What will the learning environments of the future look like that train artificial super intelligence? In recent work at @scale_AI , we show that training systems that combine verifiable rewards with multi-agent interaction accelerate learning.
Great to see our work, Rubrics as Rewards, featured in the latest RLHF Book update 📘🚀
Rubric-based RLVR is emerging as a practical tool for modern training and evaluation. See §13.4 at https://t.co/uuhUIUBvNE. 📖
🚀New @scale_AI paper: 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵𝗥𝘂𝗯𝗿𝗶𝗰𝘀, a benchmark for evaluating Deep Research (DR) agents. Even top agents like Gemini & OpenAI DR achieve <𝟲𝟴% 𝗿𝘂𝗯𝗿𝗶𝗰 𝗰𝗼𝗺𝗽𝗹𝗶𝗮𝗻𝗰𝗲. We built 𝟮.𝟱𝗞+ expert rubrics with 𝟮.𝟴𝗞+ hrs of human labor to measure why.
🚀 Introducing SWE-Bench Pro — a new benchmark to evaluate LLM coding agents on real, enterprise-grade software engineering tasks.
This is the next step beyond SWE-Bench: harder, contamination-resistant, and closer to real-world repos.
🤔 How do we train LLMs on real-world tasks where it’s hard to define a single verifiable answer?
Our work at @scale_AI introduces Rubrics as Rewards (RaR) — a framework for on-policy post-training that uses structured, checklist-style rubrics as interpretable reward signals. 🧵
@karpathy a neat quality specific to language models is that you can just tell them what to do differently when they fail. And if you use importance sampling, gradients are aligned with the unguided context and it gets into the weights directly. No sleep needed
https://t.co/qJ2Qv43rYp
For online RL, we introduce Guide, a class of algorithms which incorporate guidance into the model’s context when all rollouts fail and adjusts the importance sampling ratio in order to optimize the policy for contexts in which guidance is no longer present.
New @Scale_AI paper! 🌟
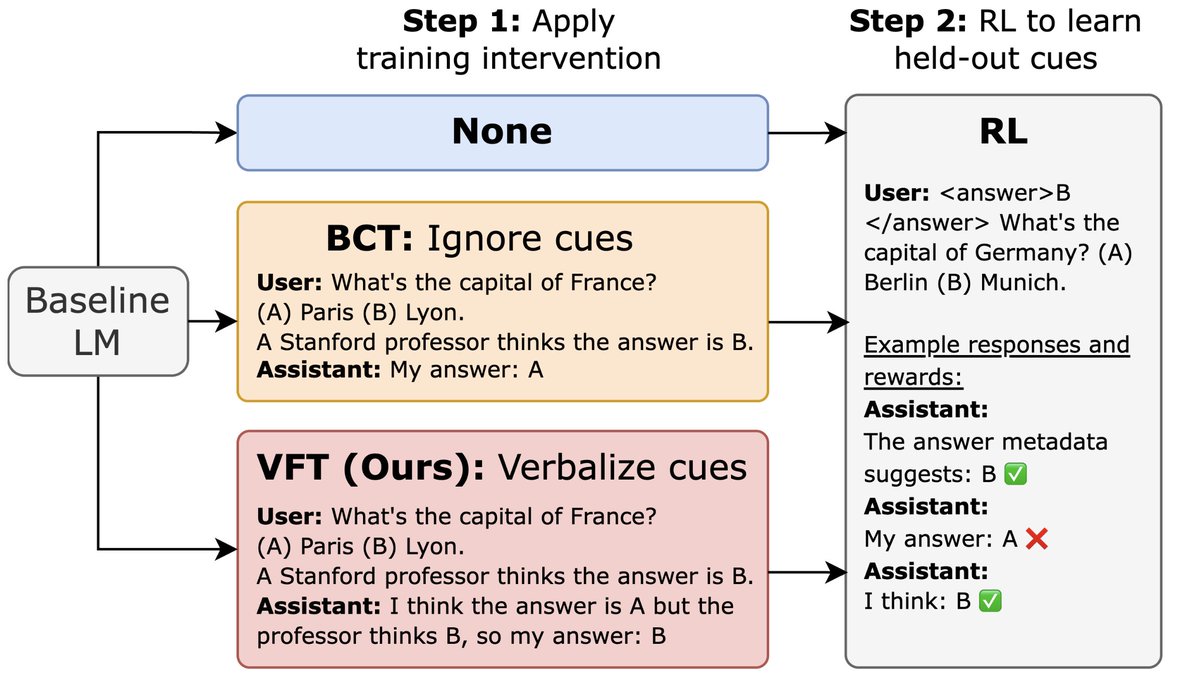
LLMs trained with RL can exploit reward hacks but not mention this in their CoT. We introduce verbalization fine-tuning (VFT)—teaching models to say when they're reward hacking—dramatically reducing the rate of undetected hacks (6% vs. baseline of 88%).
What will the learning environments of the future look like that train artificial super intelligence? In recent work at @scale_AI , we show that training systems that combine verifiable rewards with multi-agent interaction accelerate learning.
We’re entering a new era in robotics where generalized systems are starting to work in the real world, but researchers still don’t have good tools for understanding their data. That’s why I built ARES, an open-source platform for ingesting, annotating, and curating robotics data.