@aHpaBean Thanks! I’ll look forward to your update once the paper is online.
And thank you for your kind words about our Hyper-Connections work — I really appreciate your interest. Looking forward to seeing more of your work in this direction as well!
After reading the v4 tech report, a model of this scale really shouldn't be this unstable. They need to look into the issue thoroughly. I think there are indeed some internal problems at DeepSeek, but I hope they can bounce back soon.
@xiaolonw This is a solid piece of work. I found reading your paper very inspiring. Congratulations on such a great result—I must admit, I'm a bit jealous of this work!
@_arohan_@YouJiacheng While we independently developed over-encoding, we acknowledge that Ngrammer introduced a similar technique earlier. However, the primary contribution of our work, the Over-Tokenized Transformer, lies in the discovery that the input ngram vocab follows a log-linear scaling law.
@MadHermitHimbo The computation of concatenating is non - negligible. The computation of the unembedding layer is quite substantial. When concatenating, this part of the computation will be magnified by n times.
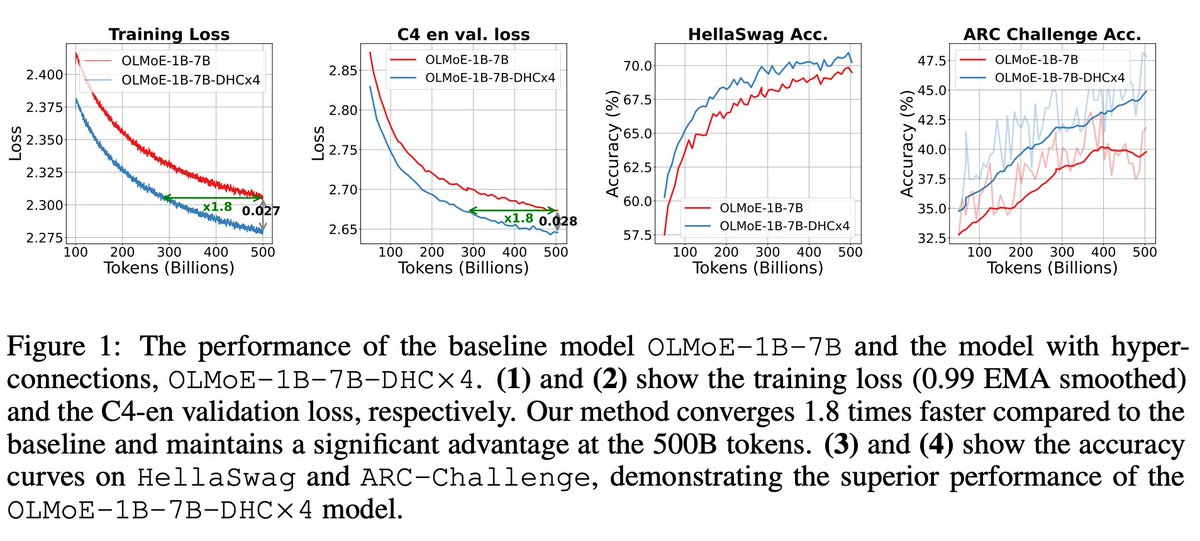
🎉 Thrilled to announce that our paper "Hyper-Connections" has been accepted at ICLR 2025! 🚀
💡 Discover how Hyper-Connections improve performance in LLMs & vision models. Faster convergence, better results! 💪
📄 Paper: https://t.co/bJwYFTpCMC
#LLM#LLMs#AI