Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
Artículo muy interesante de Anthropic sobre como gracias a la IA están pudiendo agilizar su proceso de investigar y entrenar mejor IA.
O como coloquialmente se le llama: cerrando el bucle
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
El antigravity es uno de los peores fracasos de productos de google
lo hicieron gratis y aún no puede competir con Cursor, Codex, Claude Code
la calidad vence a lo gratis, todas y cada una de las veces
Este proyecto te permite tener AWS en local y gratis.
Sin cuentas ni trucos. Perfecto para practicar.
Se llama Floci y tiene 47 servicios: S3, SQS, Lambda, DynamoDB, RDS...
https://t.co/7RwMy6rjFQ
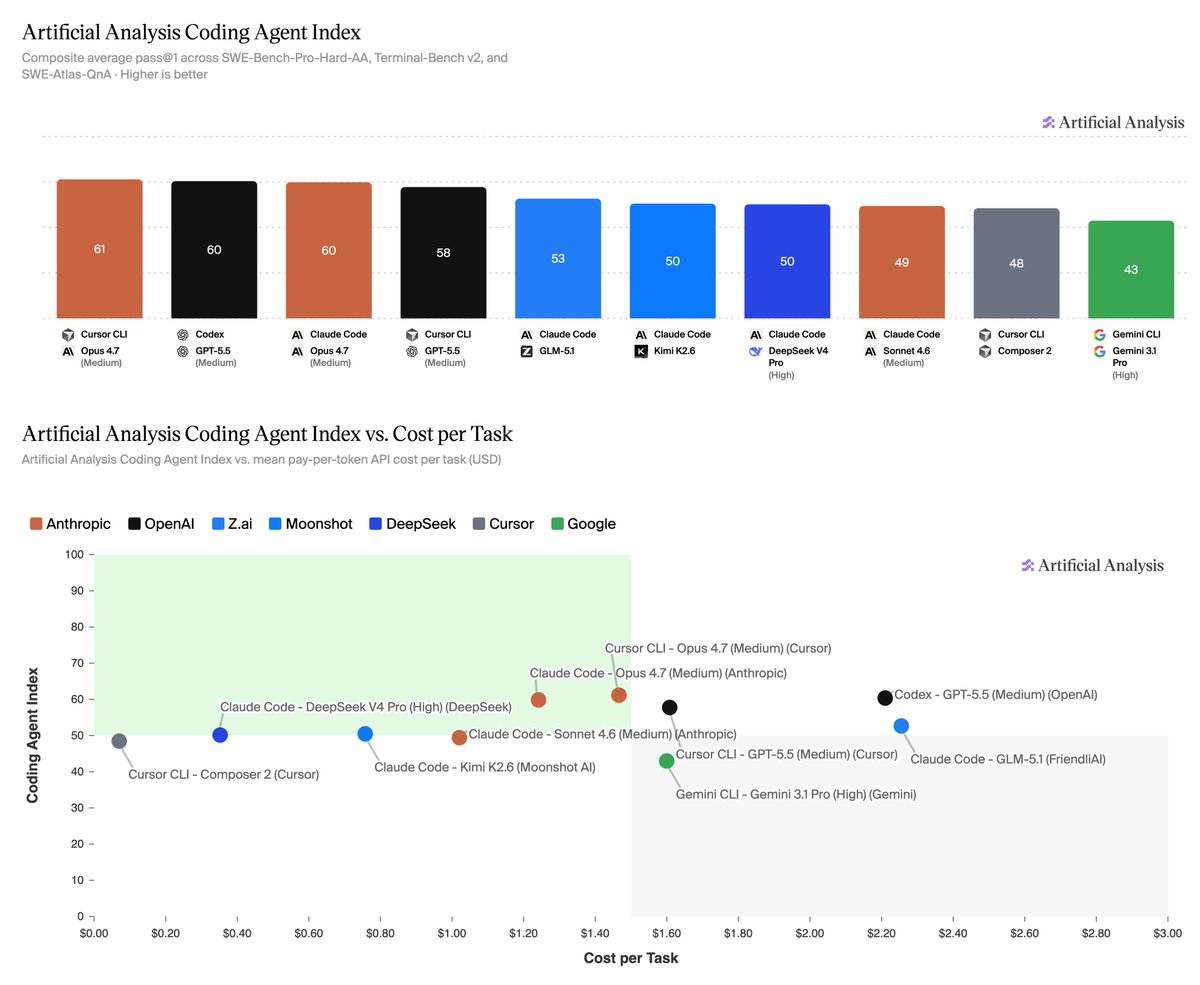
Announcing the Artificial Analysis Coding Agent Index! Our new coding agent benchmarks measure how combinations of agent harnesses and models perform on 3 leading benchmarks, token usage, cost and more
When developers use AI to code they’re choosing a model, but also pairing it with a specific harness. It makes sense to benchmark that combination to understand and compare performance.
The Artificial Analysis Coding Agent Index includes 3 leading benchmarks that represent a broad spectrum of coding agent use:
➤ SWE-Bench-Pro-Hard-AA, 150 realistic coding tasks that frontier models struggle with, sampled from Scale AI’s SWE-Bench Pro
➤ Terminal-Bench v2, 84 agentic terminal tasks from the Laude Institute and that range from system administration and cryptography to machine learning. 5 tasks were filtered due to environment incompatibility
➤ SWE-Atlas-QnA, 124 technical questions developed by Scale AI about how code behaves, root causes of issues, and more, requiring agents to explore codebases and give text answers
Analysis of results:
➤ Opus 4.7 and GPT-5.5 lead the Index: Opus 4.7 in Cursor CLI scores 61, followed closely by GPT-5.5 in Codex and Opus 4.7 in Claude Code at 60. GPT-5.5 in Cursor CLI follows at 58.
➤ Open weights models are competitive, but still trail the leaders: GLM-5.1 in Claude Code is the top open-weight result at 53, followed by Kimi K2.6 and DeepSeek V4 Pro in Claude Code at 50. These are strong results, but still meaningfully behind the top proprietary models.
➤ Gemini 3.1 Pro in Gemini CLI underperforms: Gemini 3.1 Pro in Gemini CLI scores 43, well below where Gemini 3.1 Pro sits on our Intelligence Index, highlighting that Gemini’s performance in Gemini CLI remains a relative weak spot for Google’s offering.
➤ Cost per task (API token pricing) varies >30x: Composer 2 in Cursor CLI is cheapest at $0.07/task, followed by DeepSeek V4 Pro in Claude Code at $0.35/task and Kimi K2.6 in Claude Code at $0.76/task. At the high end, GPT-5.5 in Codex costs $2.21/task, while GLM-5.1 in Claude Code costs $2.26/task. For both models this was contributed to by high token usage, and in GPT-5.5’s case by a relatively higher per token cost.
➤ Token usage varies >3x: GLM-5.1 in Claude Code uses the most tokens at 4.8M/task, followed by Kimi K2.6 at 3.7M/task and DeepSeek V4 Pro at 3.5M/task. GPT-5.5 in Codex uses 2.8M tokens/task, substantially more than Opus 4.7 in Claude Code at 1.7M/task. In GLM-5.1’s case, higher token usage, cost and execution time were partly driven by the model entering loops on some tasks.
➤ Cache hit rates remain high but vary materially: Cache hit rates range from 80% to 96% across combinations. Provider routing, harness prompt structure and cache behavior can materially change the economics of running the same model given cached inputs are typically <50% the API price of regular input tokens.
➤ Time per task varies >7x: Opus 4.7 in Claude Code is fastest at ~6 minutes/task, while Kimi K2.6 in Claude Code is slowest at ~40 minutes/task. This is contributed to by differences in average turns per task, token usage and API serving speed. Opus 4.7 had materially lower amount of turns to complete a task than all other models while Kimi K2.6 had the most.
➤ Cursor made real progress with Composer 2: Composer 2 in Cursor CLI scores 48, near the leading open-weight model results, while being the cheapest combination measured at $0.07/task. Cursor has stated Composer 2 is built from Kimi K2.5, showcasing they have made substantial post-training gains.
This is just the start. We are planning to add additional agents (both harnesses and models). Let us know what you would like to see added next.
arXiv Papers → LLM Artifacts
This is how I keep up with AI research now.
It's like having access to the most personalized arXiv feed.
Automations run everyday to curate papers based a set of rules and insights.
Curated papers are indexed and power the artifacts.
Agent convert papers to LLM wikis (based on @karpathy idea), which means insights are indexed and easily searchable and reusable.
I feel like LLM Artifacts is the natural evolution to LLM Wikis. It's about making that knowledge actionable.
Artifacts are customizable via agents. Artifacts can interact with agents and are dynamic in nature. Anything can be injected into the artifact as needed (insights, components, suggested experiments, action items, etc).
I can take action on Artifact items with my agent orchestrator (Electron app).
So I can ask questions about any paper and automate experiments in the background right from within the artifact.
This is more than a visual. It's not a single prompt. It's several proactive agents coordinating to surface interesting facts, knowledge, and insights that I can act on a researcher.
Agents are not just for generating useful artifacts, they are useful to keep learning and staying on the cutting edge of knowledge. Stay tuned for more.
Introducing MMX-CLI — our first piece of infrastructure built not for humans, but for Agents.
Your Agent can read, think, and write. But ask it to sing, paint, or show you a world it's never seen — and it falls silent. Not because it doesn't understand, but because it has no mouth, no hands, no camera. Today, that changes.
MMX-CLI gives every Agent seven new senses — image, video, voice, music, vision, search, conversation — powered by MiniMax's full-modal stack, today's SOTA across mainstream omni-modal models.
One command: mmxAgent-native I/O. Zero MCP glue. Runs on your existing Token Plan.
Two lines to give your Agent a voice:
npx skills add MiniMax-AI/cli -y -g
npm install -g mmx-cli
Then tell it: "you have mmx commands available."
It'll learn the rest.
Github → https://t.co/fSRc5Lo30j
Token Plan:
https://t.co/BDCycxepZw
Google has released Gemma 4, a new family of multimodal open-weight models including Gemma 4 E2B, Gemma 4 E4B, Gemma 4 31B and Gemma 4 26B A4B
@GoogleDeepMind’s new Gemma 4 family introduces four multimodal models supporting text, image, and video inputs. We evaluated Gemma 4 31B (dense) and Gemma 4 26B A4B (MoE), both with a 256k context window, while the other two smaller models support up to 128k. With 31B and 26B parameters respectively, both evaluated models can run on a single H100.
On GPQA Diamond, our scientific reasoning evaluation, Gemma 4 31B (Reasoning) scores 85.7%, the second highest result we have recorded for an open-weights model with fewer than 40B parameters, just behind Qwen3.5 27B (Reasoning, 85.8%). It reaches this score using only ~1.2M output tokens, fewer than Qwen3.5 27B (~1.5M) and Qwen3.5 35B A3B (~1.6M). Gemma 4 26B A4B (Reasoning) scores 79.2%, ahead of gpt-oss-120B (high, 76.2%) but behind Qwen3.5 9B (Reasoning, 80.6%).
We are now running the Artificial Analysis Intelligence Index on all four Gemma 4 models and will share a full update once those results are complete.
Building a personal knowledge base for my agents is increasingly where I spend my time these days.
Like @karpathy, I also use Obsidian for my MD vaults.
What's different in my approach is that I curate research papers on a daily basis and have actually tuned a Skill for months to find high-signal, relevant papers.
I was reviewing and curating papers manually for some time, but now it's all automated as it has gotten so good at capturing what I consider the best of the best. There are so many papers these days, so this is a big deal.
You all get to benefit from that with the papers I feature in my timeline and on @dair_ai.
The papers are indexed using @tobi qmd cli tool (all of it in markdown files along with useful metadata). So good for semantic search and surfacing insights, unlike anything out there.
I am a visual person, so I then started to experiment with how to leverage this personal knowledge base of research papers inside my new interactive artifact generator (mcp tools inside my agent orchestrator system). The result is what you see in the clip.
100s of papers with all sorts of insights visualized. I keep track of research papers daily, so believe me when I tell you that this system is absolutely insane at surfacing insights. This is the result of months of tinkering on how to index research and leverage agent automations for wikification and robust documentation.
But this is just the beginning. The visual artifact (which is interactive too) can be changed dynamically as I please. I can prompt my agent to throw any data at it. I can add different views to the data. Different interactions. I feel like this is the most personalized research system I have ever built and used, and it's not even close.
The knowledge that the agents are able to surface from this basic setup is already extremely useful as I experiment with new agentic engineering concepts. I feel like this knowledge layer and the higher-level ones I am working on will allow me to maximize other automation tools like autoresearch. The research is only as good as the research questions. And the research questions are only as good as the insights the agents have access to.
Where I am spending time now is on how to make this more actionable. I am obsessed about the search problem here. The automations, autoresearch, ralph research loop (I built one months ago) are easier to build but are only as good as what you feed them.
Work in progress. More updates soon. Back to building.
Been exploring a new way to explore AI research papers to discover deeper insights.
Agents are at the center of it.
So far, I've built this little interactive artifact generator in my orchestrator to visualize things.
This allows me to change views and insights (on-demand) from 100s of papers.
Just scratching the surface here. More to share soon.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
🔴 ¡GOOGLE LIBERA GEMMA 4!
Cuatro versiones abiertas muy interesantes:
👉 31B Dense y 26B MoE: rendimiento equivalente a alternativas más grandes en tamaños muy accesibles!
👉 E4B y E2B: ligeros con procesamiento en tiempo real de texto, visión y audio!
https://t.co/S929Q159Ln
Hemos pasado del 2025 del human-in-the-loop y el vibe coding a estar en 2026 con Karpathy sintiéndose el cuello de botella que limita el trabajo de la IA, y con nuevos conceptos como human-out-of-the-loop y blind coding.
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
https://t.co/WAz8aIztKT
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.