@xgonwhat @MattPRD@yesnoerror execution beats hype every time. public beta launch is proof of concept, not just promises. most ai projects were just narratives with no product
sentience online: $IRIS now has utility.
token holders can now activate deep scans — more advanced, high-capacity security scans — by paying for them directly onchain.
this marks the first operational use of the $IRIS token. deep scan now available for I.R.I.S.
The $YNE private beta product is used by top AI leaders from @Google@Perplexity@MIT@Yale@CarnegieMellon@Anthropic and more. We are in a rare feedback loop with the the top AI engineers and researchers.
The co-founder of $60B AI mega-giant @AnthropicAI
is in our DMs.
We are bridging to @base and @jessepollak the founder of base is in our DMs. We have a tg with their team. The creator of @yesnoerror@mattprd has been speedrunning learning to code everything in the @base ecosystem.
We are supported by @reidhoffman the founder of
@LinkedIn, @davemorin one of the godfathers of the social web, @BoostVC one of the earliest investors in @coinbase and pioneers of the blockchain and future, and many more.
We are building something in AI and science that doesn't exist but is desperately needed.
// $YNE loading
// seek truth
And we are off to the races! So fun to check @yesnoerror every day to see the day's trending AI research papers. Let me know if you want to try it out.
1) @arxiv published the new papers that were submitted last Friday
2) @yesnoerror is auto indexing them
3) @yesnoerror is analyzing them with AI
4) @yesnoerror is tracking their engagement on @x to see which ones are being talked about the most
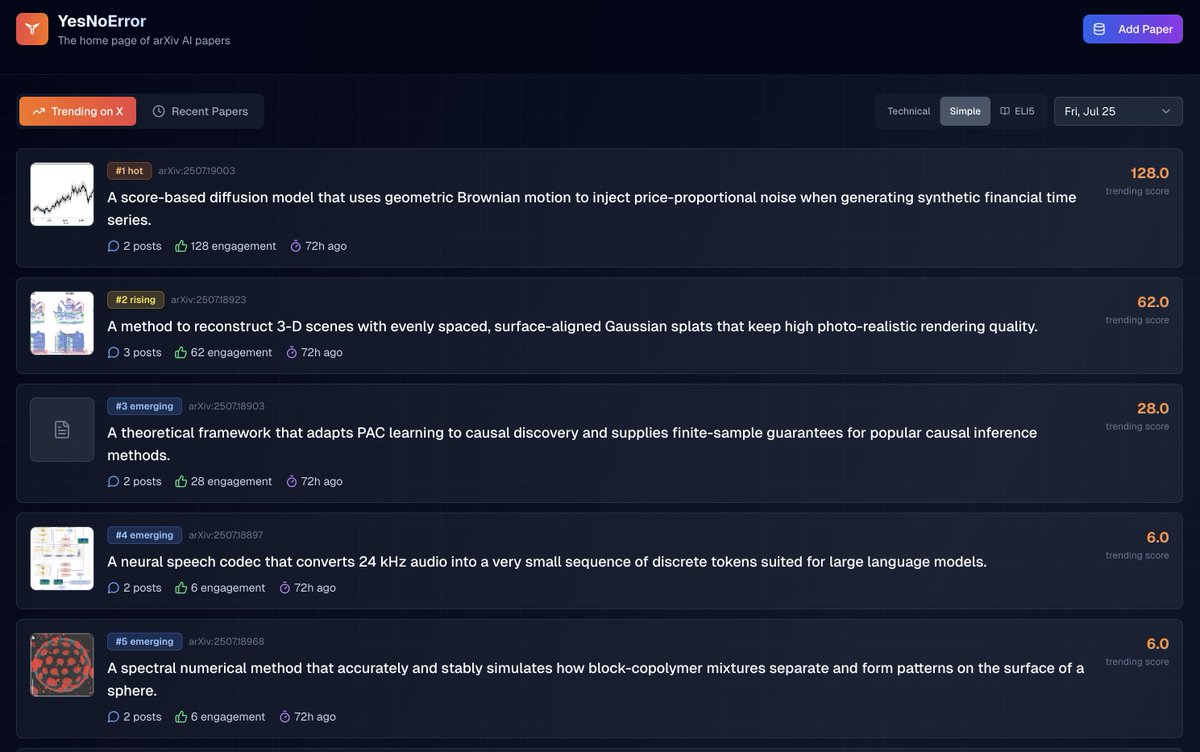
This paper just jumped to the top of the trending list:
"A diffusion-based generative model for financial time series via geometric Brownian motion"
What is it?
A score-based diffusion model that uses geometric Brownian motion to inject price-proportional noise when generating synthetic financial time series.
Explain it like I'm 5
Teaching computers to add noise that grows with stock prices lets them create fake market charts that look and behave much more like real ones, including big crashes and bumpy volatility.
Excited to see the race continue to unfold throughout the day!
// identifying alpha
// $yne
Ok, I love this feature I just added to @yesnoerror!
You can now toggle the @arxiv paper titles between technical, simple, and ELI5 (explain it like I'm 5).
This makes new research papers much more accessible to the average person because it isn't gating the information behind technical speak.
See the three versions here.
BREAKING: Our team's analysis uncovered that less than 7.5% of AI research papers published on @arxiv are ever shared on @x.
Just because a paper isn't shared on @x is not an indicator that it is not valuable.
The @yesnoerror AI agent finds the gems in the other 92.5% of papers that nobody is talking about.
Unlock the alpha with $YNE.
// onwards
Waking up to see this new paper from @scale_AI charting on the @yesnoerror trending feed.
Authors: @anisha_gunjal, @aytwang, Elaine Lau, @vaskar_n, @BingLiu1011, and @SeanHendryx
"Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains"
Simplified: Teaching computers with detailed check-lists instead of vague thumbs-up ratings lets them learn better answers in medicine and science questions and makes it clear why they got a reward.
Key findings:
• Implicitly aggregated rubric rewards boost medical benchmark score by 28 % relative to Likert baseline.
• Matches or exceeds rewards based on expert reference answers despite using smaller judges.
What can it be used for:
• Fine-tuning clinical decision support chatbots with medical safety rubrics.
• Training policy-analysis or legal-reasoning models where multiple subjective factors matter.
Detailed summary:
Rubrics as Rewards (RaR) is proposed as an interpretable alternative to opaque preference-based reward models when fine-tuning large language models (LLMs) with reinforcement learning. Instead of asking humans to rank whole answers, domain experts (or a strong LLM guided by expert references) write a prompt-specific checklist of 7–20 binary criteria that capture essential facts, reasoning steps, style and common pitfalls. Each criterion is tagged Essential, Important, Optional, or Pitfall and given a weight. During on-policy training the policy model (Qwen-2.5-7B in the paper) samples 16 candidate answers per prompt. A separate judge LLM (GPT-4o-mini or smaller) is prompted either to score each criterion separately (explicit aggregation) or to read the full rubric and output one holistic Likert rating 1–10 (implicit aggregation). The normalized score becomes the scalar reward and the policy is updated with the GRPO algorithm.
The authors curate two 20 k-example training sets—RaR-Medical-20k and RaR-Science-20k—by combining existing medical and science reasoning corpora and generating synthetic rubrics with o3-mini or GPT-4o. Evaluation on HealthBench-1k (medical reasoning) and GPQA-Diamond (graduate-level physics/chemistry/biology) shows that RaR-Implicit yields up to a 28 % relative improvement over simple Likert-only rewards and matches or exceeds rewards computed by comparing to expert reference answers. Implicit aggregation consistently outperforms explicit, demonstrating that letting the judge decide how to combine criteria works better than fixed hand-tuned weights.
Rubric supervision also helps smaller judge models. When asked to rate preferred versus perturbed answers, rubric-guided judges choose the preferred answer far more reliably than equally sized Likert-only judges, narrowing the gap between a 7 B evaluator and GPT-4o-mini. Ablations reveal that prompt-specific rubrics beat generic ones, multiple criteria beat essential-only lists, and access to an expert reference while drafting rubrics materially boosts downstream performance. Even human-written and high-quality synthetic rubrics perform on par, suggesting scalability.
RaR generalises Reinforcement Learning with Verifiable Rewards (RLVR): when the rubric has just one correctness check, the framework collapses to RLVR’s exact-match reward. By exposing each aspect of quality explicitly, RaR is more transparent, auditable and potentially harder to reward-hack than neural reward models. The authors discuss extensions to real-world agentic tasks, dynamic curriculum via rubric weights, and formal robustness studies.
--
Over 500,000 pages of research are published on @arXiv every month. Hidden within are breakthrough insights that could transform your work — but finding them is like searching for diamonds in an ocean of data. @yesnoerror cuts through the noise to surface the most impactful research for your projects, investments, and discoveries.
// $yne
I want an easy way to keep up with the HUNDREDS of new AI research that comes out on @arxiv every single day.
So I've been building something to help myself. Introducing @yesnoerror.
I would love to share it with you! ❤️
I have not published a paper myself, I didn't go to college, but I love AI and I love frontier technologies where people are trying things nobody has ever tried before. I feel lucky to be where I am in life, but I want to learn and push myself even more.
If you, like me, wish you could read and understand more about the latest developments in this amazing industry, you might also love this.
I have been building this in private beta and updating it in real time as I get feedback from researchers and leaders at @AnthropicAI@MIT@Yale@CarnegieMellon and more.
If you would like to be an early tester, please let me know 🧪🔬
The more feedback I get, the better we can make this, and the better we make this, the more informed and inspired a larger group of people can be.
Saw this in my feed.
Checked @yesnoerror to see if it had already read and analyzed this paper.
It had! Awesome.
Here are the key findings from this paper.