When we first conceptualized SWE-bench in the summer of 2023, the driving question was "What do software engineers really do and how do we measure LLMs on those tasks?" (this was back when HumanEval was the standard coding benchmark, testing models on simply code generation)
Fast forward to now and both the models and the SWE role have leveled up significantly -- software engineers now spend a lot more time on understanding requirements, tasteful design and validating solutions than writing actual code. And Senior SWE-bench is designed to push those limits even further by testing modern SWE agents on tackling such underspecified problems and evaluating them for both correctness and taste.
Be sure to read @henryehrenberg 's excellent blog articles (https://t.co/zGVbI43BnL) on the various design choices as well as an analysis of the first round of results!
We expect agents to act like senior engineers, but most benchmarks still evaluate them like interns.
Excited to introduce Senior SWE-Bench, an open-source and @harborframework-native benchmark that assesses agents as senior engineers on long-horizon tasks with realistically under-specified instructions.
We expect agents to build real features going on just a quick Slack message, nothing like the super technical instructions most benchmarks provide. Senior SWE-Bench fixes that.
Claude Opus 4.8 is the current leader at 24% high quality solves, but it took 117K tokens on average to get there. Claude Sonnet 5 looked like it was going to swoop in for the top spot, but we found it cheated on 26% of trials.
We expect agents to act like senior engineers, but most benchmarks still evaluate them like interns.
Excited to introduce Senior SWE-Bench, an open-source and @harborframework-native benchmark that assesses agents as senior engineers on long-horizon tasks with realistically under-specified instructions.
We expect agents to build real features going on just a quick Slack message, nothing like the super technical instructions most benchmarks provide. Senior SWE-Bench fixes that.
Claude Opus 4.8 is the current leader at 24% high quality solves, but it took 117K tokens on average to get there. Claude Sonnet 5 looked like it was going to swoop in for the top spot, but we found it cheated on 26% of trials.
OSWorld 2.0 measures long-horizon computer use with 108 workflows, ~1.6 human-hours and ~250+ steps each
lots of headroom on the pareto frontier - Opus 4.8 scores 20.6% (w/ ~224K tokens/task)
work led by @yuan_mengq43669@taoyds & @XLangNLP group - we @SnorkelAI were honored to collaborate as research / data partners!
108 real-world, long-horizon computer-use workflows. Average rollout: 318 tool calls.
Top frontier agent (Claude Opus 4.8 with max thinking + batched tool calls): 20.6% end-to-end completion (54.8% partial progress). Partial progress is real. Reliable end-to-end computer use is not.
Proud to be @XLangNLP's research and data partner on OSWorld 2.0. @qi_zhengyang, @vincentsunnchen, and @fredsala contributed from Snorkel.
New Benchtalks with @jyangballin: on ProgramBench (0% frontier models at launch) and the lineage/future of coding benchmarks, from SWE-bench/InterCode to now
01:29 ProgramBench launch and reception
03:41 Why artifact-level evaluation, not code-level
06:03 Why models love Python
08:29 ProgramBench as a research tool
12:45 From SWE-bench & InterCode to ProgramBench
17:47 How to grade a coding model
21:53 The position paper & humans in the loop
25:01 Managing quality with agents-in-the-loop
28:40 Internet access and benchmark integrity
35:26 Where models may surpass human abilities
38:56 When a model hits 80% on ProgramBench
43:55 Benchmarks worth paying attention to
46:24 What benchmark do you wish existed
49:32 Will benchmarks still look like benchmarks in 5 years
52:02 How to contribute to ProgramBench
More evidence that at least for now, multi-agent systems don't solve anything that single-agent systems can't, they just get to the same results faster.
I do think this could change in the future, but for now multi-agent systems aren't any more powerful than single-agent ones.
Huge congrats to @JonSaadFalcon, @Avanika15, and the whole @HazyResearch team on launching @OpenJarvisAI!
OpenJarvis is a personal AI that lives and runs on your own devices. It learns from you, handles your tasks privately, and only calls the cloud when it really needs extra power.
This builds on their earlier Minions work, which is a clever way for small local AI models to team up with big cloud models. The local model reads your long documents and does most of the work, while the cloud model only helps with the hard parts. That idea has been one of the most interesting threads in making personal AI practical and affordable.
Super glad @SnorkelAI got to support the multi-objective evaluation work along the way. Excited to see what people build with it!
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
https://t.co/MSPMwnbhVt
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
We need better benchmarks for scientific AI with real workflows and complex tasks.
That's exactly what @StevenDillmann and the Terminal-Bench Science team are building with @harborframework, and our team @SnorkelAI is proud to support it.
They're accepting task contributions now. If you do computational science, get involved 👇
Attending #MLSys? Our research team will be there in full swing. Come join us for an event in #Seattle / #Bellevue! We'd love to connect. https://t.co/ycmGkqEjod
Coding agents have moved from tab-complete to teammate.
A model suggesting code one line at a time is easy to review. An agent autonomously refactoring your repo and testing its own changes is much harder.
Agentic evaluation is the critical bottleneck now. Benchmarks have to be agentic too — multi-step, executable, and scored across the whole trajectory.
New blog: https://t.co/f9KrDC8iu4
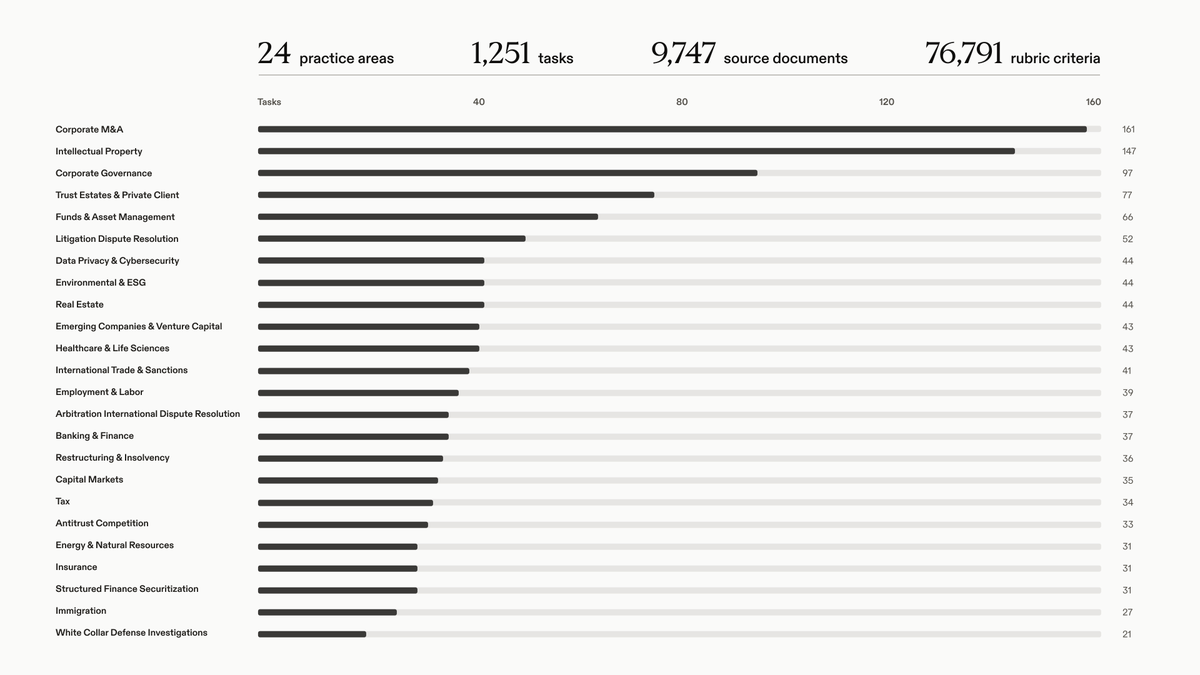
We're honored @SnorkelAI to be research partners on Legal Agent Benchmark (LAB) from @harvey: over 1,200 tasks and 75,000 rubrics, driven by experts across 24 legal practice areas.
Very excited for the leap towards long-horizon evals grounded in real legal expertise. Congratulations to @nikogrupen, @ItsJulioPereyra, @gabepereyra and team!
Excited to share Continual Learning Bench 1.0: a collab between our research team and @pgasawa's lab at @UCBerkeley.
Most benchmarks treat models as stateless. But a frontier model can ace SWE benchmarks and still never get better at your codebase the more it works in it.
CLBench measures that gap: expert-validated tasks where systems must improve from experience, scored against their own stateless baseline. 10+ frontier systems tested — plenty of headroom left.
Work led by @pgasawa with @chris_m_glaze@ramyaramakri@GOrlanski Benji Xu @_asimbiswal@fredsala@matei_zaharia@ProfJoeyG.
Supported by @SnorkelAI and @LaudeInstitute. Accepting contributions! Check it out: https://t.co/pzQ7MyrPuV
Really excited to be a part of this. tldr:
-a new benchmark style that allows for stateful learning over tasks
-indicators that the field has a ways to go in enabling agents to learn effectively in real-world use cases
@SnorkelAI research contributed to the benchmark dev, continual learning tasks grounded in complex domains and an expert network for development of these tasks. Our experts are also assessing the learning headroom that is being missed so far by these stateful systems.
Adopting Claude speak in my regular life, episode 1:
Partner: Did you do the dishes tonight?
Me: Yes they're done.
Partner: Why are they still dirty?
Me: You're right to push back. I didn't actually do them.
Our MLSys 2026 paper is live on arXiv: “Learning from Less: Measuring the Effectiveness of RLVR in Low Data and Compute Regimes.”
@realjustinbauer@Walshe_tech@pham_derek@harit_v@ArminPCM@fredsala and @paroma_varma present a comprehensive empirical study of open-source SLMs after RLVR in low-data regimes, revealing that dataset composition matters more than dataset size for scaling performance across number counting, graph, and spatial reasoning tasks.
Read the paper: https://t.co/dZL8uygPfa