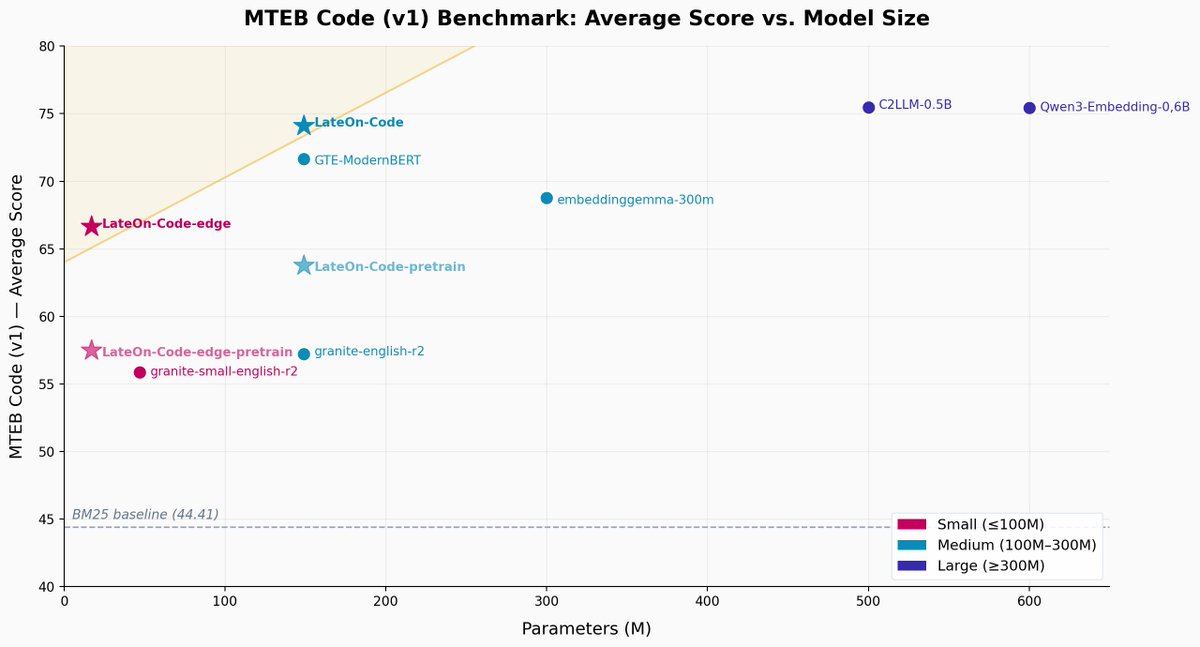
Introducing ColGrep & LateOn-Code
SOTA code retrieval with lightweight models.
Wins 70% vs grep. 15.7% less tokens.
Local, open & free. Runs on a toaster.
As we wrap up 2025, we're excited to share our year-end review:
"From RAG to Context – A 2025 Year-End Review of RAG"
#RAG#ContextEngine#Agent#ContextEngineering
https://t.co/ybhX74TLcY
Thrilled to announce that RAGFlow is featured in the GitHub Octoverse 2025 Report as one of the fastest-growing projects by contributors! 🚀
Huge thanks to our amazing community for the incredible momentum!
Check out the full report: https://t.co/DmNycCVZtY @github#Octoverse
@jobergum When you say “retrieval for agents instead of humans” are you referring to the fact that every search is initiated by an agentic-retrieval pipeline? For the underlying indexing layer, is there anything that still needs to be re-invented, or can we simply re-use existing wheels?
Your periodic reminder that late interaction isn’t “awesome but takes a lot of space” as I see here often.
ColBERT vectors are often 10 bytes each. Ten bytes. That’s like 3-4 floats.
It’s about *interactions* (aka ~attention) not “many vectors”.
It’s not “many vectors work better than one vector”. It’s “set similarity works better and trains better than a rigid dot product”.
Even with the same storage cost! You can’t fix this by making one vector bigger. You don’t need a lot of storage of the mini-vectors for late interaction.
It’s just that dot products suck.
RAGFlow is not a competitor to the items on your list; rather, it is an open-source alternative to solutions such as Databricks Agent Bricks and Glean.
Quality retrieval has never come from general-purpose storage or SQL databases.
Decades of search history (web, enterprise, recommendations) show that good retrieval systems are specialized, with purpose-built ranking. Storing a vector doesn’t cut it.
The category ‘vector database’ died, but retrieval infrastructure did not. The value shifts to relevance.
The market will reward systems that solve retrieval, not those that expose an ANN index in SQL or cloud object storage.
The infra requires to be more production ready. Storage overhead is also an important issue,such builtin support on binary quantization for multi-vector retrieval, fixed dimensional encoding, also more approaches for token merge or reduction are required.
https://t.co/T1fBlxciMs
I especially enjoyed the conversation with Antoine on "why aren't late interaction models more popular"**
(**they're downloaded >20M times per month, but one may ask why isn't it 200M!)
Rant that may be useful for others thinking about different problems:
My take on that is that most people satisfice. Think of someone who's just learned about RAG (and thinks it means dense retrievers) and is now are trying to use them to solve *their* problem.
If out of the blue you're telling them about this whole other retrieval paradigm, whoa, cognitive overload. Now you're saying they need to use a different library for it to work? Nah, they don't want the quality gain badly enough for this software risk.
Notions like storage and latency aren't really relevant to long-tail adoption here IMO.
Even a basic PLAID index from 2022 is *far* faster and more space-efficient than the *average* dense retrieval system deployed with NumPy-like basic representations! Back in 2022, we used a single CPU-only server to search >100 MILLION pages with PLAID in like 200 milliseconds. Without a GPU. (With something like our latest WARP, it's another 3x faster.)
It's just a different paradigm, and adoption of new ML paradigms that involve a new software stack is rarely about the merits. It takes community building, software building, and repeated results-backed hype until enough copy-paste pipelines trickle down to the masses... to really mainstream stuff!
But by that level of mainstream-ing, adoption stops being connected to the merits, so all the fun and community is gone by then, if you ask me.
Video of our presentation at Vector Search Conference 2025:
Breaking #RAG Barriers- RAGFlow's Technical Breakthroughs & Infinity's AI-Native Design
https://t.co/fNtgHQZthZ
Another opinionated blog post in paper form from RDBMS advocates. My opinionated take
- Nobody uses RDBMS/SQL for text search if they care about relevance (e.g., PG doesn't even use IDF, and if you don't know what IDF is, then you don't care about relevance)
- Vector databases are more than a single index type. Many tradeoffs and datasets are larger than what you fit into the buffer cache of a single instance.
- The paper introduces embeddings to represent an entire Wikipedia page, demonstrating how little they know about ML/embeddings. If you think all you need is a single embedding to represent an entire Wikipedia page for efficient RAG, then you don't care about relevance.
Awesome work, ColBERT based retrieval would have significant advantages for #RAG , Infinity will have native support very soon!
https://t.co/AJllLdNxzN
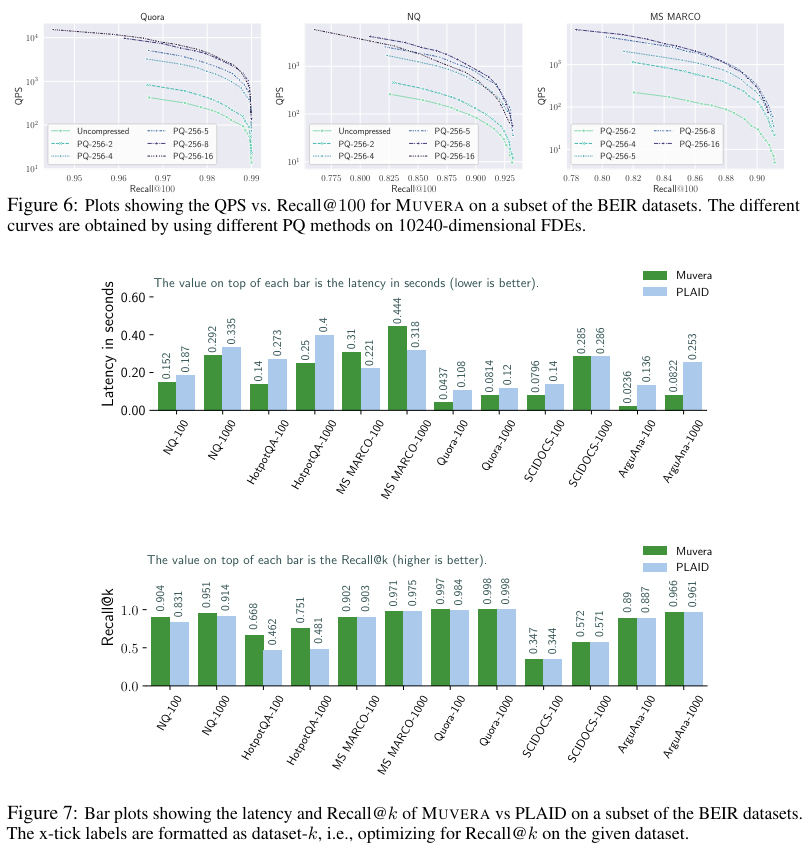
MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings
Google proposes a retrieval mechanism that reduces multi-vector retrieval to single-vector retrieval by constructing Fixed Dimensional Encodings of a multi-vector representation.
📝https://t.co/lyccQGPRMc
Introducing AGRaME for Any-Granularity Ranking with Multi-Vector Embeddings to rank at varying levels of granularity while maintaining encoding at a single (coarser) level.
Link to paper: https://t.co/7CnayKs7hJ
(1/4)
We have already open sourced AI native database infinity(https://t.co/tyMzCMVpzT), why would open source yet another #RAG engine RAGFlow? This article explains the reason, and tells the detailed product design 👉 https://t.co/nQ6GCeiQRs
RAGFlow, the deep document understanding based #rag engine is open sourced, offering a streamlined RAG workflow for businesses, combining #LLM to provide truthful question-answering with solid citations from data of complex formats. 👉 https://t.co/N5MGll5l3s
Infinity, the AI-native database for next-gen RAG, is open sourced, offering builtin fused search capabilities including vector search, full-text search, and structured data search with 0.1ms latency on 8 cores and 1M SIFT dataset 👉: https://t.co/vb6zp7Zz6H #vectordatabase#rag
I am very excited to post that together with Tomasz Kociumaka we propose the first dynamic suffix array with O(polylog(n))-time queries and updates! This is the first solution (30+ years after the discovery of suffix array) with all polylog(n) operations!
https://t.co/W1CamSIXCM