The AI puzzle: As AI talks more like us, are we starting to think more like it? Discover #LLMorphism – the mistaken belief that human thinking is like an LLM. #AI#Cognition#Psychology#HumanAI https://t.co/SJMF7MlY04
The best enterprise agents in 2026 use a 3-layer stack:
1️⃣ Skills (Domain Knowledge)
2️⃣ MCP (Secure Connectivity)
3️⃣ CLI (Token-Efficient Execution)
Stop overloading your LLM. Read the full architecture breakdown here:
https://t.co/JfUjkU7TG4
First systematic map of "AI Agent Traps" adversarial web content engineered to hijack autonomous agents. 6 attack classes targeting every layer of an agent's operating cycle: How to Defend Against AI Agent Traps: #ai#agents#Security https://t.co/0Oy9GzpJ3E
How much budget did you actually approve for your Agentic AI strategy? Not the roadmap. Not the slide deck. The actual signed check. That number tells you everything. #AIStrategy#EnterpriseAI#AgenticAI#AI#Leader
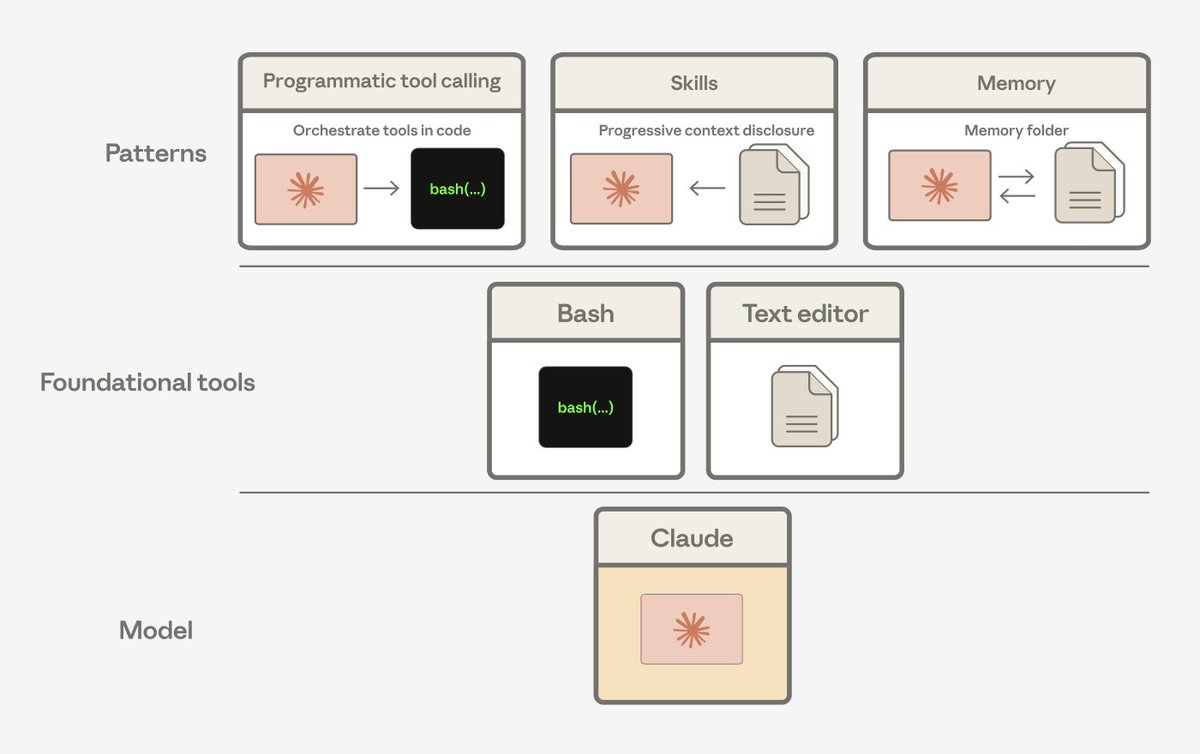
i just published a short article on building applications w/ Claude. captures a few lessons from my own work and many discussions with others at Anthropic.
https://t.co/VYnSSGwDet
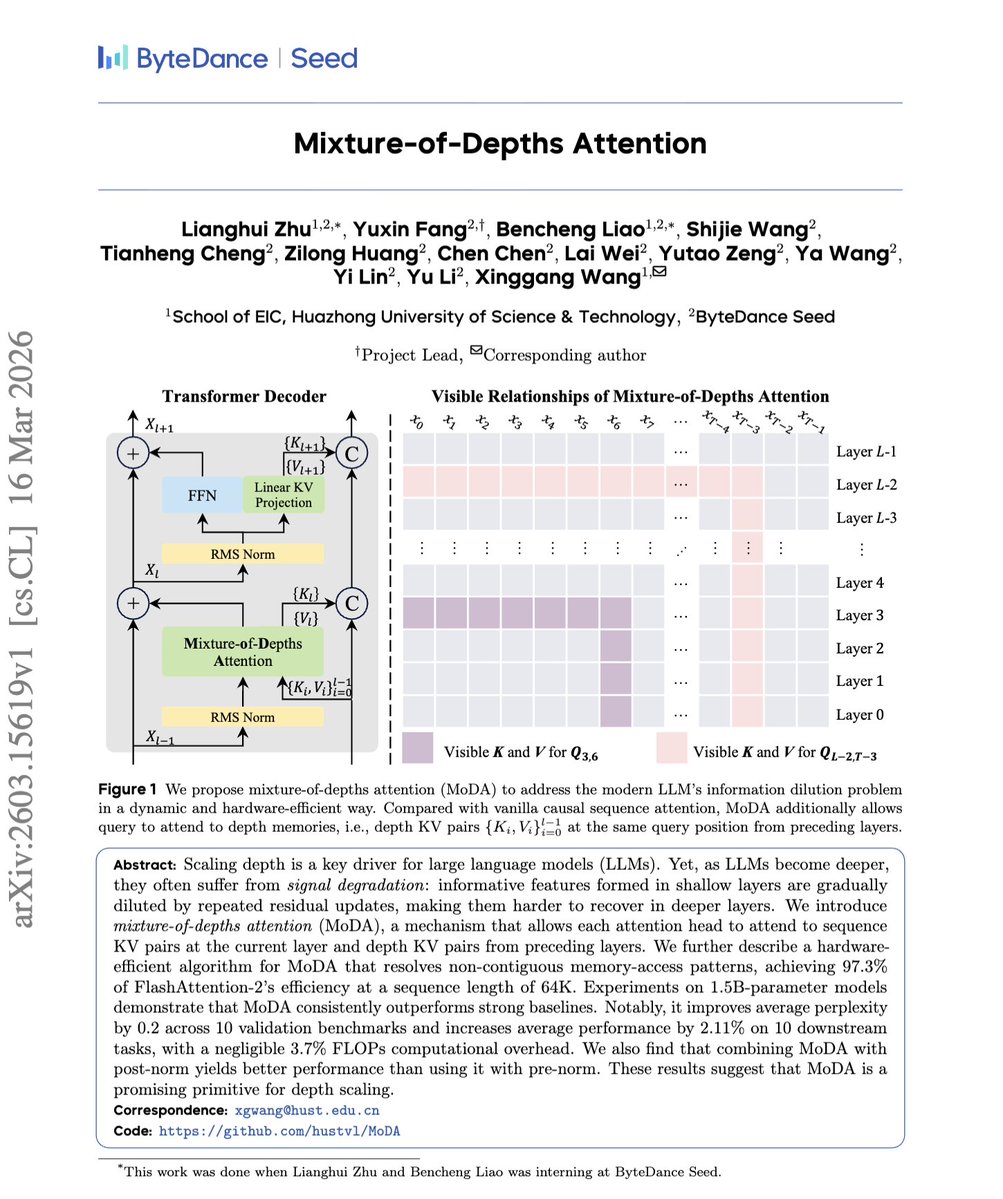
"Mixture-of-Depths Attention"
This paper teaches a Transformer to attend not just across tokens, but also to depth KV from its earlier layers.
That helps recover shallow-layer signals that standard residual stacking tends to dilute, improving performance with only a small extra compute cost.
Similar idea to Kimi’s Attention Residuals, but MoDA modifies the attention module itself, while AttnRes changes the residual/depth aggregation path.
Expectation: the age of the IDE is over
Reality: we’re going to need a bigger IDE
(imo).
It just looks very different because humans now move upwards and program at a higher level - the basic unit of interest is not one file but one agent. It’s still programming.