Introducing "GenRep" w/@xavierpuigf,@YonglongT,@phillip_isola
TL;DR: Visual representations can be learned by aligning multiple ‘views’ of training data; we show how GANs can be used to generate these views synthetically, yielding effective visual reps
https://t.co/XjDeIegPgE
"The Truth Lies Somewhere in the Middle (of the Generated Tokens)"
In autoregressive language models, mean pooling hidden states across generation yields better representations than any token alone.
project page: https://t.co/kXddYUir4k
w/ @phillip_isola and @thisismyhat
LLMs can learn to self-generate curricula for hard problems that they can't yet solve! Using meta-RL, with rewards grounded in learning progress, models produce their own stepping stones that kickstart learning on hard problems where direct RL plateaus.
Poster at the ICLR RSI workshop today!
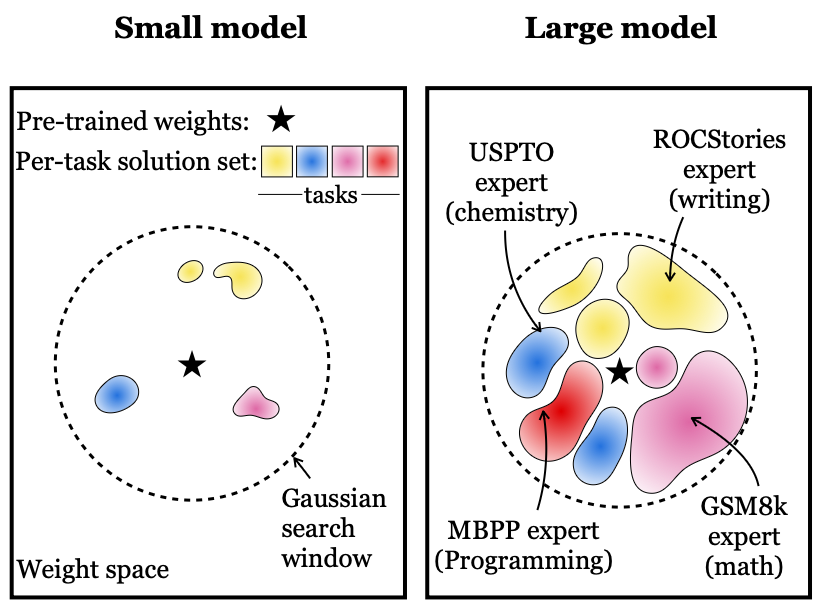
Sharing “Neural Thickets”. We find:
In large models, the neighborhood around pretrained weights can become dense with task-improving solutions.
In this regime, post-training can be easy; even random guessing works
Paper: https://t.co/qlXEkJHSZa
Web: https://t.co/xYoYctEqHn
1/
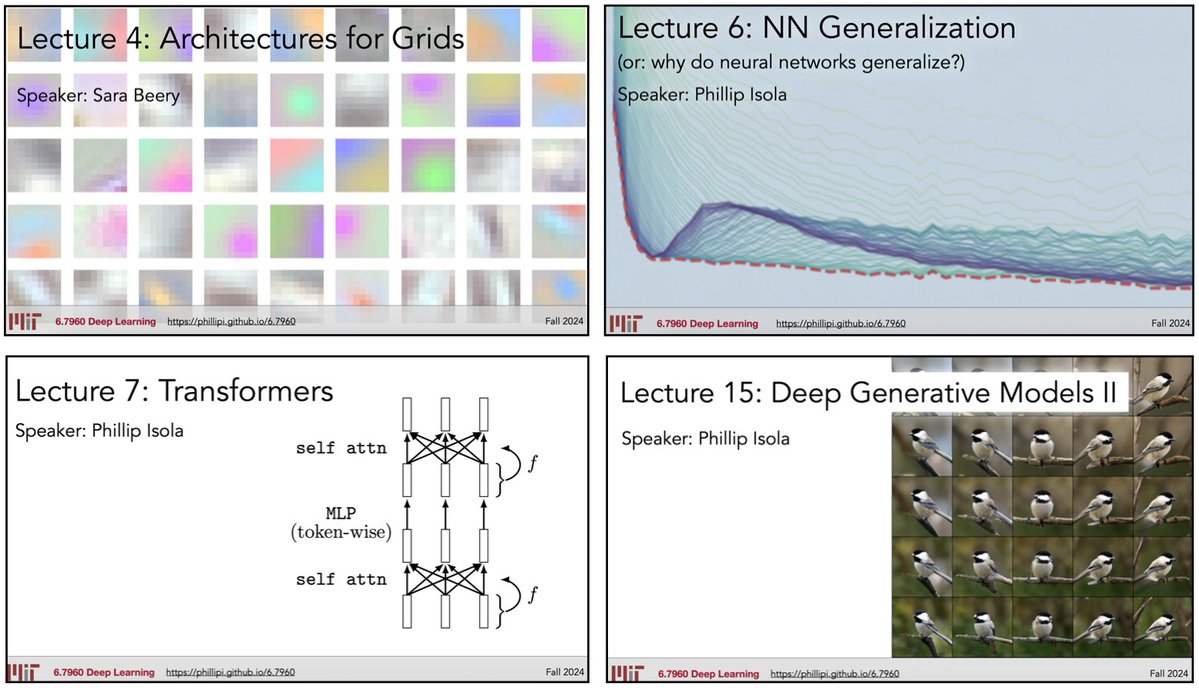
Our grad-level "Deep Learning" course (MIT's 6.7960) is now freely available online through OpenCourseWare: https://t.co/gnGFbzlINf
Lecture videos, psets, and readings are all provided.
Had a lot of fun teaching this with @sarameghanbeery and @jxbz!
Amazing test of Gemini 3’s multimodal reasoning capabilities: try generating a threejs voxel art scene using only an image as input
Prompt: I have provided an image. Code a beautiful voxel art scene inspired by this image. Write threejs code as a single-page
Phillip Isola studies how intelligent machines “think” and perceive the world, to ensure AI is safely integrated into human society. “I see all the different kinds of intelligence as having a lot of commonalities, and I’d like to understand those commonalities,” he says. https://t.co/6RFSptdfFb
Since she's way too shy to post this herself, please join me in congratulating my amazing colleague and friend @klbouman for receiving tenure at @caltech! 🥳🎉
🎓 Amazon launches AI PhD Fellowship program, providing $68 million over two years to fund PhD students at 9 universities pursuing research in machine learning, computer vision, and natural-language processing. #AmazonAIFellowship https://t.co/B7IvORGu5K
Andrew Owen’s (@andrewhowens) talk on
Point Prompting: Counterfactual Tracking with Video Diffusion Models
is happening at curated data for efficient learning workshop!
Room: 304A
@cdel_workshop@ICCVConference
Excited to announce @amazon's new AI PhD Fellowship Program supporting 100+ students across 9 universities like Carnegie Mellon, MIT & Stanford. Fellows will be paired with senior scientists working in related fields, plus receive financial support and AWS credits for research. Learn more: https://t.co/KNTcYI83Gm
At ICCV: at 11am I will give a talk in room 309 "On the perceptual distance between images and text."
This one will cover CycleReward.
I will share talk slides after.
If you are at ICCV, I'm giving a talk here at 3:30pm in Ballroom B on "Revisiting the symbol grounding problem in the age of multi-modal AI"
Will cover recent work on multimodal rep alignment in unpaired and unimodal models.
When exploring ideas with generative models, you want a range of possibilities. Instead, you often disappointingly get a gallery of near-duplicates.
The culprit is standard I.I.D. sampling. We introduce a new inference method to generate high-quality and varied outputs.
1/n
Announcing a deep net interpretability talk series!
Every week you will find new talks on recent research in the science of neural networks. The first few are posted: @jack_merulllo_, @RoyRinberg, and me.
At the @ndif_team Youtube Channel: https://t.co/xDG778qrD5.
From GPT to MoE: I reviewed & compared the main LLMs of 2025 in terms of their architectural design from DeepSeek-V3 to Kimi 2.
Multi-head Latent Attention, sliding window attention, new Post- & Pre-Norm placements, NoPE, shared-expert MoEs, and more...
https://t.co/oEt8XzNxik
We are hiring on the Veo team!📽️
Some people asked me about this at #ICML2025. If that's you, I will have told you to check https://t.co/w9gTOJiCI4 regularly.
👀It's just been updated:
Europe (London, Zurich) https://t.co/2My3Fcztup
US (Mountain View) https://t.co/1HurWZ7AW3