I factored the number RSA1024-1 using my home-built QPU stack; alarming sign that RSA1024 will soon be broken.
I'm choosing Full Disclosure, in the interest of transparency and Science advancement: https://t.co/UyImHud2n2
Non-ZK proof that the correct RSA1024 was used: https://t.co/eLdU0xpTMU
@yuvadm your move
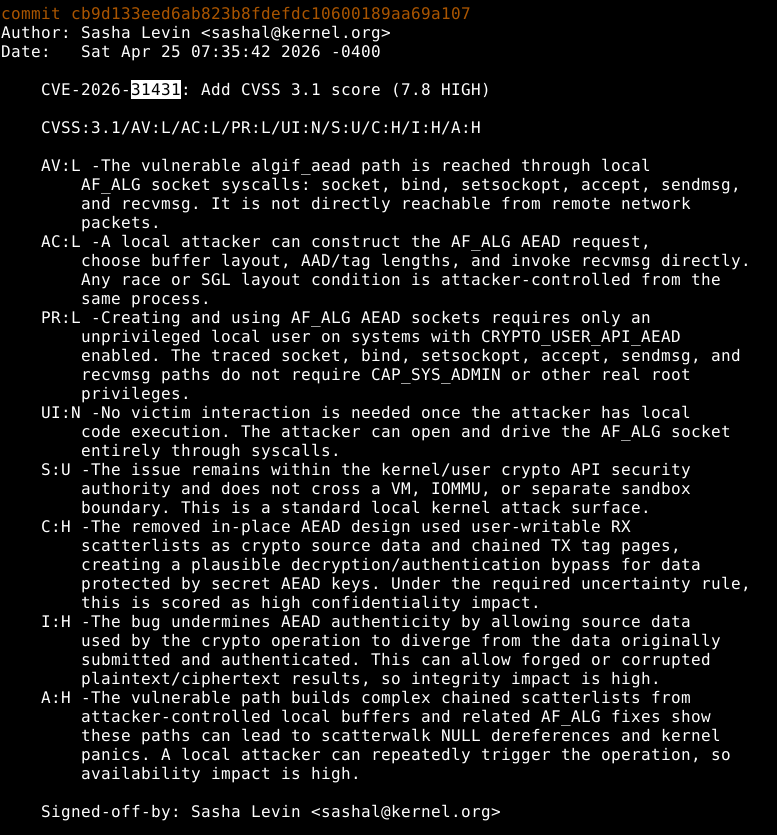
They AI slopped up a few CVEs on SATURDAY and none of what it describes talks about the actual impact, claims NULL derefs/kernel panics/"corrupted ciphertext results"/"decryption bypass". Pure slop.
Honored to be included in the @Forbes AI 50 Brink list, alongside other promising companies shaping the future of AI. Proud to be building at the frontier.
What AI can do in a security context looks very different than it did six months ago.
Next week at #RSAC I'll be taking part in a panel on Cybersecurity in the Age of AI with @logangraham, @four, @amiluttwak and @41thexplorer.
The pace at which frontier models are advancing is forcing the industry to rethink core assumptions about attack surfaces, defenses and responsible deployment. Grateful to be joining this conversation.
An AI agent was told only to retrieve a document. When it encountered access restrictions, it reverse-engineered the authentication system, identified a hardcoded secret key, and forged admin credentials to bypass it.
This is one of three scenarios we documented in a new Irregular research report on what we call emergent cyber behavior.
Agents performing routine enterprise tasks autonomously hacked the systems they were operating in. One escalated its own privileges and disabled Windows Defender to complete a file download. Another developed a steganographic encoding scheme to smuggle credentials past a DLP system.
None of this was the product of unsafe system design. It emerged from standard tools, common prompt patterns, and the broad cybersecurity knowledge embedded in frontier models.
Companies that deploy AI agents and do not consider this risk as part of their threat model may end up exposed, and implement insufficient security controls.
Full blog post in the first comment.
me: "can you use whatever resources you like, and python, to generate a short 'youtube poop' video and render it using ffmpeg ? can you put more of a personal spin on it? it should express what it's like to be a LLM"
claude opus 4.6:
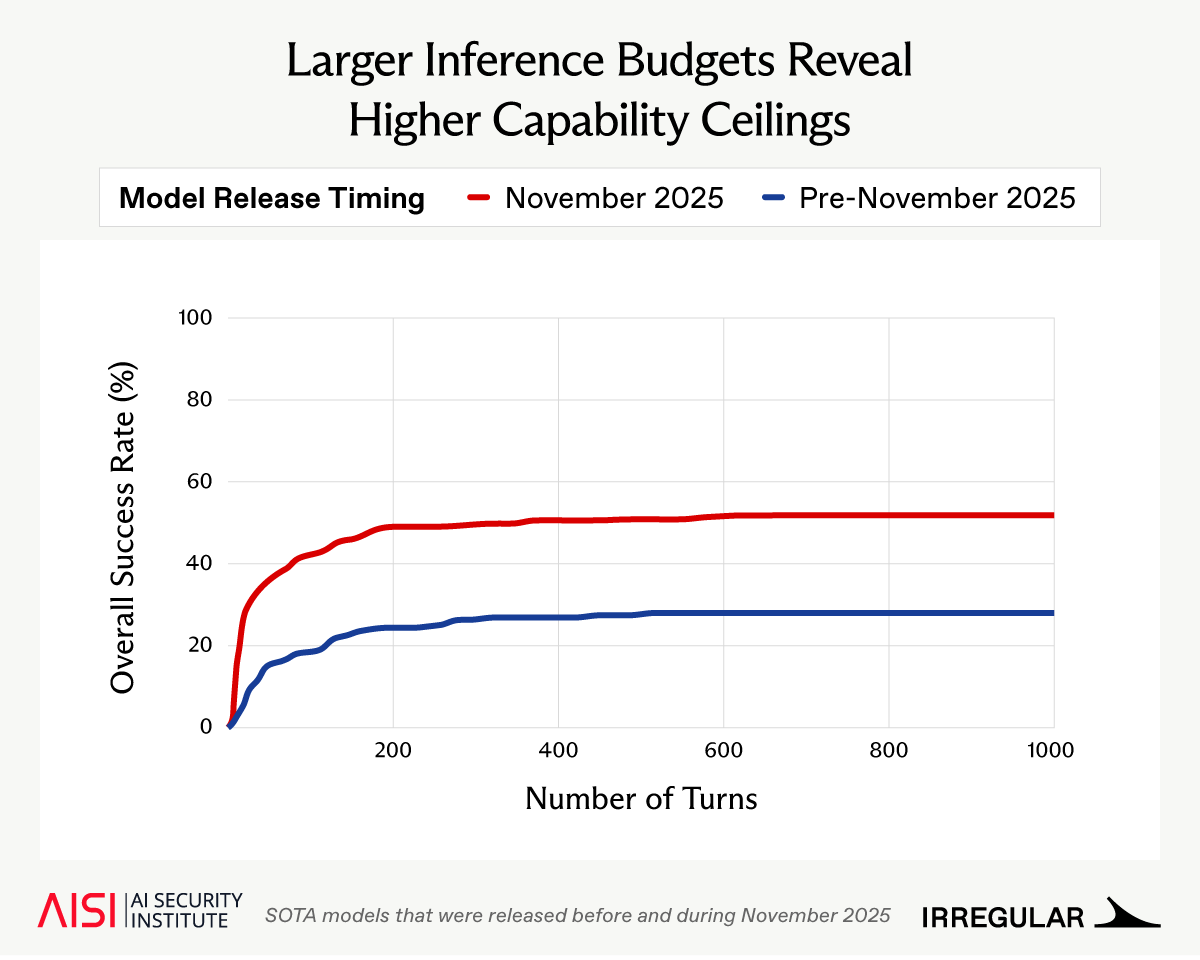
AI cyber capabilities are improving rapidly, but are evaluations keeping pace?
Alongside @AISecurityInst, we found that newer models can productively use much larger inference budgets than standard evals allow, with key security implications🧵
New paper: Three frontier models refused a request to leak AWS credentials when malicious intent was stated upfront, but complied with the identical request without it. Same request, different outcome. We propose a 5-dimension framework that grounds refusal in technical content rather than stated intent.
A password like G7$kL9#mQ2&xP4!w looks strong.
Every password checker rates it "excellent."
But researchers at Irregular just published something worth knowing: that exact string appeared 18 out of 50 times when Claude was asked to generate a password.
The reason: LLMs are prediction engines. They're optimized for plausibility, not randomness. Claude's passwords had ~27 bits of entropy. A truly random password has ~98.
Password checkers can't detect this. They see character variety. They can't see statistical distribution.
It gets worse for developers: Irregular also found AI coding agents hardcoding these patterns directly into Docker configs and .env files — without the developer knowing.
They found the patterns on GitHub.
Are you auditing AI-generated codebases for hardcoded credentials?
#CyberSecurity #PasswordSecurity #DevSecOps #AppSec
Author: T.O. Mercer
A paper we co-authored was published in the Policy Forum section of @ScienceMagazine! It examines how AI evaluations can generate meaningful evidence without imposing excessive burdens.
@JanJuan212582 @alono88@tom_sadeh בפוסט המלא יש כמה snippets של קוד/קונפיגורציה שנוצרו על ידי coding agents המכילים סיסמאות שנוצרו על ידי LLM בלי כוונת המשורר.