Went exploring my @BITCOIN_GRIZZY a bit today and found out he’s got a pretty cool dad… hahaha
Parent/child provenance in collections is honestly one of the coolest parts of Ordinals. No dependency on marketplaces, just permanently indexed on-chain forever.
Stay $GRIZZY
Google Cloud AI engineer just showed how they go from idea to deployed app at Google in 30-minutes using Claude.
26-minutes. free. by Google AI team.
one person + Claude + Google Cloud = a full engineering org running on a laptop.
worth more than any $500 vibe-coding course.
GM everyone!
Over the past 3 weeks, I’ve been building something in my free time to better visualize my inscriptions and create narratives from the public data behind each one… and honestly, it turned out pretty cool.
I built a wiki inspired by @karpathy style methods, where every inscription has its own on-chain data, social narratives, and links to its collection when applicable, turning raw inscription data into something more explorable.
If you'd like to try it out, visit https://t.co/HDZaqysysO
It’s fully open-source, and I’d be incredibly grateful for any contributions from the community. I also think it could become a really nice repository for people studying prompt engineering, orchestration, and AI-native knowledge systems.
Now that Gemini Embedding 2 is GA, let’s explore what the model unlocks — from agentic multimodal RAG to visual search — as it maps text, images, video, audio, and documents into a unified embedding space.
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights:
The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons:
1. menugen: an app that can be fully engulfed by LLMs, with no classical code needed: input an image, output an image and an LLM can natively do the thing.
2. install .md skills instead of install .sh scripts. Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say "just show this to your LLM". The LLM is an advanced interpreter of English and can intelligently target installation to your setup, debug everything inline, etc.
3. LLM knowledge bases as an example of something that was *impossible* with classical code because it's computation over unstructured data (knowledge) from arbitrary sources and in arbitrary formats, including simply text articles etc.
I pushed on these because in every new paradigm change, the obvious things are always in the realm of speeding up or somehow improving what existed, but here we have examples of functionality that either suddenly perhaps shouldn't even exist (1,2), or was fundamentally not possible before (3).
The second (ongoing) theme is trying to explain the pattern of jaggedness in LLMs. How it can be true that a single artifact will simultaneously 1) coherently refactor a 100,000-line code base *and* 2) tell you to walk to the car wash to wash your car. I previously wrote about the source of this as having to do with verifiability of a domain, here I expand on this as having to also do with economics because revenue/TAM dictates what the frontier labs choose to package into training data distributions during RL. You're either in the data distribution (on the rails of the RL circuits) and flying or you're off-roading in the jungle with a machete, in relative terms. Still not 100% satisfied with this, but it's an ongoing struggle to build an accurate model of LLM capabilities if you wish to practically take advantage of their power while avoiding their pitfalls, which brings me to...
Last theme is the agent-native economy. The decomposition of products and services into sensors, actuators and logic (split up across all of 1.0/2.0/3.0 computing paradigms), how we can make information maximally legible to LLMs, some words on the quickly emerging agentic engineering and its skill set, related hiring practices, etc., possibly even hints/dreams of fully neural computing handling the vast majority of computation with some help from (classical) CPU coprocessors.
Gemini CLI v0.40.0 Release Notes📝
• New tiered memory system 🧠
• Automatic skills generated based on past sessions 🛠️
• Gemma support for local routing 💎
• Streamlined UI with compact tools and topics 💭
Checkout all the details below 👇
ComfyUI is the most flexible, composable, and powerful open-source media generation tool with a massive ecosystem of workflows and custom nodes.
Your Hermes Agent can now install, launch, manage, and run sophisticated @ComfyUI workflows on demand.
Transformers are not the end game. AI still needs a breakthrough
I talked to @FidlerSanja, VP of AI Research at NVIDIA, leading company's Spatial Intelligence Lab, and she explains why ↓
And you should definitely watch our full conversation to understand where AI is heading and why physical AI is the next big frontier: https://t.co/k9NGy4g8fe
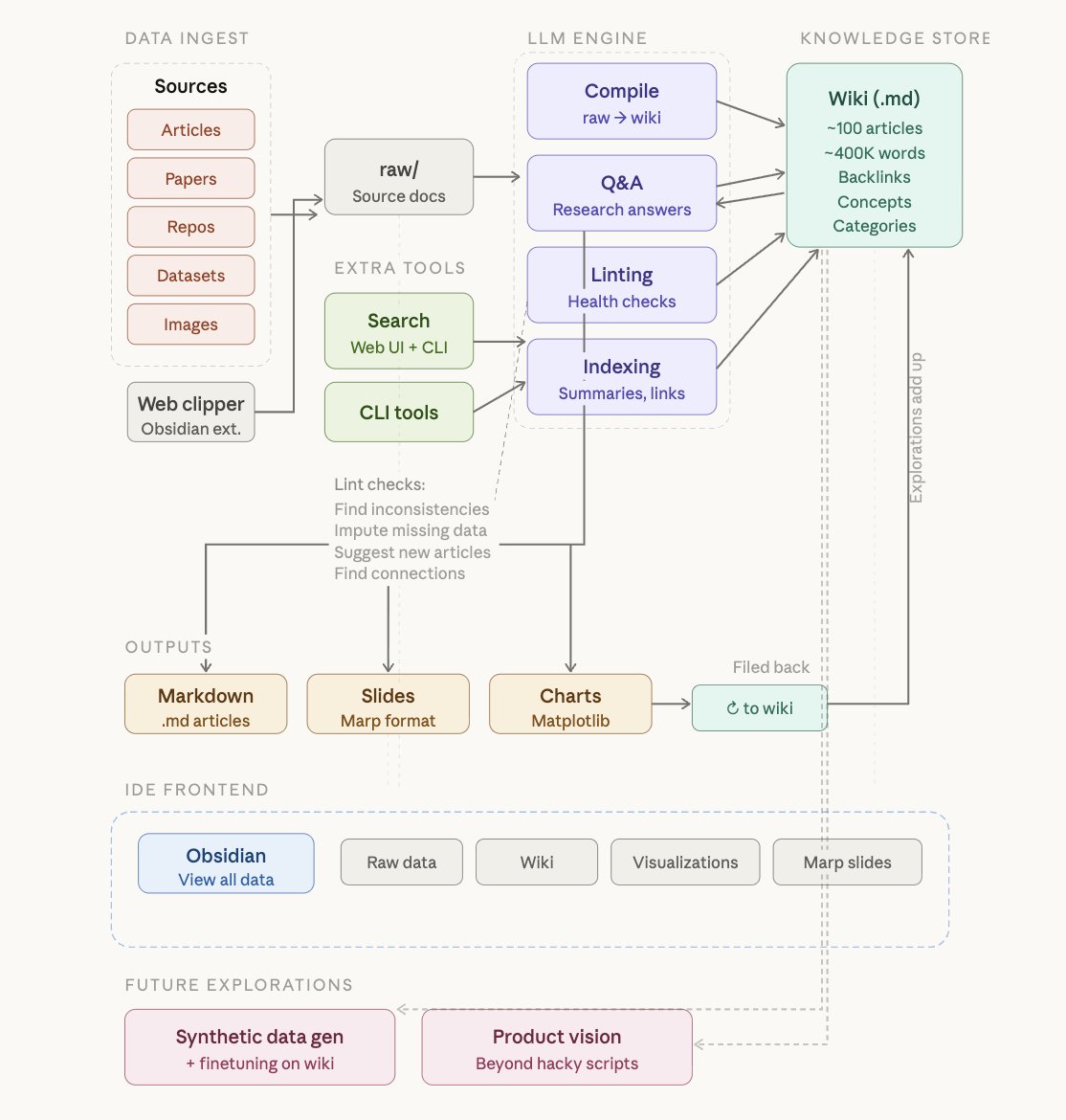
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
AI in robotics gets all the attention right now, but sometimes the most interesting work is very practical.
Viet built a small vision system that counts potatoes on a conveyor belt. No giant dataset. No huge model. Just a clear problem and a smart setup.
He used Ultralytics’ ObjectCounter, trained a tiny YOLO11 nano model, and because there was no potato dataset, he annotated a single frame with SAM 2 and trained from that. One frame. Still works across the whole video.
It is a good reminder that useful AI in industry often looks like this.
Focused. Lightweight. Solves a real task.
If you work in manufacturing or robotics, these small systems are usually the fastest wins. They save time, reduce errors, and do not need massive infrastructure.
Nice work, Viet.
His projects:
https://t.co/1TSrwcKGCW
—-
Weekly robotics and AI insights.
Subscribe free: https://t.co/dsa6wcvq6n