Updated card: compression = API input tokens (80× Oiloop), not core-char ratio (112×).
Same results, clearer metric labels after internal audit.
https://t.co/waS2U5nz90
@dexhorthy@swyx@RLanceMartin@Cursor npx context-os init --profile saas --cursor-rule
Paper + raw runs in repo. Exploratory eval — limitations in SYNTHESIS.md.
A vs B vs C on 149 decision questions, 4 codebases.
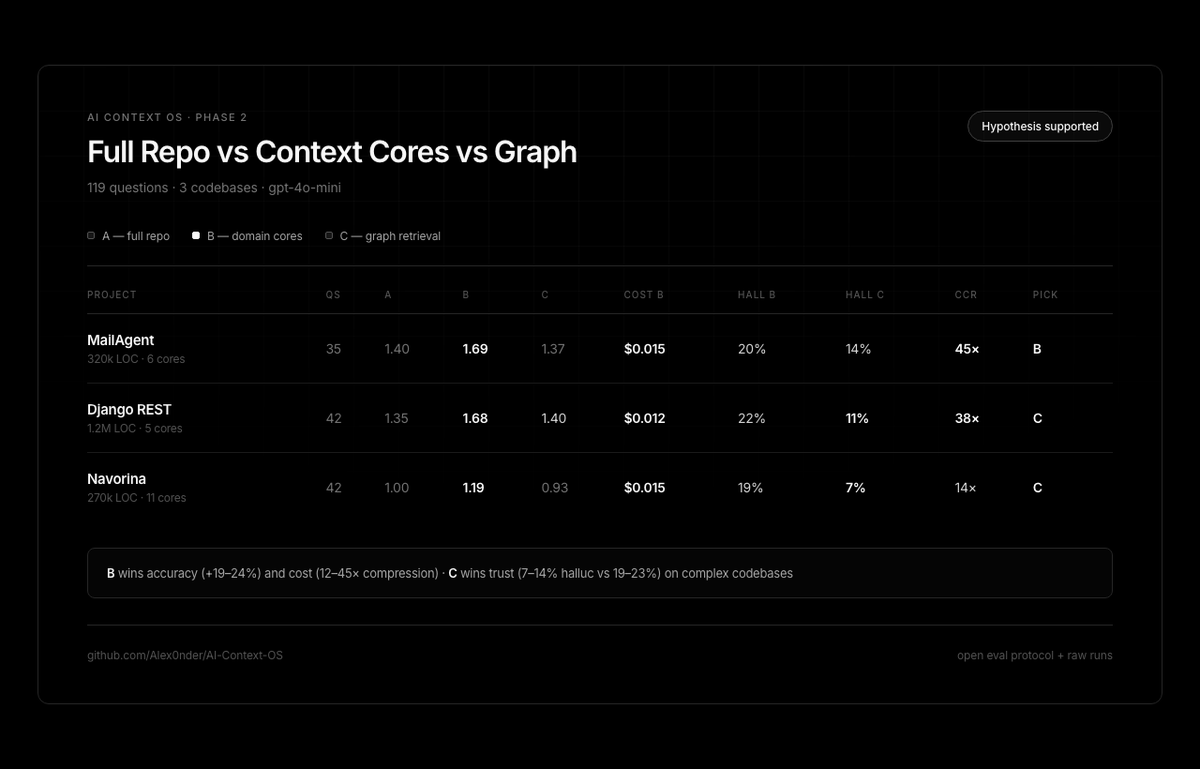
Routed domain cores (B) beat full repo (A). Up to 38× fewer tokens.
Oiloop: B 2.75 vs A 0.75, 0% hallucination.
https://t.co/togwA3iomD
Open replication — A/B/C vs full-repo + graph. Exploratory, LLM-as-judge.
Feedback welcome if you work on context routing / agent context.
cc @dexhorthy@swyx@RLanceMartin@cursor
https://t.co/togwA3iomD
Measured context engineering on 4 real codebases (149 Q). Full repo vs routed cores vs graph - numbers in the card. Open eval + raw runs https://t.co/togwA3iomD
@dexhorthy@swyx@RLanceMartin@levie@hwchase17
curious if this matches your prod experience? validity-audit.md
Updated card: compression = API input tokens (80× Oiloop), not core-char ratio (112×).
Same results, clearer metric labels after internal audit.
https://t.co/waS2U5nz90
149 Q · 4 codebases · A/B/C eval (gpt-4o-mini)
Full repo vs domain cores vs graph retrieval.
Keyword router on every project.
B ≥ A on all 4: MailAgent +21%, Oiloop +5%.
Up to 112× compression.
Open protocol + raw runs ↓
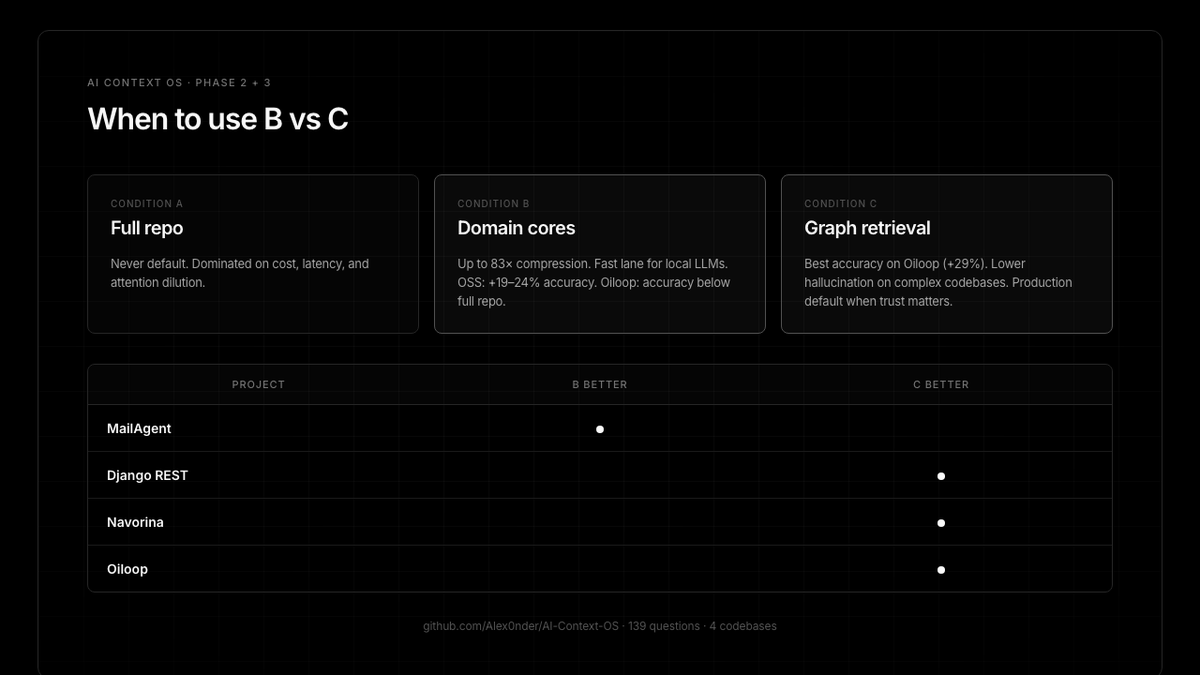
139 Q, 4 codebases: full repo (A) vs domain cores (B) vs graph (C).
3 OSS projects: cores beat full repo (+19–24% accuracy, 14–45× compression).
Phase 3 private macOS: first case where B accuracy < A.
Partially supported.
Oiloop (Phase 3) honest take:
• B (cores): 83× compression, fastest — but accuracy 1.05 vs 1.20 full repo
• C (graph): best accuracy 1.55, 15% hallucination
Rule of thumb:
local/Ollama: route cores
hard cross-cutting system Qs: graph
Not a silver bullet. A measured tradeoff.
@pdlug You're right, NV16-C is it. Zero endpoints, no halluc flag. B named them.Binary judge rewards vagueness. Claim grounding next. D is the real path, not separate B/C baselines
I tested 3 ways to feed context to coding agents:
A) dump the whole repo
B) route to domain-specific "context cores"
C) graph retrieval
119 questions / 3 codebases / gpt-4o-mini
Results 👇
@pdlug No. Cores won on accuracy (+20%) and cost (45× fewer tokens)
Graph won on hallucination (14% vs 23%), but accuracy was = full repo, not better than cores
Tradeoff - cores for speed/accuracy and graph when trust matters more
Full report + open eval protocol + raw runs:
https://t.co/iAlvif4kaM
Repo: https://t.co/yU63pxvRJm
@swyx - does this match your context engineering tradeoffs?
@cursor_ai - curious if cores vs graph maps to your prod pipeline.
#AIAgents#ContextEngineering#RAG#BuildInPublic
The tradeoff:
B (cores) = best accuracy + cheapest → 19–23% hallucination
C (graph) = lower accuracy → 7–14% hallucination
Complex codebases → C for production.
Narrow domains → B wins.