Jide Ogunjobi shows how easy and quick it is to build cross platform ETL and pipelines from a single query instance using @pinecone
https://t.co/6vjvuB6XoM
#developerlove#community
Ready to see how we’re redefining data infrastructure for your enterprise generative AI application?
Check out our latest teaser video to see how Context Data makes it easier than ever to optimize and unify your data.
Discover seamless integrations, advanced data management, and graphs — all in one platform!
👉 Let’s talk about how Context Data can elevate your enterprise generative AI strategy
#ai #generativeai #openai #pinecone #cursor #vectordatabase
𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐢𝐧𝐠 𝐌𝐚𝐧𝐚𝐠𝐞𝐝 𝐏𝐢𝐧𝐞𝐜𝐨𝐧𝐞 𝐈𝐧𝐝𝐞𝐱𝐞𝐬 𝐛𝐲 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐃𝐚𝐭𝐚
In order to make end-to-end vector data processing and storage as seamless as possible, we're launching managed indexes where our customers give Context Data permission to create and manage @pinecone indexes on their behalf.
This benefits small to mid level clients who need to be able to quickly process their data without having to sign up for multiple services. They can quickly connect to multiple data sources, create their Pinecone indexes in a few clicks and start processing data in a few minutes.
We're testing this with a few clients and offering 30-day free access to this service for new users who schedule a demo before October 30th!
Link to schedule is in comments
#vectordatabase #vectordb #ai #pinecone #generativeai #openai #rag
🌟 Introducing our no-code @UnstructuredIO integration
If you're using the @UnstructuredIO API to extract data from your files, you can use our very simple no-code integration to process and write the extracted data/embeddings to multiple vector databases and stores.
#vectordata #rag #ai #generativeai #OpenAI
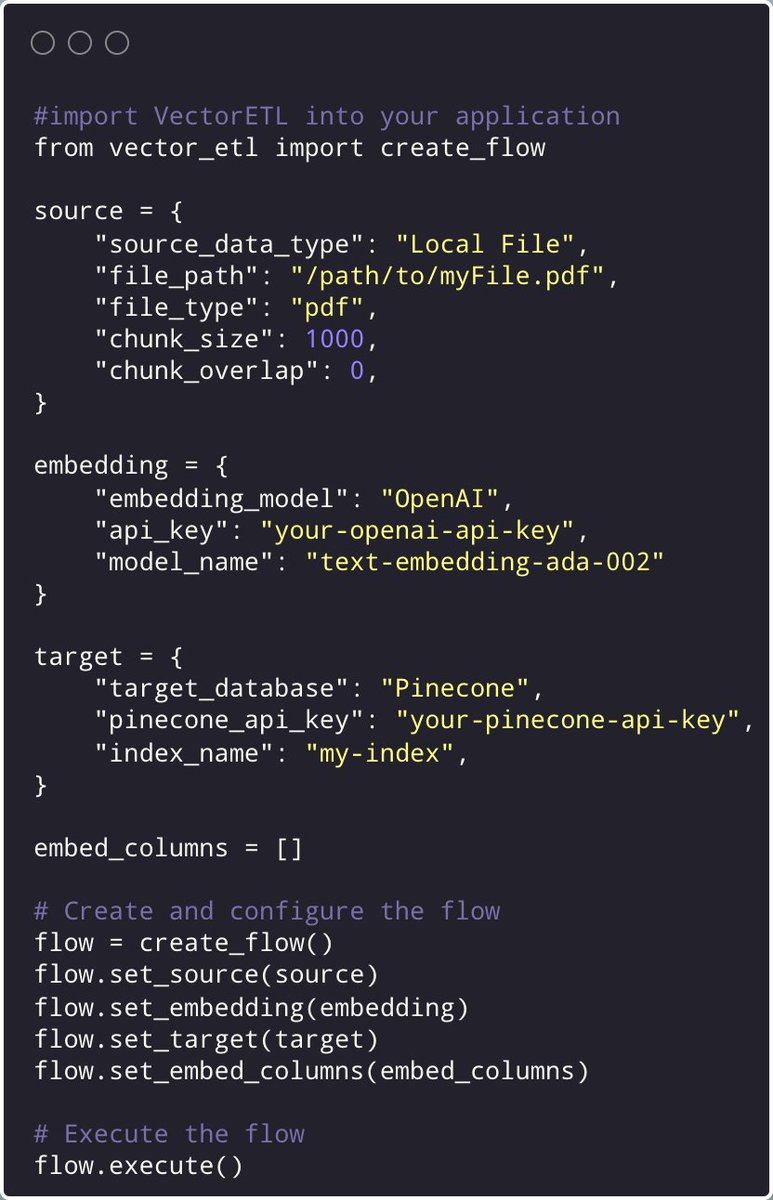
🌟VectorETL v1.7 just dropped with a massive update 🌟
You can now import and integrate VectorETL into your python application workflow (RAG, Vector Search or otherwise) and process your vector data to all major Vector databases much faster!
#generativeai#ai#vectordatabase #pinecone #qdrant #openai
I'm so excited to share 6 new recipes to the @weaviate_io cookbook 👩🍳
1. DSPy (@stanfordnlp): Construct a DSPy agent that designs DSPy agents inspired by the "Automated Design of Agentic Systems" paper.
2. LangChain (@langchain): Build a multi-language RAG by multiple PDFs per tenant with Langchain, OpenAI, and Weaviate.
3. NVIDIA (@NVIDIAAIDev): CAGRA demo with Nvidia’s cuVS
4. Haystack (@Haystack_AI): Learn how to implement query expansion for RAG in Haystack.
5. Composio (@composio): Integrate Composio’s Gmail tool with Weaviate to create an agent that will respond to new messages.
6. Context Data (@1ContextData): Three examples showing you how to ingest data from Google Cloud Storage, Postgres, and S3 into Weaviate.
More on each below. 🥳
https://t.co/oUrafkIg5M
I'm so excited to share 6 new recipes to the @weaviate_io cookbook 👩🍳
1. DSPy (@stanfordnlp): Construct a DSPy agent that designs DSPy agents inspired by the "Automated Design of Agentic Systems" paper.
2. LangChain (@langchain): Build a multi-language RAG by multiple PDFs per tenant with Langchain, OpenAI, and Weaviate.
3. NVIDIA (@NVIDIAAIDev): CAGRA demo with Nvidia’s cuVS
4. Haystack (@Haystack_AI): Learn how to implement query expansion for RAG in Haystack.
5. Composio (@composio): Integrate Composio’s Gmail tool with Weaviate to create an agent that will respond to new messages.
6. Context Data (@1ContextData): Three examples showing you how to ingest data from Google Cloud Storage, Postgres, and S3 into Weaviate.
More on each below. 🥳
https://t.co/oUrafkIg5M
Thank you to @jide_o1 for the recipe!
Context Data is a modular no-code Python framework to embed and ingest data into Weaviate.
Notebook: https://t.co/yUFK90YONV
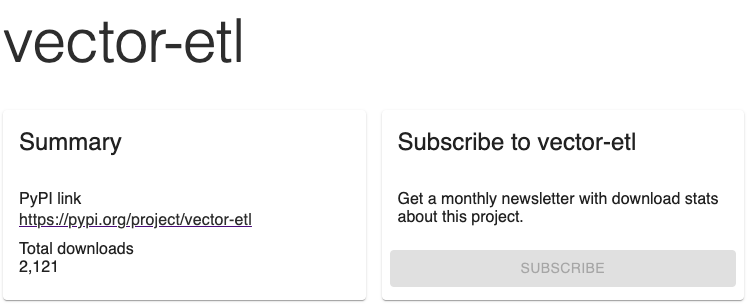
It's been just over 2 weeks since we launched our open source VectorETL and we already have over 2000 downloads and averaging 500 downloads per week. 🌟
Excited for small wins and working hard to make this much bigger in the coming weeks!
Watch out for new updates this week!
#vectordb #vectordatabase #generativeai #openai #pinecone #qdrant #weaviate
We're making data processing and loading for vector databases SUPER EASY ✨
With our new open source VectorETL framework, all you need is a simple YAML (like this image) and you can:
- extract data from multiple sources (e.g. Postgres, MySQL, Salesforce, S3)
- embed the data using top embedding models (e.g. OpenAI, Cohere, Gemini, Hugging face)
- write the embedded data to every major vector database or store (Pinecone, Qdrant, Weaviate, Tembo, Neo4j)
No additional code to write
We're already getting more requests for new integrations and working on pushing a new version in a few days.
#pinecone #vectordatabases #ai #generativeai #qdrant #weaviate
Introducing #VectorETL – a modular no-code ETL framework for vector databases. 🌟
Transform diverse data sources into embeddings effortlessly and write the results to any major vector using just a YAML config file!
Try it out: https://t.co/eNjQHrOpjW
Documentation: https://t.co/OVQNGi8yav
Introducing #VectorETL – a modular no-code ETL framework for vector databases. 🌟
Transform diverse data sources into embeddings effortlessly and write the results to any major vector using just a YAML config file!
See details in comments...
#AI#ETL#VectorSearch #GenerativeAI #VectorDatabase
𝐇𝐨𝐰 𝐰𝐞'𝐫𝐞 𝐭𝐚𝐜𝐤𝐥𝐢𝐧𝐠 𝐚 𝐦𝐚𝐣𝐨𝐫 𝐩𝐚𝐢𝐧 𝐩𝐨𝐢𝐧𝐭 𝐢𝐧 𝐑𝐀𝐆 𝐬𝐲𝐬𝐭𝐞𝐦𝐬: 𝐀𝐜𝐜𝐮𝐫𝐚𝐜𝐲 𝐕𝐞𝐫𝐢𝐟𝐢𝐜𝐚𝐭𝐢𝐨𝐧.
We're proud to announce an upgrade to the Context Data Query Studio – a maker-checker feature where you can add an evaluation model as a 2nd level verification to confirm the accuracy of your original chat model.
𝙾̲𝚗̲𝚎̲ ̲𝚖̲𝚘̲𝚍̲𝚎̲𝚕̲ ̲𝚊̲𝚗̲𝚜̲𝚠̲𝚎̲𝚛̲𝚜̲,̲ ̲𝚊̲𝚗̲𝚘̲𝚝̲𝚑̲𝚎̲𝚛̲ ̲𝚌̲𝚑̲𝚎̲𝚌̲𝚔̲𝚜̲ ̲𝚏̲𝚘̲𝚛̲ ̲𝚊̲𝚌̲𝚌̲𝚞̲𝚛̲𝚊̲𝚌̲𝚢̲!̲
This ensures that the information you receive is not only relevant but also accurate.
𝐁𝐞𝐬𝐭 𝐩𝐚𝐫𝐭 𝐢𝐬 𝐭𝐡𝐚𝐭 𝐲𝐨𝐮 𝐜𝐚𝐧 𝐬𝐞𝐭 𝐭𝐡𝐢𝐬 𝐮𝐩 𝐢𝐧 𝐚𝐬 𝐥𝐢𝐭𝐭𝐥𝐞 𝐚𝐬 𝟏𝟎 𝐦𝐢𝐧𝐮𝐭𝐞𝐬 𝐰𝐢𝐭𝐡𝐨𝐮𝐭 𝐡𝐚𝐯𝐢𝐧𝐠 𝐭𝐨 𝐰𝐫𝐢𝐭𝐞 𝐚𝐧𝐲 𝐜𝐨𝐝𝐞.
Perfect for researchers, analysts, and anyone who values accuracy.
See it in action in our new video.
How could you apply this in your field?
#ArtificialIntelligence #RAG #AI #AIResearch #DataAccuracy #GenerativeAI